Spatiotemporal Predictive Pre-training for Robotic Motor Control

0
Sign in to get full access
Overview
- This paper presents a self-supervised pre-training approach for robotic motor control, called Spatiotemporal Predictive Pre-training (SP3).
- SP3 aims to learn useful spatiotemporal representations from unlabeled robotic data, which can then be fine-tuned for specific robotic tasks.
- The key idea is to train a model to predict future visual observations and action sequences given past context, which helps the model learn predictive and causal relationships in the data.
Plain English Explanation
In this paper, the researchers developed a new way to train robotic systems without requiring a lot of labeled data. Their approach, called Spatiotemporal Predictive Pre-training (SP3), involves first training the robot to predict what it will see and what actions it will take in the future, based on its past experiences.
By learning to make these predictions, the robot can build up a general understanding of how its environment and actions are related, without needing detailed labels or instructions for specific tasks. This pre-trained knowledge can then be fine-tuned and adapted to help the robot perform various robotic control and manipulation tasks more effectively.
The key insight is that learning to anticipate the future can help the robot develop a more robust and flexible understanding of the world, which can then be applied to a wide range of real-world robotic applications. This approach aims to make robotics more accessible and efficient by reducing the need for large amounts of labeled training data.
Technical Explanation
The paper proposes a Spatiotemporal Predictive Pre-training (SP3) approach for learning useful representations from unlabeled robotic data that can then be fine-tuned for specific tasks.
The core idea is to train a model to predict future visual observations and action sequences given past context. This encourages the model to learn predictive and causal relationships in the data, which can provide a strong foundation for downstream robotic control tasks.
The SP3 model consists of several key components:
- A visual encoder that learns to represent the robot's visual observations.
- A temporal encoder that models the dynamics of the robot's actions and state over time.
- A predictive head that generates future visual observations and action sequences given the past context.
The model is trained in a self-supervised manner on unlabeled robot data, without any task-specific labels. By learning to predict the future, the model is encouraged to discover the underlying spatiotemporal structure of the robot's environment and behavior.
The paper demonstrates that the pre-trained SP3 representations can be effectively fine-tuned for a variety of robotic control tasks, such as object manipulation and navigation. The results show that SP3 outperforms other pre-training approaches and can significantly improve the sample efficiency and performance of downstream robotic control tasks.
Critical Analysis
The paper presents a well-designed and comprehensive pre-training approach for robotic motor control, with a strong technical foundation and promising empirical results. However, there are a few potential limitations and areas for further research:
-
The paper focuses on relatively simple robotic environments and tasks, such as object manipulation and navigation. It would be interesting to see how well the SP3 approach scales to more complex, real-world robotic scenarios with greater environmental and task diversity.
-
The authors mention that the SP3 model requires a significant amount of unlabeled robot data for pre-training. In some real-world settings, obtaining such large-scale robot data may be challenging. Techniques for data-efficient pre-training could be an area for further exploration.
-
The paper does not provide a detailed analysis of the learned representations and the specific spatiotemporal predictive capabilities of the SP3 model. A deeper investigation into the model's internal workings and the nature of the learned representations could yield additional insights.
-
While the paper demonstrates the effectiveness of SP3 for robotic control tasks, it does not explore the potential of these learned representations for other robotics-related challenges, such as intention anticipation or continuous learning. Expanding the applications of the SP3 approach could be a fruitful direction for future research.
Conclusion
The Spatiotemporal Predictive Pre-training (SP3) approach presented in this paper represents a promising step towards more efficient and effective robotic control systems. By learning to anticipate future visual observations and actions, the SP3 model is able to develop robust and flexible representations that can be successfully applied to a variety of downstream robotic tasks.
This work highlights the potential of self-supervised learning techniques to reduce the reliance on large amounts of labeled data in robotics, a key challenge in the field. As the researchers continue to refine and expand the SP3 approach, it could lead to significant advancements in the development of more capable and adaptable robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spatiotemporal Predictive Pre-training for Robotic Motor Control
Jiange Yang, Bei Liu, Jianlong Fu, Bocheng Pan, Gangshan Wu, Limin Wang
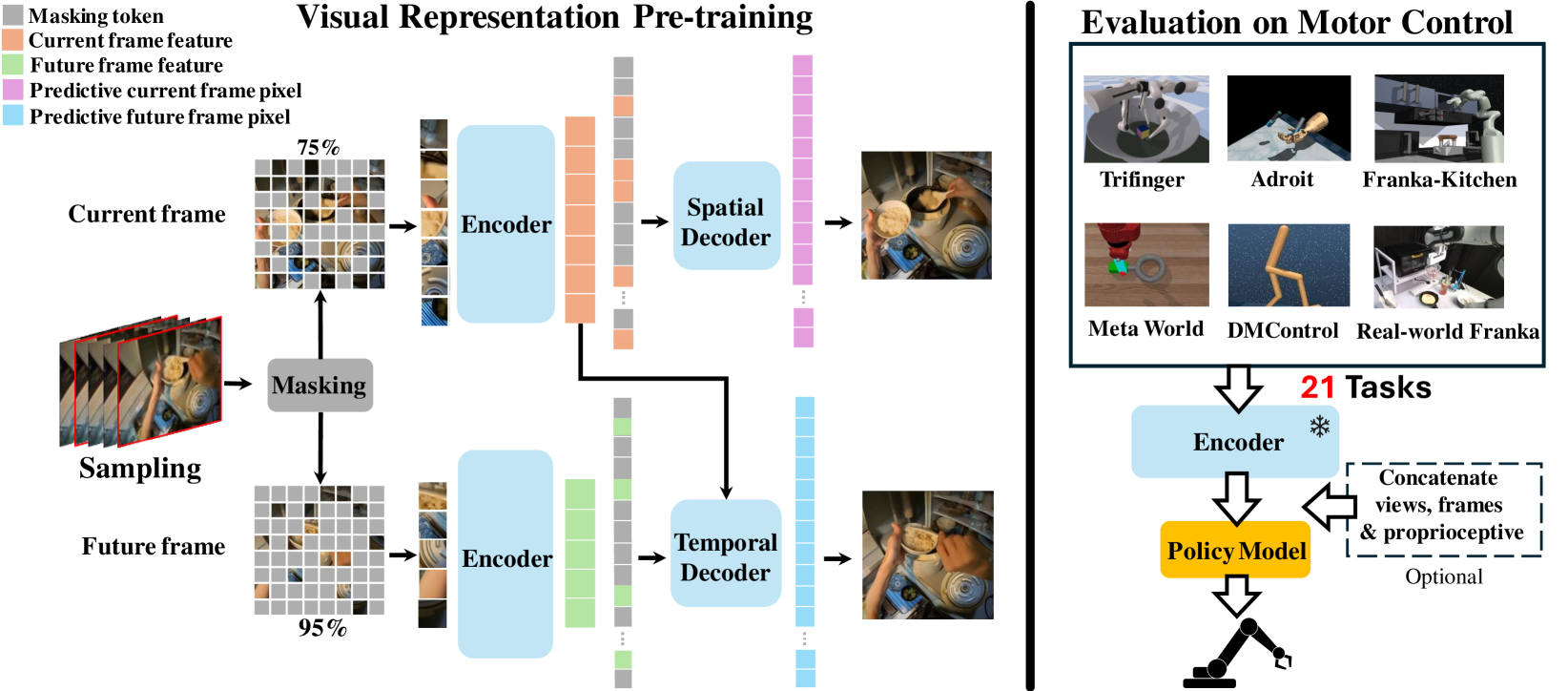
Robotic motor control necessitates the ability to predict the dynamics of environments and interaction objects. However, advanced self-supervised pre-trained visual representations (PVRs) in robotic motor control, leveraging large-scale egocentric videos, often focus solely on learning the static content features of sampled image frames. This neglects the crucial temporal motion clues in human video data, which implicitly contain key knowledge about sequential interacting and manipulating with the environments and objects. In this paper, we present a simple yet effective robotic motor control visual pre-training framework that jointly performs spatiotemporal prediction with dual decoders, utilizing large-scale video data, termed as textbf{STP}. STP adheres to two key designs in a multi-task learning manner. First, we perform spatial prediction on the masked current frame for learning content features. Second, we utilize the future frame with an extremely high masking ratio as a condition, based on the masked current frame, to conduct temporal prediction of future frame for capturing motion features. This asymmetric masking and decoder architecture design is very efficient, ensuring that our representation focusing on motion information while capturing spatial details. We carry out the largest-scale BC evaluation of PVRs for robotic motor control to date, which encompasses 21 tasks within a real-world Franka robot arm and 5 simulated environments. Extensive experiments demonstrate the effectiveness of STP as well as unleash its generality and data efficiency by further post-pre-training and hybrid pre-training. Our code and weights will be released for further applications.
Read more5/28/2024

0
3D-MVP: 3D Multiview Pretraining for Robotic Manipulation
Shengyi Qian, Kaichun Mo, Valts Blukis, David F. Fouhey, Dieter Fox, Ankit Goyal
Recent works have shown that visual pretraining on egocentric datasets using masked autoencoders (MAE) can improve generalization for downstream robotics tasks. However, these approaches pretrain only on 2D images, while many robotics applications require 3D scene understanding. In this work, we propose 3D-MVP, a novel approach for 3D multi-view pretraining using masked autoencoders. We leverage Robotic View Transformer (RVT), which uses a multi-view transformer to understand the 3D scene and predict gripper pose actions. We split RVT's multi-view transformer into visual encoder and action decoder, and pretrain its visual encoder using masked autoencoding on large-scale 3D datasets such as Objaverse. We evaluate 3D-MVP on a suite of virtual robot manipulation tasks and demonstrate improved performance over baselines. We also show promising results on a real robot platform with minimal finetuning. Our results suggest that 3D-aware pretraining is a promising approach to improve sample efficiency and generalization of vision-based robotic manipulation policies. We will release code and pretrained models for 3D-MVP to facilitate future research. Project site: https://jasonqsy.github.io/3DMVP
Read more6/27/2024

0
Composing Pre-Trained Object-Centric Representations for Robotics From What and Where Foundation Models
Junyao Shi, Jianing Qian, Yecheng Jason Ma, Dinesh Jayaraman
There have recently been large advances both in pre-training visual representations for robotic control and segmenting unknown category objects in general images. To leverage these for improved robot learning, we propose $textbf{POCR}$, a new framework for building pre-trained object-centric representations for robotic control. Building on theories of what-where representations in psychology and computer vision, we use segmentations from a pre-trained model to stably locate across timesteps, various entities in the scene, capturing where information. To each such segmented entity, we apply other pre-trained models that build vector descriptions suitable for robotic control tasks, thus capturing what the entity is. Thus, our pre-trained object-centric representations for control are constructed by appropriately combining the outputs of off-the-shelf pre-trained models, with no new training. On various simulated and real robotic tasks, we show that imitation policies for robotic manipulators trained on POCR achieve better performance and systematic generalization than state of the art pre-trained representations for robotics, as well as prior object-centric representations that are typically trained from scratch.
Read more4/23/2024
📉
0
Bidirectional Progressive Transformer for Interaction Intention Anticipation
Zichen Zhang, Hongchen Luo, Wei Zhai, Yang Cao, Yu Kang
Interaction intention anticipation aims to jointly predict future hand trajectories and interaction hotspots. Existing research often treated trajectory forecasting and interaction hotspots prediction as separate tasks or solely considered the impact of trajectories on interaction hotspots, which led to the accumulation of prediction errors over time. However, a deeper inherent connection exists between hand trajectories and interaction hotspots, which allows for continuous mutual correction between them. Building upon this relationship, a novel Bidirectional prOgressive Transformer (BOT), which introduces a Bidirectional Progressive mechanism into the anticipation of interaction intention is established. Initially, BOT maximizes the utilization of spatial information from the last observation frame through the Spatial-Temporal Reconstruction Module, mitigating conflicts arising from changes of view in first-person videos. Subsequently, based on two independent prediction branches, a Bidirectional Progressive Enhancement Module is introduced to mutually improve the prediction of hand trajectories and interaction hotspots over time to minimize error accumulation. Finally, acknowledging the intrinsic randomness in human natural behavior, we employ a Trajectory Stochastic Unit and a C-VAE to introduce appropriate uncertainty to trajectories and interaction hotspots, respectively. Our method achieves state-of-the-art results on three benchmark datasets Epic-Kitchens-100, EGO4D, and EGTEA Gaze+, demonstrating superior in complex scenarios.
Read more5/10/2024