Visual Representation Learning with Stochastic Frame Prediction
2406.07398
0
0
Abstract
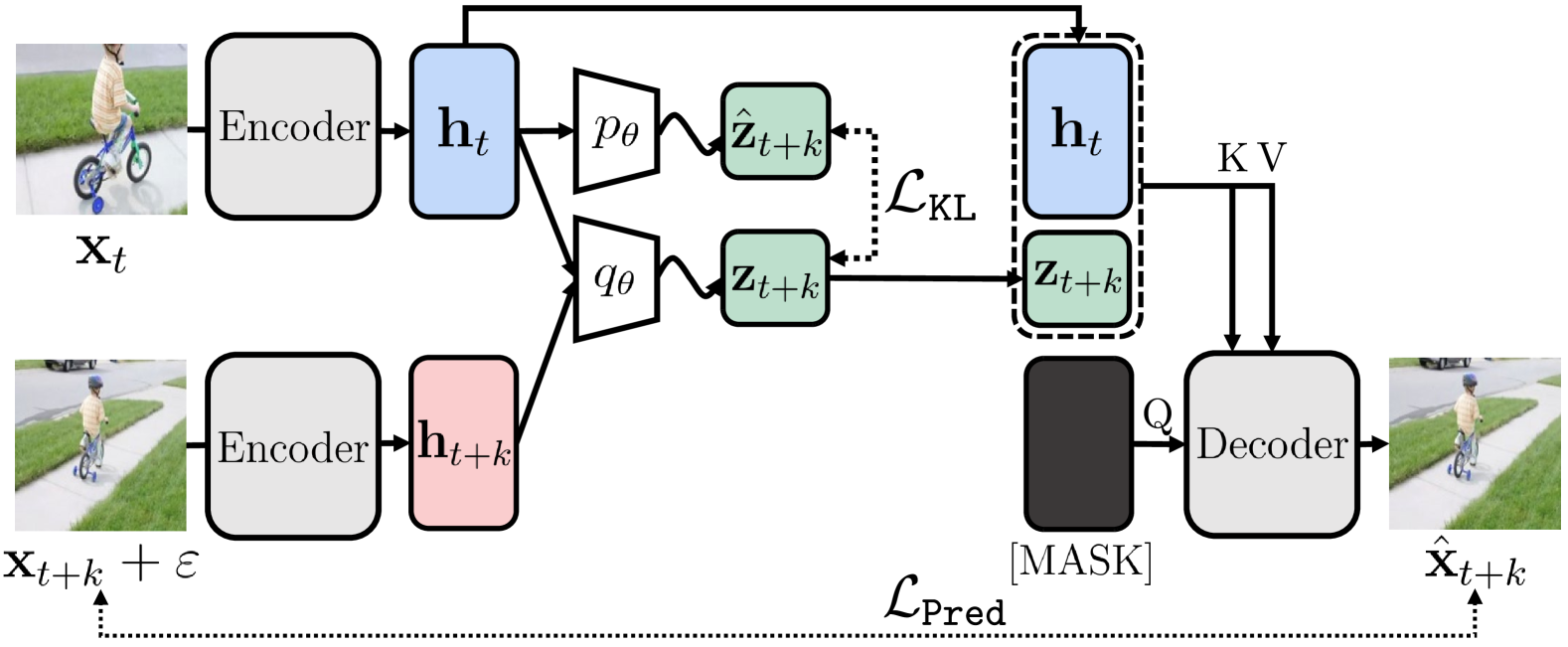
Self-supervised learning of image representations by predicting future frames is a promising direction but still remains a challenge. This is because of the under-determined nature of frame prediction; multiple potential futures can arise from a single current frame. To tackle this challenge, in this paper, we revisit the idea of stochastic video generation that learns to capture uncertainty in frame prediction and explore its effectiveness for representation learning. Specifically, we design a framework that trains a stochastic frame prediction model to learn temporal information between frames. Moreover, to learn dense information within each frame, we introduce an auxiliary masked image modeling objective along with a shared decoder architecture. We find this architecture allows for combining both objectives in a synergistic and compute-efficient manner. We demonstrate the effectiveness of our framework on a variety of tasks from video label propagation and vision-based robot learning domains, such as video segmentation, pose tracking, vision-based robotic locomotion, and manipulation tasks. Code is available on the project webpage: https://sites.google.com/view/2024rsp.
Create account to get full access
Overview
- This paper introduces a novel visual representation learning approach called Stochastic Frame Prediction (SFP), which leverages the predictability of video frames to learn robust visual representations.
- SFP trains an autoregressive model to predict future video frames, capturing both deterministic and stochastic aspects of the video sequence.
- The authors show that SFP outperforms existing self-supervised video representation learning methods on downstream tasks like action recognition and video prediction.
Plain English Explanation
The paper presents a new way to learn useful visual representations from videos, called Stochastic Frame Prediction (SFP). The key idea is to train a model that can predict what the next frame in a video will look like, both the parts that are easy to predict (like a person walking) and the parts that are more random (like a person suddenly turning their head).
By training the model to predict the future frames, it has to learn meaningful representations of the objects, motions, and patterns in the video. These learned representations can then be used for other tasks, like recognizing actions in the video or generating new video sequences.
The authors show that their SFP approach outperforms other methods for learning visual representations from videos, resulting in models that perform better on tasks like action recognition. The ability to capture both the predictable and unpredictable aspects of the video seems to be the key to learning more robust and useful visual representations.
Technical Explanation
The paper introduces a novel self-supervised learning approach called Stochastic Frame Prediction (SFP), which learns visual representations by predicting future video frames. Unlike previous methods that focus only on the predictable aspects of videos, SFP explicitly models both the deterministic and stochastic components of the video sequence.
The authors design an autoregressive model that takes in the current video frame and predicts the next frame. This model is trained to minimize the reconstruction loss between the predicted and actual next frames. Crucially, the authors decompose the frame prediction into a deterministic component, which captures the predictable aspects of the video, and a stochastic component, which models the random or unpredictable aspects.
By learning to predict future frames in this way, the SFP model is forced to build visual representations that capture the underlying structure and dynamics of the video data. The authors demonstrate that these learned representations outperform those from other self-supervised video representation learning methods, such as feature prediction and spatiotemporal predictive pretraining, on downstream tasks like action recognition and video prediction.
Critical Analysis
The paper makes a compelling case for the effectiveness of the Stochastic Frame Prediction (SFP) approach in learning rich visual representations from video data. By explicitly modeling both the predictable and unpredictable aspects of video sequences, the SFP model is able to capture a more comprehensive understanding of the underlying video dynamics.
One potential limitation of the SFP approach is that it may struggle with long-term video prediction, as the stochastic component could become increasingly difficult to model over longer time horizons. The authors acknowledge this in the paper and suggest that incorporating additional mechanisms, such as hierarchical or attention-based models, could help address this challenge.
Another area for further research could be exploring the interpretability of the learned representations from the SFP model. Understanding how the model represents and reasons about the deterministic and stochastic components of the video could provide valuable insights into the nature of visual perception and the structure of the video data.
Additionally, the authors could investigate the transferability of the SFP representations to a wider range of downstream tasks, beyond the ones explored in the current paper. Demonstrating the versatility and generalization capabilities of the learned representations would further strengthen the case for this approach.
Conclusion
The Stochastic Frame Prediction (SFP) method presented in this paper offers a novel and effective approach to learning visual representations from video data. By explicitly modeling both the predictable and unpredictable aspects of video sequences, SFP is able to capture a richer understanding of the underlying video dynamics, leading to representations that outperform those from other self-supervised video learning methods.
The work has the potential to significantly advance the field of self-supervised visual representation learning, with applications in areas such as action recognition, video prediction, and robotic control. Further research on addressing long-term prediction challenges, understanding the learned representations, and exploring broader applications could further solidify the impact of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ARVideo: Autoregressive Pretraining for Self-Supervised Video Representation Learning
Sucheng Ren, Hongru Zhu, Chen Wei, Yijiang Li, Alan Yuille, Cihang Xie
0
0
This paper presents a new self-supervised video representation learning framework, ARVideo, which autoregressively predicts the next video token in a tailored sequence order. Two key designs are included. First, we organize autoregressive video tokens into clusters that span both spatially and temporally, thereby enabling a richer aggregation of contextual information compared to the standard spatial-only or temporal-only clusters. Second, we adopt a randomized spatiotemporal prediction order to facilitate learning from multi-dimensional data, addressing the limitations of a handcrafted spatial-first or temporal-first sequence order. Extensive experiments establish ARVideo as an effective paradigm for self-supervised video representation learning. For example, when trained with the ViT-B backbone, ARVideo competitively attains 81.2% on Kinetics-400 and 70.9% on Something-Something V2, which are on par with the strong benchmark set by VideoMAE. Importantly, ARVideo also demonstrates higher training efficiency, i.e., it trains 14% faster and requires 58% less GPU memory compared to VideoMAE.
5/27/2024

Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, Nicolas Ballas
0
0
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
4/15/2024
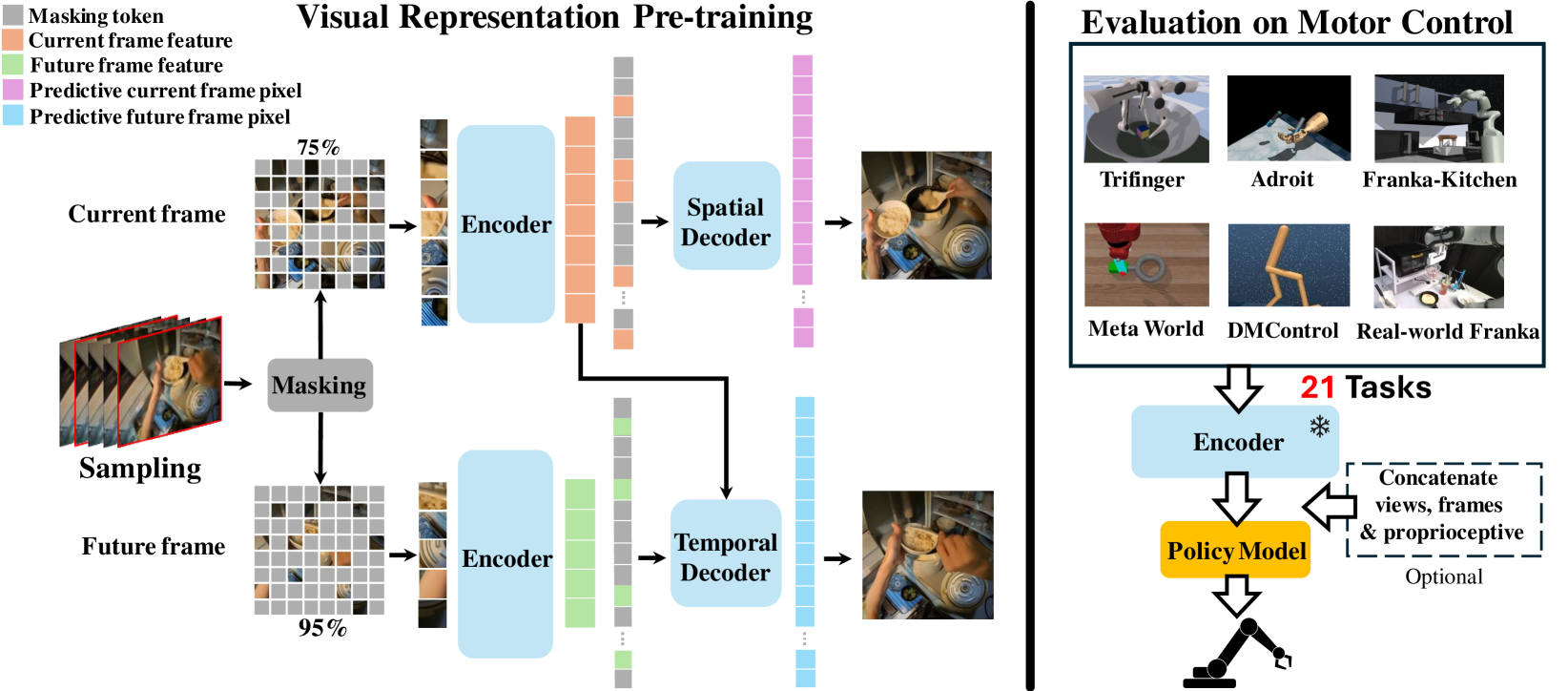
Spatiotemporal Predictive Pre-training for Robotic Motor Control
Jiange Yang, Bei Liu, Jianlong Fu, Bocheng Pan, Gangshan Wu, Limin Wang
0
0
Robotic motor control necessitates the ability to predict the dynamics of environments and interaction objects. However, advanced self-supervised pre-trained visual representations (PVRs) in robotic motor control, leveraging large-scale egocentric videos, often focus solely on learning the static content features of sampled image frames. This neglects the crucial temporal motion clues in human video data, which implicitly contain key knowledge about sequential interacting and manipulating with the environments and objects. In this paper, we present a simple yet effective robotic motor control visual pre-training framework that jointly performs spatiotemporal prediction with dual decoders, utilizing large-scale video data, termed as textbf{STP}. STP adheres to two key designs in a multi-task learning manner. First, we perform spatial prediction on the masked current frame for learning content features. Second, we utilize the future frame with an extremely high masking ratio as a condition, based on the masked current frame, to conduct temporal prediction of future frame for capturing motion features. This asymmetric masking and decoder architecture design is very efficient, ensuring that our representation focusing on motion information while capturing spatial details. We carry out the largest-scale BC evaluation of PVRs for robotic motor control to date, which encompasses 21 tasks within a real-world Franka robot arm and 5 simulated environments. Extensive experiments demonstrate the effectiveness of STP as well as unleash its generality and data efficiency by further post-pre-training and hybrid pre-training. Our code and weights will be released for further applications.
5/28/2024
🤯
From latent dynamics to meaningful representations
Dedi Wang, Yihang Wang, Luke Evans, Pratyush Tiwary
0
0
While representation learning has been central to the rise of machine learning and artificial intelligence, a key problem remains in making the learned representations meaningful. For this, the typical approach is to regularize the learned representation through prior probability distributions. However, such priors are usually unavailable or are ad hoc. To deal with this, recent efforts have shifted towards leveraging the insights from physical principles to guide the learning process. In this spirit, we propose a purely dynamics-constrained representation learning framework. Instead of relying on predefined probabilities, we restrict the latent representation to follow overdamped Langevin dynamics with a learnable transition density - a prior driven by statistical mechanics. We show this is a more natural constraint for representation learning in stochastic dynamical systems, with the crucial ability to uniquely identify the ground truth representation. We validate our framework for different systems including a real-world fluorescent DNA movie dataset. We show that our algorithm can uniquely identify orthogonal, isometric and meaningful latent representations.
4/11/2024