VisLingInstruct: Elevating Zero-Shot Learning in Multi-Modal Language Models with Autonomous Instruction Optimization
2402.07398
0
0
💬
Abstract
This paper presents VisLingInstruct, a novel approach to advancing Multi-Modal Language Models (MMLMs) in zero-shot learning. Current MMLMs show impressive zero-shot abilities in multi-modal tasks, but their performance depends heavily on the quality of instructions. VisLingInstruct tackles this by autonomously evaluating and optimizing instructional texts through In-Context Learning, improving the synergy between visual perception and linguistic expression in MMLMs. Alongside this instructional advancement, we have also optimized the visual feature extraction modules in MMLMs, further augmenting their responsiveness to textual content. Our comprehensive experiments on MMLMs, based on FlanT5 and Vicuna, show that VisLingInstruct significantly improves zero-shot performance in visual multi-modal tasks. Notably, it achieves a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets. Our main code is available at https://github.com/Zhudongsheng75/VisLingInstruct.
Create account to get full access
Overview
- This paper presents VisLingInstruct, a novel approach to improving Multi-Modal Language Models (MMLMs) in zero-shot learning.
- Current MMLMs have impressive zero-shot abilities, but their performance heavily depends on the quality of instructions.
- VisLingInstruct addresses this by autonomously evaluating and optimizing instructional texts through In-Context Learning, enhancing the synergy between visual perception and linguistic expression.
- The paper also optimizes the visual feature extraction modules in MMLMs to further improve their responsiveness to textual content.
- Experiments on FlanT5 and Vicuna MMLMs show that VisLingInstruct significantly boosts zero-shot performance in visual multi-modal tasks, achieving up to 13.1% and 9% increases in accuracy on the TextVQA and HatefulMemes datasets.
Plain English Explanation
Multi-Modal Language Models (MMLMs) are AI systems that can understand and generate text and images together. They have become quite good at zero-shot learning, which means they can perform new tasks without being explicitly trained on them. However, the performance of MMLMs in these zero-shot tasks depends a lot on the quality of the instructions they are given.
The VisLingInstruct approach tackles this by automatically evaluating and improving the instructional texts used with MMLMs. It does this through a technique called In-Context Learning, which helps the models better understand the relationship between the visual information they see and the linguistic content they are given. This improves the overall synergy between the visual and language components of the MMLMs.
Additionally, the researchers have optimized the visual feature extraction modules within the MMLMs. This further enhances the models' ability to understand and respond to the textual content they are presented with.
When tested on popular benchmark datasets like TextVQA and HatefulMemes, MMLMs using the VisLingInstruct approach showed significant improvements in their zero-shot performance, with accuracy increases of up to 13.1% and 9% over previous state-of-the-art models.
Technical Explanation
The paper introduces VisLingInstruct, a novel technique for advancing Multi-Modal Language Models (MMLMs) in zero-shot learning scenarios. Current MMLMs, such as those based on FlanT5 and Vicuna, demonstrate impressive zero-shot capabilities in multi-modal tasks. However, their performance is heavily dependent on the quality of the instructions provided.
VisLingInstruct addresses this limitation by autonomously evaluating and optimizing the instructional texts used with MMLMs through In-Context Learning. This approach improves the synergy between the models' visual perception and linguistic expression, enhancing their overall zero-shot performance.
In addition to the instructional advancement, the researchers have also optimized the visual feature extraction modules within the MMLMs. This further augments the models' responsiveness to textual content, leading to improved multi-modal task understanding.
The researchers conducted comprehensive experiments on FlanT5 and Vicuna-based MMLMs, demonstrating that VisLingInstruct significantly boosts zero-shot performance in visual multi-modal tasks. Specifically, they achieved a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets, respectively.
Critical Analysis
The VisLingInstruct approach presents a promising solution to the challenge of instruction-dependent performance in zero-shot learning with MMLMs. By automating the optimization of instructional texts through In-Context Learning, the researchers have taken a meaningful step towards improving the synergy between visual perception and linguistic expression in these models.
However, the paper does not provide extensive details on the specific mechanisms and algorithms used for the autonomous evaluation and optimization of instructions. Further elaboration on these technical aspects would help the research community better understand and potentially replicate the approach.
Additionally, the experiments were limited to two MMLM architectures, FlanT5 and Vicuna. Expanding the evaluation to a broader range of models, including those from diverse research groups, would strengthen the generalizability of the findings and provide a more comprehensive understanding of the approach's effectiveness.
The paper also does not address potential biases or limitations that may arise from the VisLingInstruct approach. Investigating these aspects, as well as exploring the impact of the optimized visual feature extraction modules, would be valuable areas for further research.
Conclusion
The VisLingInstruct approach presented in this paper represents a significant advancement in improving the zero-shot learning capabilities of Multi-Modal Language Models. By autonomously optimizing instructional texts and enhancing the visual feature extraction modules, the researchers have demonstrated notable performance improvements on benchmark visual multi-modal tasks.
These findings have important implications for the development of more versatile and effective AI systems that can seamlessly integrate visual and linguistic information. As the field of multi-modal learning continues to evolve, techniques like VisLingInstruct may pave the way for MMLMs that can better understand and interact with the complex, multimodal world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MM-Instruct: Generated Visual Instructions for Large Multimodal Model Alignment
Jihao Liu, Xin Huang, Jinliang Zheng, Boxiao Liu, Jia Wang, Osamu Yoshie, Yu Liu, Hongsheng Li
0
0
This paper introduces MM-Instruct, a large-scale dataset of diverse and high-quality visual instruction data designed to enhance the instruction-following capabilities of large multimodal models (LMMs). While existing visual instruction datasets often focus on question-answering, they struggle to generalize to broader application scenarios such as creative writing, summarization, or image analysis. To address these limitations, we propose a novel approach to constructing MM-Instruct that leverages the strong instruction-following capabilities of existing LLMs to generate novel visual instruction data from large-scale but conventional image captioning datasets. MM-Instruct first leverages ChatGPT to automatically generate diverse instructions from a small set of seed instructions through augmenting and summarization. It then matches these instructions with images and uses an open-sourced large language model (LLM) to generate coherent answers to the instruction-image pairs. The LLM is grounded by the detailed text descriptions of images in the whole answer generation process to guarantee the alignment of the instruction data. Moreover, we introduce a benchmark based on the generated instruction data to evaluate the instruction-following capabilities of existing LMMs. We demonstrate the effectiveness of MM-Instruct by training a LLaVA-1.5 model on the generated data, denoted as LLaVA-Instruct, which exhibits significant improvements in instruction-following capabilities compared to LLaVA-1.5 models. The MM-Instruct dataset, benchmark, and pre-trained models are available at https://github.com/jihaonew/MM-Instruct.
7/1/2024
💬
MM-InstructEval: Zero-Shot Evaluation of (Multimodal) Large Language Models on Multimodal Reasoning Tasks
Xiaocui Yang, Wenfang Wu, Shi Feng, Ming Wang, Daling Wang, Yang Li, Qi Sun, Yifei Zhang, Xiaoming Fu, Soujanya Poria
0
0
The rising popularity of multimodal large language models (MLLMs) has sparked a significant increase in research dedicated to evaluating these models. However, current evaluation studies predominantly concentrate on the ability of models to comprehend and reason within a unimodal (vision-only) context, overlooking critical performance evaluations in complex multimodal reasoning tasks that integrate both visual and text contexts. Furthermore, tasks that demand reasoning across multiple modalities pose greater challenges and require a deep understanding of multimodal contexts. In this paper, we introduce a comprehensive assessment framework named MM-InstructEval, which integrates a diverse array of metrics to provide an extensive evaluation of the performance of various models and instructions across a broad range of multimodal reasoning tasks with vision-text contexts. MM-InstructEval enhances the research on the performance of MLLMs in complex multimodal reasoning tasks, facilitating a more thorough and holistic zero-shot evaluation of MLLMs. We firstly utilize the Best Performance metric to determine the upper performance limit of each model across various datasets. The Mean Relative Gain metric provides an analysis of the overall performance across different models and instructions, while the Stability metric evaluates their sensitivity to variations. Historically, the research has focused on evaluating models independently or solely assessing instructions, overlooking the interplay between models and instructions. To address this gap, we introduce the Adaptability metric, designed to quantify the degree of adaptability between models and instructions. Evaluations are conducted on 31 models (23 MLLMs) across 16 multimodal datasets, covering 6 tasks, with 10 distinct instructions. The extensive analysis enables us to derive novel insights.
5/14/2024

Text as Images: Can Multimodal Large Language Models Follow Printed Instructions in Pixels?
Xiujun Li, Yujie Lu, Zhe Gan, Jianfeng Gao, William Yang Wang, Yejin Choi
0
0
Recent multimodal large language models (MLLMs) have shown promising instruction following capabilities on vision-language tasks. In this work, we introduce VISUAL MODALITY INSTRUCTION (VIM), and investigate how well multimodal models can understand textual instructions provided in pixels, despite not being explicitly trained on such data during pretraining or fine-tuning. We adapt VIM to eight benchmarks, including OKVQA, MM-Vet, MathVista, MMMU, and probe diverse MLLMs in both the text-modality instruction (TEM) setting and VIM setting. Notably, we observe a significant performance disparity between the original TEM and VIM settings for open-source MLLMs, indicating that open-source MLLMs face greater challenges when text instruction is presented solely in image form. To address this issue, we train v-MLLM, a generalizable model that is capable to conduct robust instruction following in both text-modality and visual-modality instructions.
6/12/2024
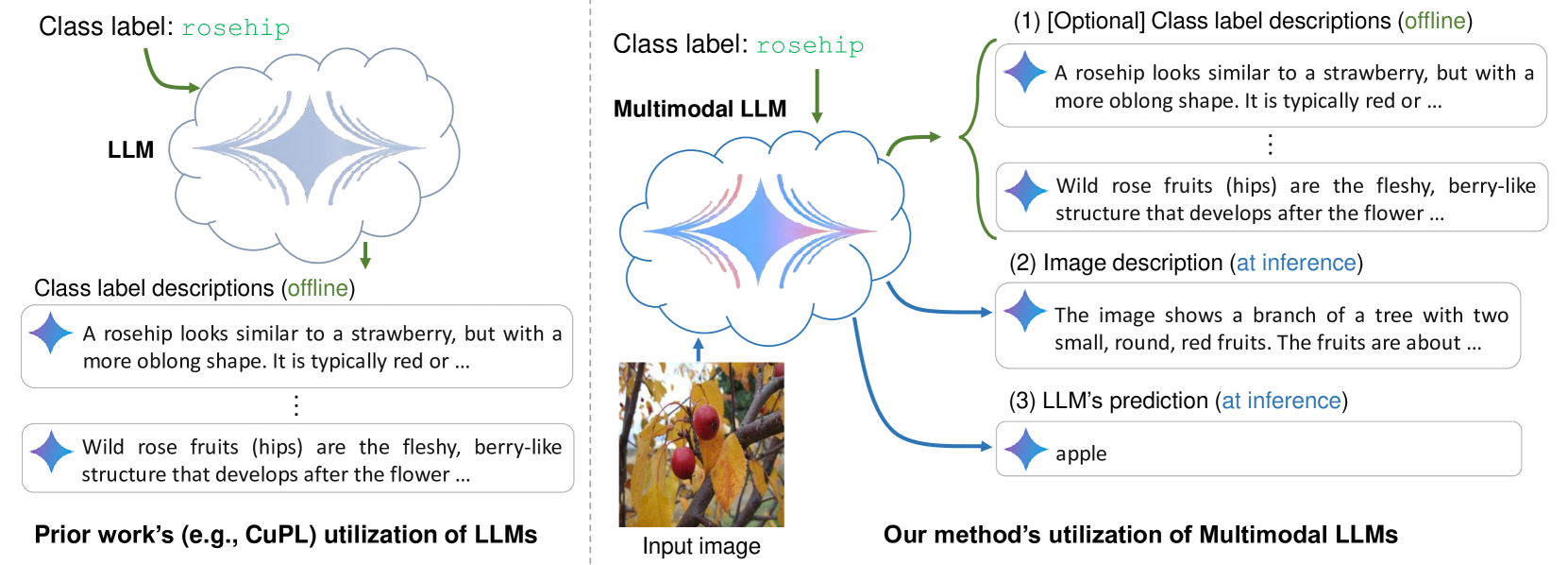
What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
Abdelrahman Abdelhamed, Mahmoud Afifi, Alec Go
0
0
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
5/27/2024