What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models
2405.15668
0
0
Abstract
Large language models (LLMs) has been effectively used for many computer vision tasks, including image classification. In this paper, we present a simple yet effective approach for zero-shot image classification using multimodal LLMs. By employing multimodal LLMs, we generate comprehensive textual representations from input images. These textual representations are then utilized to generate fixed-dimensional features in a cross-modal embedding space. Subsequently, these features are fused together to perform zero-shot classification using a linear classifier. Our method does not require prompt engineering for each dataset; instead, we use a single, straightforward, set of prompts across all datasets. We evaluated our method on several datasets, and our results demonstrate its remarkable effectiveness, surpassing benchmark accuracy on multiple datasets. On average over ten benchmarks, our method achieved an accuracy gain of 4.1 percentage points, with an increase of 6.8 percentage points on the ImageNet dataset, compared to prior methods. Our findings highlight the potential of multimodal LLMs to enhance computer vision tasks such as zero-shot image classification, offering a significant improvement over traditional methods.
Create account to get full access
Overview
• This paper explores using multimodal large language models (LLMs) to enhance zero-shot image classification, where models can classify images they haven't seen before.
• The researchers developed a method called ZEST (Zero-Shot Transformer) that uses a multimodal LLM to generate visual features from text descriptions, which are then used to classify images.
• The paper shows that ZEST outperforms previous zero-shot approaches and can even match the performance of fully supervised models on some datasets.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. These models have also shown promise in working with images, a capability known as "multimodal" learning.
In this paper, the researchers explore how multimodal LLMs can be used to improve a technique called "zero-shot" image classification. Zero-shot classification allows models to identify objects in images they've never seen before, based on text descriptions. For example, if a model has never seen a "quokka" before, it could still identify one in an image if it understands the textual description.
The researchers developed a method called ZEST (Zero-Shot Transformer) that uses a multimodal LLM to generate visual features from text descriptions. These visual features are then used to classify images, even if the model hasn't seen those specific images before.
The key advantage of ZEST is that it can achieve strong zero-shot performance, sometimes even matching the accuracy of fully supervised models that have been trained on lots of labeled images. This is an important capability, as it means models can recognize new objects without needing to be retrained on massive image datasets.
Technical Explanation
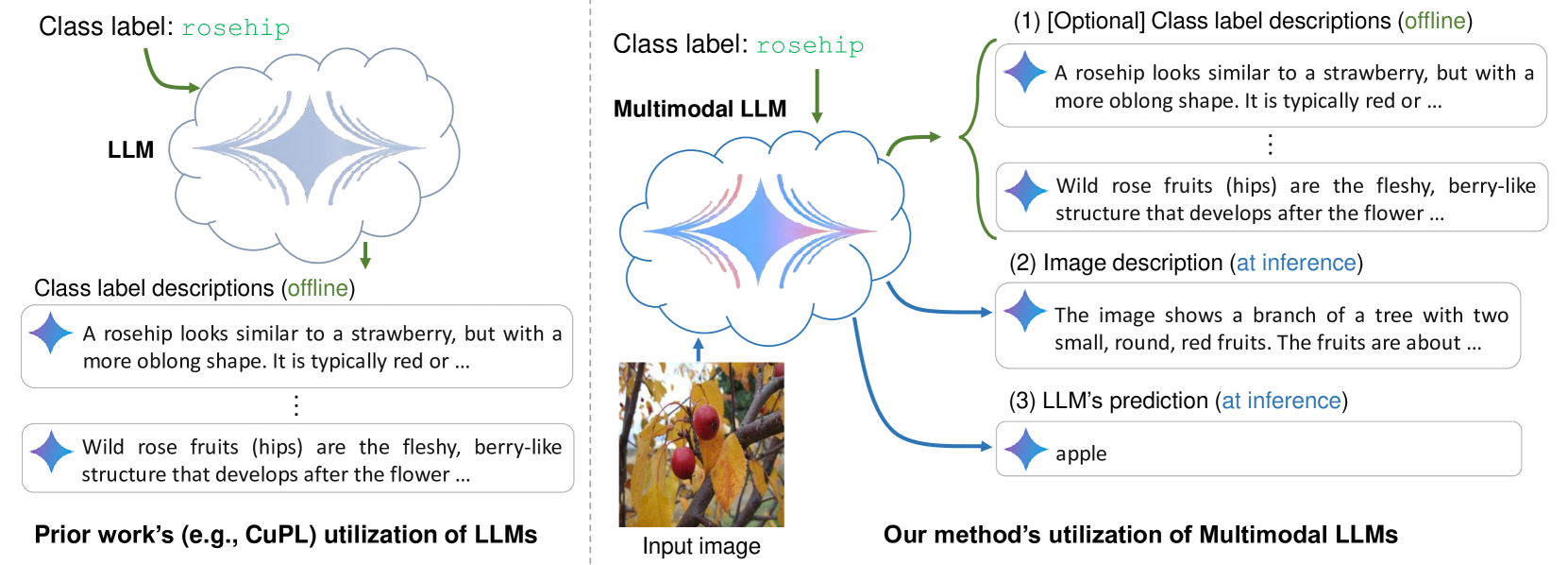
The paper introduces a new approach called ZEST (Zero-Shot Transformer) that leverages multimodal large language models (LLMs) to enhance zero-shot image classification. Zero-shot classification allows models to recognize objects they haven't seen before, based on textual descriptions.
ZEST works by using a multimodal LLM to generate visual features from text descriptions of classes. These generated visual features are then used as input to a simple linear classifier to predict the class of a given image, without any direct image training. The researchers show that this approach can outperform previous zero-shot methods and even match the performance of fully supervised models on some benchmarks.
The key innovation is the use of a multimodal LLM, which has been pretrained on large-scale image-text data (as discussed in this review). These models are able to learn rich cross-modal representations that can be effectively leveraged for zero-shot transfer. The paper also explores different techniques for prompting the LLM to generate high-quality visual features.
Overall, the ZEST method demonstrates the potential of multimodal LLMs to enhance zero-shot recognition and generalization capabilities, reducing the need for large labeled image datasets.
Critical Analysis
The paper provides a compelling demonstration of how multimodal large language models can be used to improve zero-shot image classification. The ZEST approach is elegant in its simplicity, leveraging the rich cross-modal representations learned by these LLMs to generate visual features that work well for classification.
However, the paper also acknowledges several limitations and avenues for future work. For instance, the current ZEST method relies on manual prompting to guide the LLM in generating useful visual features. Automated prompt engineering or other techniques to better adapt the LLM to the zero-shot task could further boost performance.
Additionally, the paper only evaluates ZEST on a limited set of image classification benchmarks. It would be valuable to see how the approach scales to more diverse and challenging datasets, as well as whether it generalizes to other zero-shot computer vision tasks beyond just classification.
Overall, the ZEST method represents an exciting development in leveraging the power of multimodal LLMs for enhanced zero-shot capabilities. As these large models continue to evolve, we can expect to see further innovations in zero-shot and few-shot learning that reduce the need for costly labeled data.
Conclusion
This paper introduces a novel approach called ZEST (Zero-Shot Transformer) that uses multimodal large language models to significantly improve zero-shot image classification. By generating visual features from text descriptions, ZEST can match or exceed the performance of fully supervised models on certain benchmarks, without requiring any direct image training.
The key insight is the ability of these multimodal LLMs to learn rich cross-modal representations that can be effectively transferred to zero-shot tasks. While the current ZEST method has some limitations, it demonstrates the immense potential of leveraging large language models for enhanced generalization and reduced reliance on labeled data.
As the field of multimodal AI continues to advance, we can expect to see even more powerful zero-shot and few-shot learning capabilities emerge - unlocking new applications and expanding the reach of AI systems. This paper provides an important step forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Zhaoheng Zheng, Jingmin Wei, Xuefeng Hu, Haidong Zhu, Ram Nevatia
0
0
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
4/4/2024
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
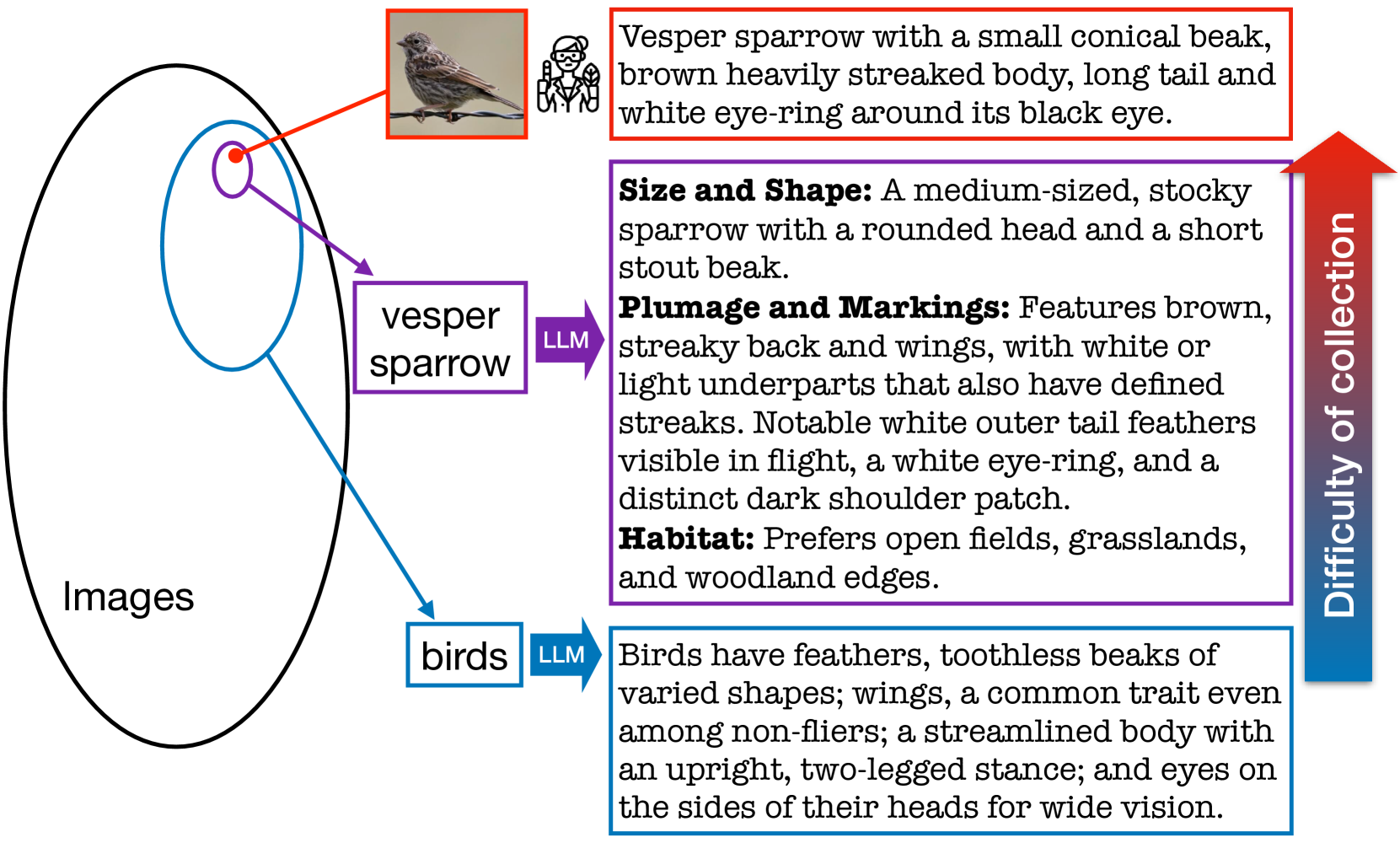
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024

Exploiting LMM-based knowledge for image classification tasks
Maria Tzelepi, Vasileios Mezaris
0
0
In this paper we address image classification tasks leveraging knowledge encoded in Large Multimodal Models (LMMs). More specifically, we use the MiniGPT-4 model to extract semantic descriptions for the images, in a multimodal prompting fashion. In the current literature, vision language models such as CLIP, among other approaches, are utilized as feature extractors, using only the image encoder, for solving image classification tasks. In this paper, we propose to additionally use the text encoder to obtain the text embeddings corresponding to the MiniGPT-4-generated semantic descriptions. Thus, we use both the image and text embeddings for solving the image classification task. The experimental evaluation on three datasets validates the improved classification performance achieved by exploiting LMM-based knowledge.
6/6/2024
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024