Revisiting Feature Prediction for Learning Visual Representations from Video
2404.08471
0
0

Abstract
This paper explores feature prediction as a stand-alone objective for unsupervised learning from video and introduces V-JEPA, a collection of vision models trained solely using a feature prediction objective, without the use of pretrained image encoders, text, negative examples, reconstruction, or other sources of supervision. The models are trained on 2 million videos collected from public datasets and are evaluated on downstream image and video tasks. Our results show that learning by predicting video features leads to versatile visual representations that perform well on both motion and appearance-based tasks, without adaption of the model's parameters; e.g., using a frozen backbone. Our largest model, a ViT-H/16 trained only on videos, obtains 81.9% on Kinetics-400, 72.2% on Something-Something-v2, and 77.9% on ImageNet1K.
Create account to get full access
Overview
- This paper revisits the idea of using feature prediction as a way to learn visual representations from video data.
- The authors explore various approaches to feature prediction, including predicting motion, object, and other visual features, and evaluate their effectiveness for learning useful visual representations.
- The research aims to provide insights into the relative merits of different feature prediction tasks and their implications for video representation learning.
Plain English Explanation
The paper focuses on a technique called "feature prediction" for learning visual representations from video data. The idea is that by training a model to predict certain features or characteristics of the video frames, it can learn useful visual representations that can be applied to other tasks.
For example, the model might be trained to predict the motion of objects in the video, or to predict the identities of the objects appearing in each frame. The authors explore different types of features that can be predicted, and evaluate how well each approach works for learning visual representations that are useful for other computer vision tasks.
The key insight is that by forcing the model to learn about the underlying structure and dynamics of the video data, it can develop more robust and generalizable visual representations. This is an alternative to other approaches that might focus more on classifying the video content or simply reconstructing the input frames.
The paper provides a detailed technical analysis of the various feature prediction approaches and their performance, but the main takeaway is that this is a promising direction for learning visual representations from video data in a self-supervised way, without the need for manual labeling of the training data.
Technical Explanation
The paper explores different approaches to feature prediction for learning visual representations from video data. The authors consider several types of features that can be predicted, including:
- Motion features: Predicting the motion of objects or other visual elements between video frames.
- Object features: Predicting the identities or attributes of objects appearing in each frame.
- Other visual features: Predicting more abstract visual characteristics, such as texture, color, or spatial relationships.
The authors experiment with different neural network architectures, including video transformers and other models, to perform these feature prediction tasks. They evaluate the learned representations on a range of downstream computer vision tasks, such as image classification and object detection.
The results suggest that certain feature prediction tasks, such as predicting motion or object attributes, can be particularly effective for learning robust and generalizable visual representations from video data. The authors also explore the trade-offs between different feature prediction approaches and provide insights into the relative merits of each.
Overall, the paper contributes to the growing body of research on self-supervised representation learning from video, and provides a deeper understanding of the role of feature prediction in this context.
Critical Analysis
The paper provides a comprehensive and well-designed study of feature prediction for learning visual representations from video data. The authors explore a range of different feature prediction tasks and architectures, and their thorough evaluation on a variety of downstream tasks is a strength of the work.
However, the paper does acknowledge some limitations and areas for further research. For example, the authors note that the feature prediction tasks may not capture all the important aspects of visual representations, and that combining different prediction tasks or incorporating additional self-supervised objectives could potentially improve the learned representations further.
Additionally, the paper does not delve deeply into the interpretability or explainability of the learned representations. Understanding how the model is learning and representing the visual features could provide additional insights and guide future research in this direction.
Another potential area for further investigation is the scalability and practicality of these feature prediction approaches in real-world applications. The authors use relatively small-scale datasets in their experiments, and it would be valuable to explore the performance and feasibility of these techniques on larger, more diverse video data.
Overall, the paper presents a solid contribution to the field of self-supervised representation learning from video, and the insights and findings can serve as a valuable foundation for future research in this area.
Conclusion
This paper revisits the idea of using feature prediction as a way to learn visual representations from video data. The authors explore various approaches to feature prediction, including predicting motion, object, and other visual features, and evaluate their effectiveness for learning useful visual representations.
The results suggest that certain feature prediction tasks, such as predicting motion or object attributes, can be particularly effective for learning robust and generalizable visual representations from video data. The paper provides valuable insights into the relative merits of different feature prediction approaches and their implications for video representation learning.
While the paper acknowledges some limitations and areas for further research, it represents an important contribution to the field of self-supervised representation learning from video, and can serve as a stepping stone for future work in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Video Prediction Models as General Visual Encoders
James Maier, Nishanth Mohankumar
0
0
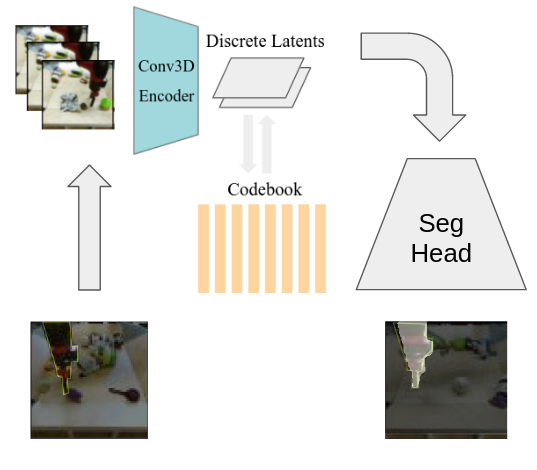
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
5/28/2024
🤿
Deep video representation learning: a survey
Elham Ravanbakhsh, Yongqing Liang, J. Ramanujam, Xin Li
0
0
This paper provides a review on representation learning for videos. We classify recent spatiotemporal feature learning methods for sequential visual data and compare their pros and cons for general video analysis. Building effective features for videos is a fundamental problem in computer vision tasks involving video analysis and understanding. Existing features can be generally categorized into spatial and temporal features. Their effectiveness under variations of illumination, occlusion, view and background are discussed. Finally, we discuss the remaining challenges in existing deep video representation learning studies.
5/13/2024

FILS: Self-Supervised Video Feature Prediction In Semantic Language Space
Mona Ahmadian, Frank Guerin, Andrew Gilbert
0
0
This paper demonstrates a self-supervised approach for learning semantic video representations. Recent vision studies show that a masking strategy for vision and natural language supervision has contributed to developing transferable visual pretraining. Our goal is to achieve a more semantic video representation by leveraging the text related to the video content during the pretraining in a fully self-supervised manner. To this end, we present FILS, a novel self-supervised video Feature prediction In semantic Language Space (FILS). The vision model can capture valuable structured information by correctly predicting masked feature semantics in language space. It is learned using a patch-wise video-text contrastive strategy, in which the text representations act as prototypes for transforming vision features into a language space, which are then used as targets for semantically meaningful feature prediction using our masked encoder-decoder structure. FILS demonstrates remarkable transferability on downstream action recognition tasks, achieving state-of-the-art on challenging egocentric datasets, like Epic-Kitchens, Something-SomethingV2, Charades-Ego, and EGTEA, using ViT-Base. Our efficient method requires less computation and smaller batches compared to previous works.
6/6/2024
Visual Representation Learning with Stochastic Frame Prediction
Huiwon Jang, Dongyoung Kim, Junsu Kim, Jinwoo Shin, Pieter Abbeel, Younggyo Seo
0
0
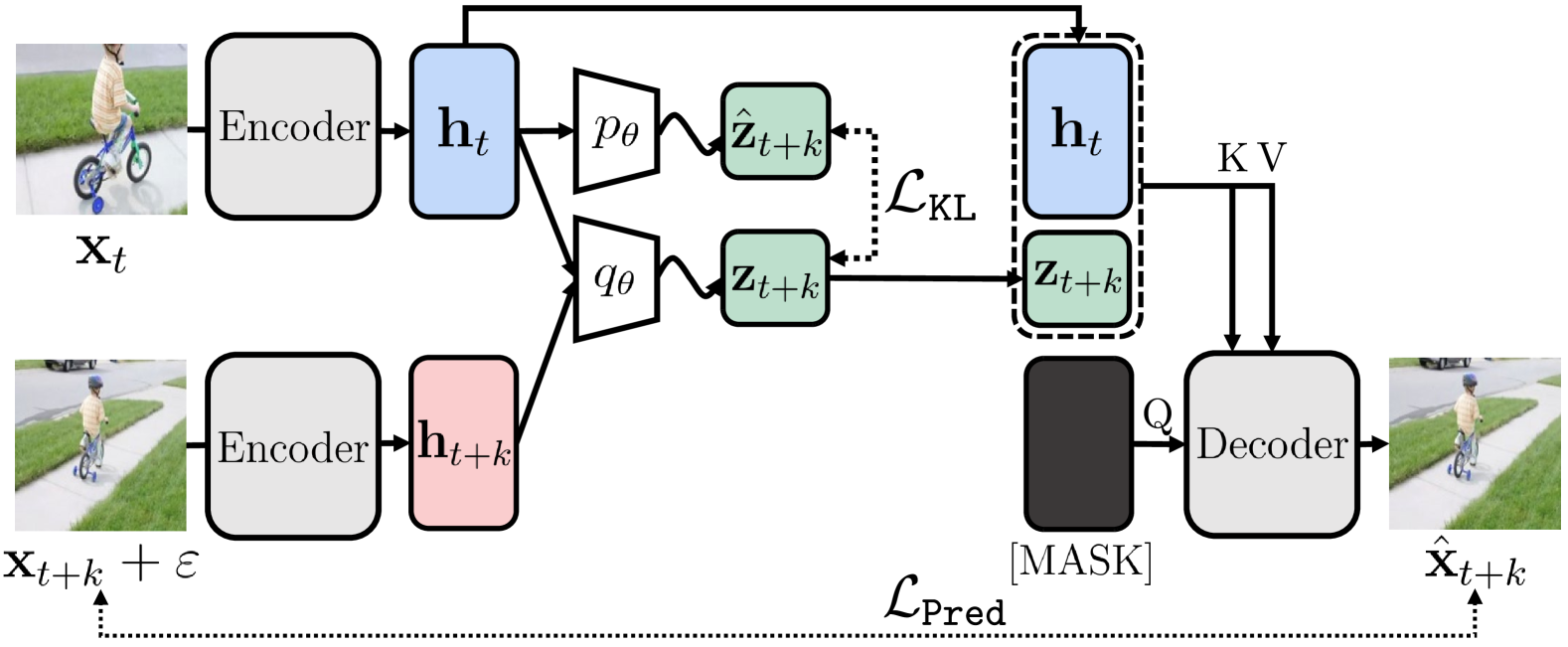
Self-supervised learning of image representations by predicting future frames is a promising direction but still remains a challenge. This is because of the under-determined nature of frame prediction; multiple potential futures can arise from a single current frame. To tackle this challenge, in this paper, we revisit the idea of stochastic video generation that learns to capture uncertainty in frame prediction and explore its effectiveness for representation learning. Specifically, we design a framework that trains a stochastic frame prediction model to learn temporal information between frames. Moreover, to learn dense information within each frame, we introduce an auxiliary masked image modeling objective along with a shared decoder architecture. We find this architecture allows for combining both objectives in a synergistic and compute-efficient manner. We demonstrate the effectiveness of our framework on a variety of tasks from video label propagation and vision-based robot learning domains, such as video segmentation, pose tracking, vision-based robotic locomotion, and manipulation tasks. Code is available on the project webpage: https://sites.google.com/view/2024rsp.
6/12/2024