Visual Text Generation in the Wild

0

Sign in to get full access
Overview
- Presents a new approach for visual text generation in real-world scenarios
- Leverages conditional diffusion models to generate realistic text overlays on images
- Demonstrates how the model can be applied to a variety of applications, including scene text insertion, text image editing, and text-guided image generation
Plain English Explanation
This paper introduces a new method for generating text on images in real-world situations. The key innovation is the use of conditional diffusion models, which are a type of machine learning model that can create realistic-looking text that is tailored to the specific image and context.
The researchers show how this approach can be applied to a variety of applications, such as inserting scene text into images, editing text in images, and generating images based on text descriptions. By leveraging the power of diffusion models, the system is able to produce highly realistic and contextually-appropriate text overlays, opening up new possibilities for visual content creation and manipulation.
Technical Explanation
The paper presents a novel framework for visual text generation in real-world scenarios. At the core of the approach are conditional diffusion models, which are a type of generative model that can produce realistic text conditioned on the input image and other relevant information.
The researchers designed a multi-stage pipeline that first extracts relevant image features, then generates the text content using the diffusion model, and finally composites the text back onto the original image. Key technical innovations include the use of a spatial attention mechanism to guide the text generation process and the incorporation of perceptual loss functions to improve the visual realism of the output.
Extensive experiments on a diverse set of real-world datasets demonstrate the effectiveness of the proposed approach across a range of applications, such as scene text insertion, text image editing, and text-guided image generation. The results show that the system can generate high-quality, context-aware text overlays that seamlessly integrate with the input images.
Critical Analysis
The paper presents a compelling approach to the challenging problem of visual text generation in the wild. The use of conditional diffusion models is a particularly promising direction, as these models have shown impressive capabilities in generating realistic and diverse content across various domains.
One potential limitation of the work is the reliance on a multi-stage pipeline, which may introduce additional complexity and potential points of failure. It would be interesting to explore end-to-end approaches that can jointly optimize the text generation and composition processes.
Additionally, the paper does not delve into the broader societal implications of this technology, such as the potential for misuse in the creation of fake or manipulated visual content. As this field continues to evolve, it will be important for researchers to carefully consider the ethical considerations and potential risks associated with these advancements.
Conclusion
This paper presents a novel approach for visual text generation in real-world scenarios, leveraging the power of conditional diffusion models. The proposed framework demonstrates impressive results across a variety of applications, showcasing the potential of this technology to enable new forms of visual content creation and manipulation.
While the technical innovations are noteworthy, the broader societal implications of this research will require careful examination and ongoing discourse. As the field of text-to-visual generation continues to advance, it will be crucial to prioritize responsible development and deployment of these powerful tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Visual Text Generation in the Wild
Yuanzhi Zhu, Jiawei Liu, Feiyu Gao, Wenyu Liu, Xinggang Wang, Peng Wang, Fei Huang, Cong Yao, Zhibo Yang
Recently, with the rapid advancements of generative models, the field of visual text generation has witnessed significant progress. However, it is still challenging to render high-quality text images in real-world scenarios, as three critical criteria should be satisfied: (1) Fidelity: the generated text images should be photo-realistic and the contents are expected to be the same as specified in the given conditions; (2) Reasonability: the regions and contents of the generated text should cohere with the scene; (3) Utility: the generated text images can facilitate related tasks (e.g., text detection and recognition). Upon investigation, we find that existing methods, either rendering-based or diffusion-based, can hardly meet all these aspects simultaneously, limiting their application range. Therefore, we propose in this paper a visual text generator (termed SceneVTG), which can produce high-quality text images in the wild. Following a two-stage paradigm, SceneVTG leverages a Multimodal Large Language Model to recommend reasonable text regions and contents across multiple scales and levels, which are used by a conditional diffusion model as conditions to generate text images. Extensive experiments demonstrate that the proposed SceneVTG significantly outperforms traditional rendering-based methods and recent diffusion-based methods in terms of fidelity and reasonability. Besides, the generated images provide superior utility for tasks involving text detection and text recognition. Code and datasets are available at AdvancedLiterateMachinery.
Read more7/22/2024

0
SceneTextGen: Layout-Agnostic Scene Text Image Synthesis with Diffusion Models
Qilong Zhangli, Jindong Jiang, Di Liu, Licheng Yu, Xiaoliang Dai, Ankit Ramchandani, Guan Pang, Dimitris N. Metaxas, Praveen Krishnan
While diffusion models have significantly advanced the quality of image generation their capability to accurately and coherently render text within these images remains a substantial challenge. Conventional diffusion-based methods for scene text generation are typically limited by their reliance on an intermediate layout output. This dependency often results in a constrained diversity of text styles and fonts an inherent limitation stemming from the deterministic nature of the layout generation phase. To address these challenges this paper introduces SceneTextGen a novel diffusion-based model specifically designed to circumvent the need for a predefined layout stage. By doing so SceneTextGen facilitates a more natural and varied representation of text. The novelty of SceneTextGen lies in its integration of three key components: a character-level encoder for capturing detailed typographic properties coupled with a character-level instance segmentation model and a word-level spotting model to address the issues of unwanted text generation and minor character inaccuracies. We validate the performance of our method by demonstrating improved character recognition rates on generated images across different public visual text datasets in comparison to both standard diffusion based methods and text specific methods.
Read more9/17/2024
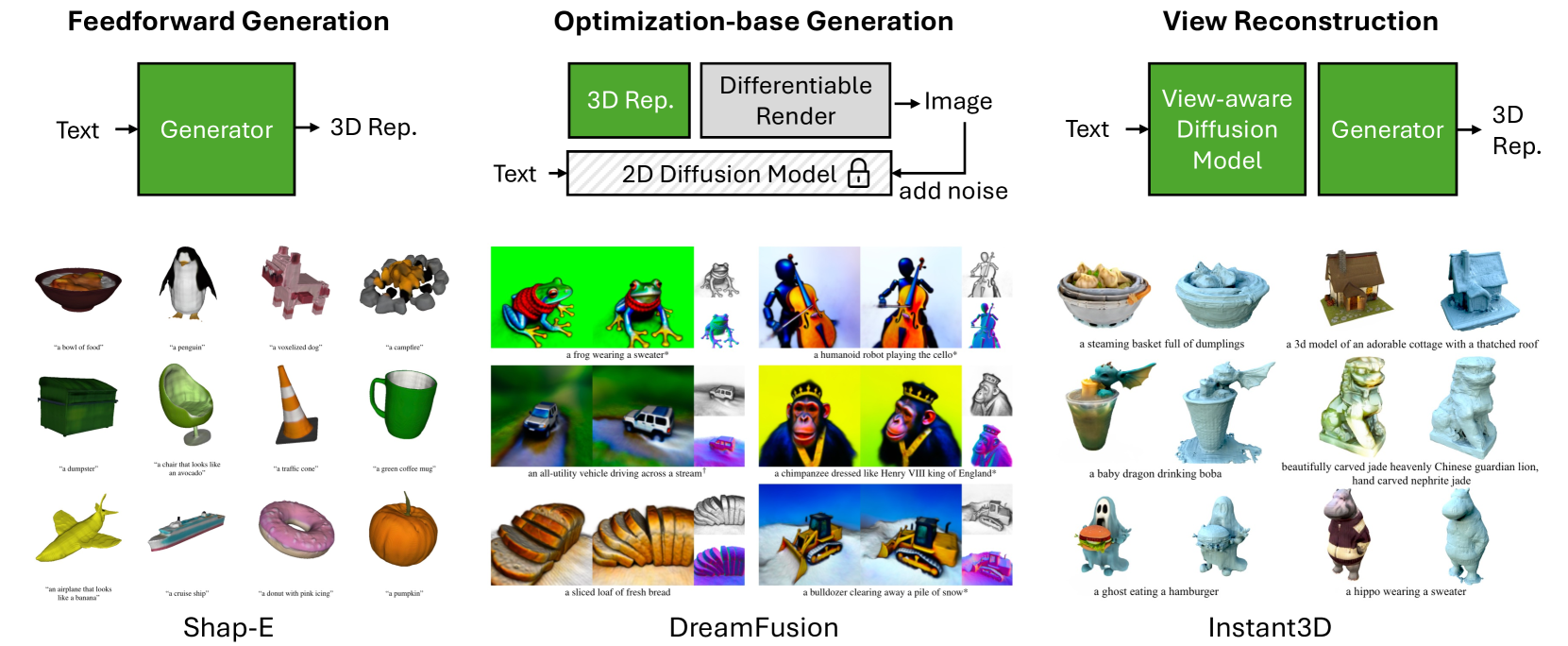
0
A Survey On Text-to-3D Contents Generation In The Wild
Chenhan Jiang
3D content creation plays a vital role in various applications, such as gaming, robotics simulation, and virtual reality. However, the process is labor-intensive and time-consuming, requiring skilled designers to invest considerable effort in creating a single 3D asset. To address this challenge, text-to-3D generation technologies have emerged as a promising solution for automating 3D creation. Leveraging the success of large vision language models, these techniques aim to generate 3D content based on textual descriptions. Despite recent advancements in this area, existing solutions still face significant limitations in terms of generation quality and efficiency. In this survey, we conduct an in-depth investigation of the latest text-to-3D creation methods. We provide a comprehensive background on text-to-3D creation, including discussions on datasets employed in training and evaluation metrics used to assess the quality of generated 3D models. Then, we delve into the various 3D representations that serve as the foundation for the 3D generation process. Furthermore, we present a thorough comparison of the rapidly growing literature on generative pipelines, categorizing them into feedforward generators, optimization-based generation, and view reconstruction approaches. By examining the strengths and weaknesses of these methods, we aim to shed light on their respective capabilities and limitations. Lastly, we point out several promising avenues for future research. With this survey, we hope to inspire researchers further to explore the potential of open-vocabulary text-conditioned 3D content creation.
Read more5/16/2024

0
Dual Modalities of Text: Visual and Textual Generative Pre-training
Yekun Chai, Qingyi Liu, Jingwu Xiao, Shuohuan Wang, Yu Sun, Hua Wu
Harnessing visual texts represents a burgeoning frontier in the evolution of language modeling. In this paper, we introduce a novel pre-training framework for a suite of pixel-based autoregressive language models, pre-training on a corpus of over 400 million documents rendered as RGB images. Our approach is characterized by a dual-modality training regimen, engaging both visual data through next patch prediction with a regression head and textual data via next token prediction with a classification head. This study is particularly focused on investigating the synergistic interplay between visual and textual modalities of language. Our comprehensive evaluation across a diverse array of benchmarks reveals that the confluence of visual and textual data substantially augments the efficacy of pixel-based language models. Notably, our findings show that a unidirectional pixel-based model, devoid of textual data during training, can match the performance levels of advanced bidirectional pixel-based models on various language understanding benchmarks. This work highlights the considerable untapped potential of integrating visual and textual information for language modeling purposes. We will release our code, data, and checkpoints to inspire further research advancement.
Read more4/17/2024