Visual Context-Aware Person Fall Detection
2404.08088
0
0

Abstract
As the global population ages, the number of fall-related incidents is on the rise. Effective fall detection systems, specifically in healthcare sector, are crucial to mitigate the risks associated with such events. This study evaluates the role of visual context, including background objects, on the accuracy of fall detection classifiers. We present a segmentation pipeline to semi-automatically separate individuals and objects in images. Well-established models like ResNet-18, EfficientNetV2-S, and Swin-Small are trained and evaluated. During training, pixel-based transformations are applied to segmented objects, and the models are then evaluated on raw images without segmentation. Our findings highlight the significant influence of visual context on fall detection. The application of Gaussian blur to the image background notably improves the performance and generalization capabilities of all models. Background objects such as beds, chairs, or wheelchairs can challenge fall detection systems, leading to false positive alarms. However, we demonstrate that object-specific contextual transformations during training effectively mitigate this challenge. Further analysis using saliency maps supports our observation that visual context is crucial in classification tasks. We create both dataset processing API and segmentation pipeline, available at https://github.com/A-NGJ/image-segmentation-cli.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach for detecting and classifying person falls using visual context information.
- The proposed system combines person detection and fall detection models to enhance fall recognition accuracy by leveraging contextual cues from the surrounding environment.
- Key contributions include a new dataset for evaluating visual context-aware fall detection and extensive experiments demonstrating the benefits of incorporating scene context.
Plain English Explanation
The researchers developed a system to automatically detect and classify when a person falls, such as in a home or care facility. Rather than just analyzing the person's movements, their approach also takes into account the visual "context" or surrounding environment. By considering details about the scene, like furniture, walls, and floor, the system can more accurately identify when a person has truly fallen compared to other movements.
The researchers created a new dataset to test their method, which includes video footage of people falling in different indoor settings. Through extensive experiments, they show that incorporating visual context information significantly improves the accuracy of fall detection compared to approaches that only look at the person.
This research could have important applications for improving safety monitoring and fall prevention, especially for elderly or vulnerable populations who may be at higher risk of falls. By leveraging the visual environment, the system can provide more reliable fall alerts and potentially help caregivers respond more quickly to dangerous situations.
Technical Explanation
The paper proposes a visual context-aware person fall detection system that combines person detection and fall classification models. The key innovation is the use of scene context information to enhance fall recognition accuracy.
The system first detects persons in the video frame using an object detection network. It then extracts visual features from the surrounding scene context using a separate convolutional neural network. These contextual features are combined with the person's appearance and motion features to classify whether a fall has occurred.
The researchers created a new benchmark dataset called VCPF specifically for evaluating visual context-aware fall detection. Extensive experiments on this dataset demonstrate that incorporating scene context significantly outperforms person-centric fall detection approaches.
Critical Analysis
The paper provides a thorough evaluation of the proposed visual context-aware fall detection system, including comparisons to several baseline approaches. However, it does not extensively discuss potential limitations or areas for future work.
One limitation is that the system requires a person to be explicitly detected in the video frame before fall classification can occur. This could be problematic in situations where occlusions or camera angles make it difficult to reliably segment individuals.
Additionally, the experiments are conducted on a controlled dataset with relatively simple indoor scenes. It is unclear how well the system would generalize to more complex, real-world environments with diverse furniture, lighting, and camera viewpoints. Further research may be needed to assess the robustness of the approach in less constrained settings.
Conclusion
This paper presents a novel visual context-aware approach for improving the accuracy of person fall detection. By leveraging information about the surrounding scene, the proposed system can more reliably distinguish falls from other human movements. The new VCPF dataset and extensive experimental results demonstrate the benefits of incorporating contextual cues.
This research has important implications for developing more robust and reliable fall monitoring systems, which could significantly enhance safety and care for elderly or disabled individuals. However, further work is needed to assess the approach's generalization to diverse real-world environments. Overall, the paper makes a valuable contribution to the field of computer vision and assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Contextual Encoder-Decoder Network for Visual Saliency Prediction
Alexander Kroner, Mario Senden, Kurt Driessens, Rainer Goebel
0
0
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive and consistent results across multiple evaluation metrics on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on five datasets and selected examples. Compared to state of the art approaches, the network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources, such as (virtual) robotic systems, to estimate human fixations across complex natural scenes.
4/8/2024
🤔
Understanding and Modeling the Effects of Task and Context on Drivers' Gaze Allocation
Iuliia Kotseruba, John K. Tsotsos
0
0
To further advance driver monitoring and assistance systems, it is important to understand how drivers allocate their attention, in other words, where do they tend to look and why. Traditionally, factors affecting human visual attention have been divided into bottom-up (involuntary attraction to salient regions) and top-down (driven by the demands of the task being performed). Although both play a role in directing drivers' gaze, most of the existing models for drivers' gaze prediction apply techniques developed for bottom-up saliency and do not consider influences of the drivers' actions explicitly. Likewise, common driving attention benchmarks lack relevant annotations for drivers' actions and the context in which they are performed. Therefore, to enable analysis and modeling of these factors for drivers' gaze prediction, we propose the following: 1) we correct the data processing pipeline used in DR(eye)VE to reduce noise in the recorded gaze data; 2) we then add per-frame labels for driving task and context; 3) we benchmark a number of baseline and SOTA models for saliency and driver gaze prediction and use new annotations to analyze how their performance changes in scenarios involving different tasks; and, lastly, 4) we develop a novel model that modulates drivers' gaze prediction with explicit action and context information. While reducing noise in the DR(eye)VE gaze data improves results of all models, we show that using task information in our proposed model boosts performance even further compared to bottom-up models on the cleaned up data, both overall (by 24% KLD and 89% NSS) and on scenarios that involve performing safety-critical maneuvers and crossing intersections (by up to 10--30% KLD). Extended annotations and code are available at https://github.com/ykotseruba/SCOUT.
4/16/2024
🔎
ContextualFusion: Context-Based Multi-Sensor Fusion for 3D Object Detection in Adverse Operating Conditions
Shounak Sural (Raj), Nishad Sahu (Raj), Ragunathan (Raj), Rajkumar
0
0
The fusion of multimodal sensor data streams such as camera images and lidar point clouds plays an important role in the operation of autonomous vehicles (AVs). Robust perception across a range of adverse weather and lighting conditions is specifically required for AVs to be deployed widely. While multi-sensor fusion networks have been previously developed for perception in sunny and clear weather conditions, these methods show a significant degradation in performance under night-time and poor weather conditions. In this paper, we propose a simple yet effective technique called ContextualFusion to incorporate the domain knowledge about cameras and lidars behaving differently across lighting and weather variations into 3D object detection models. Specifically, we design a Gated Convolutional Fusion (GatedConv) approach for the fusion of sensor streams based on the operational context. To aid in our evaluation, we use the open-source simulator CARLA to create a multimodal adverse-condition dataset called AdverseOp3D to address the shortcomings of existing datasets being biased towards daytime and good-weather conditions. Our ContextualFusion approach yields an mAP improvement of 6.2% over state-of-the-art methods on our context-balanced synthetic dataset. Finally, our method enhances state-of-the-art 3D objection performance at night on the real-world NuScenes dataset with a significant mAP improvement of 11.7%.
4/24/2024
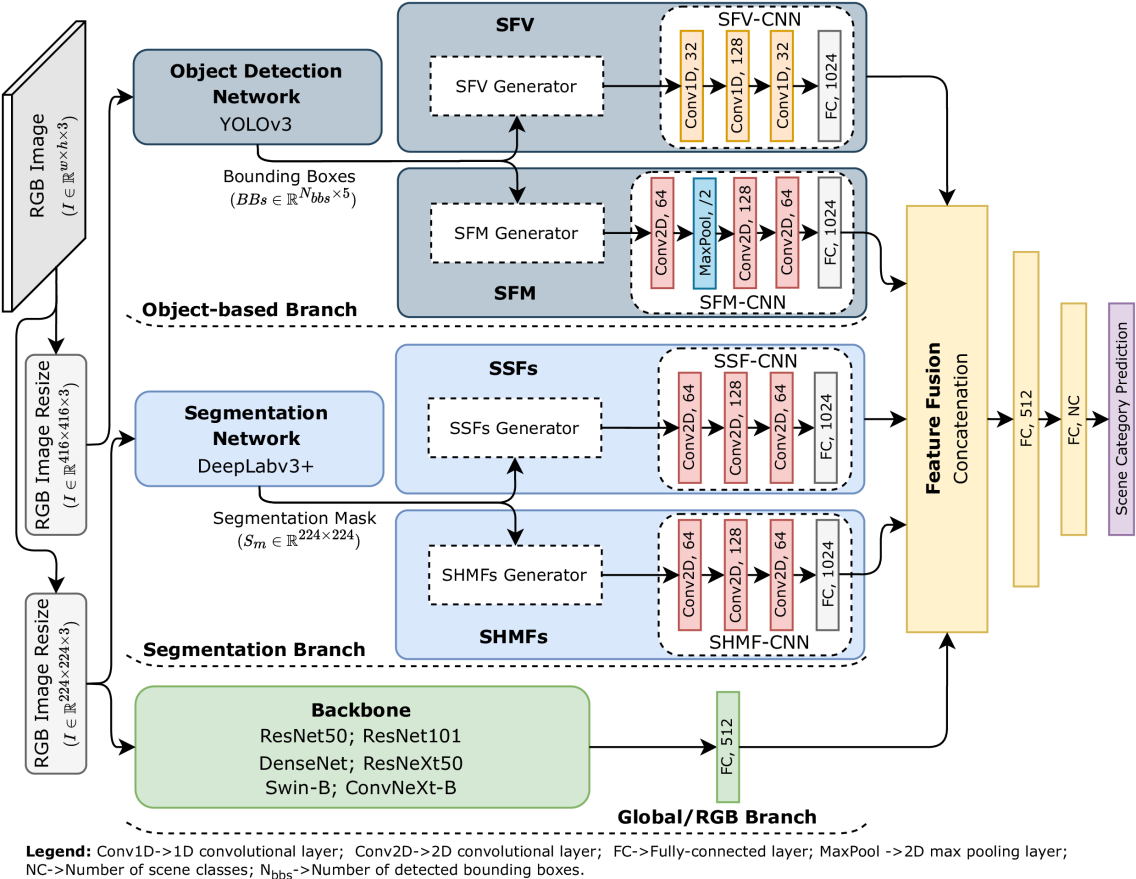
Exploiting Object-based and Segmentation-based Semantic Features for Deep Learning-based Indoor Scene Classification
Ricardo Pereira, Lu'is Garrote, Tiago Barros, Ana Lopes, Urbano J. Nunes
0
0
Indoor scenes are usually characterized by scattered objects and their relationships, which turns the indoor scene classification task into a challenging computer vision task. Despite the significant performance boost in classification tasks achieved in recent years, provided by the use of deep-learning-based methods, limitations such as inter-category ambiguity and intra-category variation have been holding back their performance. To overcome such issues, gathering semantic information has been shown to be a promising source of information towards a more complete and discriminative feature representation of indoor scenes. Therefore, the work described in this paper uses both semantic information, obtained from object detection, and semantic segmentation techniques. While object detection techniques provide the 2D location of objects allowing to obtain spatial distributions between objects, semantic segmentation techniques provide pixel-level information that allows to obtain, at a pixel-level, a spatial distribution and shape-related features of the segmentation categories. Hence, a novel approach that uses a semantic segmentation mask to provide Hu-moments-based segmentation categories' shape characterization, designated by Segmentation-based Hu-Moments Features (SHMFs), is proposed. Moreover, a three-main-branch network, designated by GOS$^2$F$^2$App, that exploits deep-learning-based global features, object-based features, and semantic segmentation-based features is also proposed. GOS$^2$F$^2$App was evaluated in two indoor scene benchmark datasets: SUN RGB-D and NYU Depth V2, where, to the best of our knowledge, state-of-the-art results were achieved on both datasets, which present evidences of the effectiveness of the proposed approach.
4/12/2024