Integrating Language-Derived Appearance Elements with Visual Cues in Pedestrian Detection

0
🔎
Sign in to get full access
This paper introduces a novel approach that leverages large language models (LLMs) to improve pedestrian detection by incorporating contextual appearance knowledge. Pedestrian detection is a critical task for safety applications like intelligent driving systems, but it remains challenging due to the diverse appearances and poses of pedestrians in various scenes.
The proposed method involves creating a description corpus containing narratives describing the appearances of pedestrians and other instances. These narratives are fed through an LLM to extract appearance knowledge sets that represent appearance variations. A task-prompting process is then performed to obtain appearance elements, which are guided representative appearance knowledge relevant to the pedestrian detection task.
The obtained knowledge elements can be integrated with visual cues within various detection frameworks, providing valuable appearance information to the detector. Comprehensive experiments on two public pedestrian detection benchmarks, CrowdHuman and WiderPedestrian, demonstrate the adaptability and effectiveness of this method, resulting in noticeable performance gains and state-of-the-art detection performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Integrating Language-Derived Appearance Elements with Visual Cues in Pedestrian Detection
Sungjune Park, Hyunjun Kim, Yong Man Ro
Large language models (LLMs) have shown their capabilities in understanding contextual and semantic information regarding knowledge of instance appearances. In this paper, we introduce a novel approach to utilize the strengths of LLMs in understanding contextual appearance variations and to leverage this knowledge into a vision model (here, pedestrian detection). While pedestrian detection is considered one of the crucial tasks directly related to our safety (e.g., intelligent driving systems), it is challenging because of varying appearances and poses in diverse scenes. Therefore, we propose to formulate language-derived appearance elements and incorporate them with visual cues in pedestrian detection. To this end, we establish a description corpus that includes numerous narratives describing various appearances of pedestrians and other instances. By feeding them through an LLM, we extract appearance knowledge sets that contain the representations of appearance variations. Subsequently, we perform a task-prompting process to obtain appearance elements which are guided representative appearance knowledge relevant to a downstream pedestrian detection task. The obtained knowledge elements are adaptable to various detection frameworks, so that we can provide plentiful appearance information by integrating the language-derived appearance elements with visual cues within a detector. Through comprehensive experiments with various pedestrian detectors, we verify the adaptability and effectiveness of our method showing noticeable performance gains and achieving state-of-the-art detection performance on two public pedestrian detection benchmarks (i.e., CrowdHuman and WiderPedestrian).
Read more5/1/2024
🔎
0
Robust Pedestrian Detection via Constructing Versatile Pedestrian Knowledge Bank
Sungjune Park, Hyunjun Kim, Yong Man Ro
Pedestrian detection is a crucial field of computer vision research which can be adopted in various real-world applications (e.g., self-driving systems). However, despite noticeable evolution of pedestrian detection, pedestrian representations learned within a detection framework are usually limited to particular scene data in which they were trained. Therefore, in this paper, we propose a novel approach to construct versatile pedestrian knowledge bank containing representative pedestrian knowledge which can be applicable to various detection frameworks and adopted in diverse scenes. We extract generalized pedestrian knowledge from a large-scale pretrained model, and we curate them by quantizing most representative features and guiding them to be distinguishable from background scenes. Finally, we construct versatile pedestrian knowledge bank which is composed of such representations, and then we leverage it to complement and enhance pedestrian features within a pedestrian detection framework. Through comprehensive experiments, we validate the effectiveness of our method, demonstrating its versatility and outperforming state-of-the-art detection performances.
Read more5/1/2024

0
Leveraging LLMs for Enhanced Open-Vocabulary 3D Scene Understanding in Autonomous Driving
Amirhosein Chahe, Lifeng Zhou
This paper introduces a novel method for open-vocabulary 3D scene understanding in autonomous driving by combining Language Embedded 3D Gaussians with Large Language Models (LLMs) for enhanced inference. We propose utilizing LLMs to generate contextually relevant canonical phrases for segmentation and scene interpretation. Our method leverages the contextual and semantic capabilities of LLMs to produce a set of canonical phrases, which are then compared with the language features embedded in the 3D Gaussians. This LLM-guided approach significantly improves zero-shot scene understanding and detection of objects of interest, even in the most challenging or unfamiliar environments. Experimental results on the WayveScenes101 dataset demonstrate that our approach surpasses state-of-the-art methods in terms of accuracy and flexibility for open-vocabulary object detection and segmentation. This work represents a significant advancement towards more intelligent, context-aware autonomous driving systems, effectively bridging 3D scene representation with high-level semantic understanding.
Read more8/9/2024
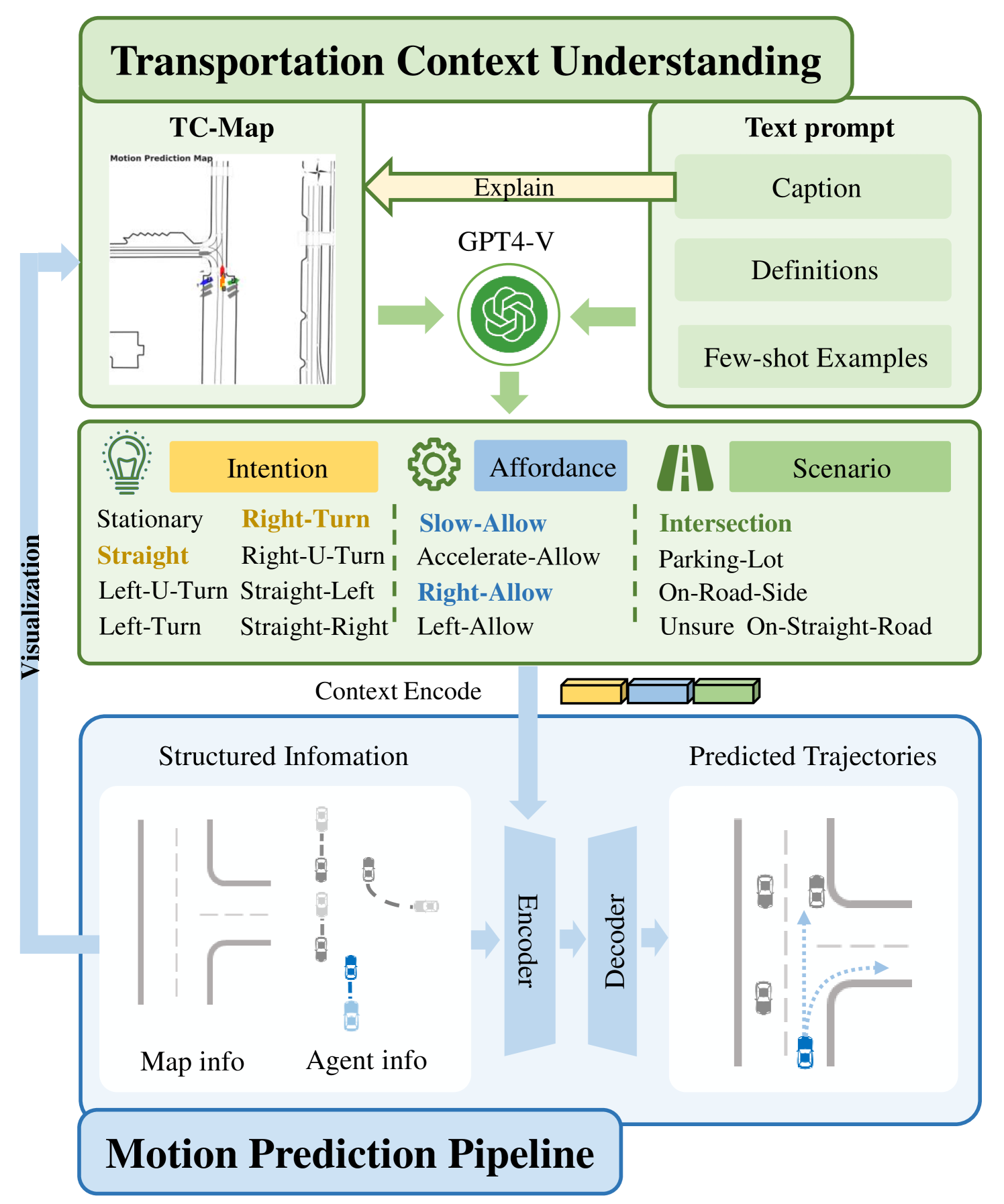
0
Large Language Models Powered Context-aware Motion Prediction
Xiaoji Zheng, Lixiu Wu, Zhijie Yan, Yuanrong Tang, Hao Zhao, Chen Zhong, Bokui Chen, Jiangtao Gong
Motion prediction is among the most fundamental tasks in autonomous driving. Traditional methods of motion forecasting primarily encode vector information of maps and historical trajectory data of traffic participants, lacking a comprehensive understanding of overall traffic semantics, which in turn affects the performance of prediction tasks. In this paper, we utilized Large Language Models (LLMs) to enhance the global traffic context understanding for motion prediction tasks. We first conducted systematic prompt engineering, visualizing complex traffic environments and historical trajectory information of traffic participants into image prompts -- Transportation Context Map (TC-Map), accompanied by corresponding text prompts. Through this approach, we obtained rich traffic context information from the LLM. By integrating this information into the motion prediction model, we demonstrate that such context can enhance the accuracy of motion predictions. Furthermore, considering the cost associated with LLMs, we propose a cost-effective deployment strategy: enhancing the accuracy of motion prediction tasks at scale with 0.7% LLM-augmented datasets. Our research offers valuable insights into enhancing the understanding of traffic scenes of LLMs and the motion prediction performance of autonomous driving. The source code is available at url{https://github.com/AIR-DISCOVER/LLM-Augmented-MTR} and url{https://aistudio.baidu.com/projectdetail/7809548}.
Read more7/31/2024