VisualRWKV: Exploring Recurrent Neural Networks for Visual Language Models
2406.13362
0
0

Abstract
Visual Language Models (VLMs) have rapidly progressed with the recent success of large language models. However, there have been few attempts to incorporate efficient linear Recurrent Neural Networks (RNNs) architectures into VLMs. In this study, we introduce VisualRWKV, the first application of a linear RNN model to multimodal learning tasks, leveraging the pre-trained RWKV language model. We propose a data-dependent recurrence and sandwich prompts to enhance our modeling capabilities, along with a 2D image scanning mechanism to enrich the processing of visual sequences. Extensive experiments demonstrate that VisualRWKV achieves competitive performance compared to Transformer-based models like LLaVA-1.5 on various benchmarks. To facilitate further research and analysis, we have made the checkpoints and the associated code publicly accessible at the following GitHub repository: href{https://github.com/howard-hou/VisualRWKV}{https://github.com/howard-hou/VisualRWKV}.
Create account to get full access
Overview
- Explores the use of Recurrent Neural Networks (RNNs) for Visual Language Models (VLMs)
- Introduces VisualRWKV, a novel RNN-based VLM that combines RWKV (RWKV: The New State-of-the-Art Language Model) and CLIP (CLIP: Connecting Text and Images)
- Demonstrates the effectiveness of VisualRWKV on various visual-language tasks, including zero-shot image classification and image-text retrieval
Plain English Explanation
VisualRWKV is a new type of model that combines two powerful AI technologies: recurrent neural networks (RNNs) and vision-language models. RNNs are a type of neural network that can process sequences of data, like text or audio, one piece at a time. Vision-language models, on the other hand, are designed to work with both images and text, allowing them to understand the relationship between visual and linguistic information.
The key idea behind VisualRWKV is to leverage the strengths of both RNNs and vision-language models to create a more powerful and versatile system. By using an RNN as the core of the model, VisualRWKV can process information sequentially, which can be useful for tasks like image captioning or visual question answering. At the same time, VisualRWKV integrates CLIP, a well-known vision-language model, to give it the ability to understand the semantic connections between images and text.
One of the main advantages of VisualRWKV is its flexibility. Because it is based on an RNN, VisualRWKV can be used for a wide range of visual-language tasks, from image classification to image-text retrieval. Additionally, the researchers behind VisualRWKV show that it can be trained using relatively small datasets, making it a more accessible option for some applications.
Overall, VisualRWKV represents an exciting new approach to combining the power of RNNs and vision-language models, with the potential to unlock new possibilities in areas like image understanding, multimodal reasoning, and beyond.
Technical Explanation
VisualRWKV builds on the success of the RWKV (RWKV: The New State-of-the-Art Language Model) language model by incorporating the capabilities of the CLIP (CLIP: Connecting Text and Images) vision-language model. The RWKV model is a novel type of recurrent neural network (RNN) that has been shown to outperform traditional RNNs and transformer-based models on a variety of language tasks.
To create VisualRWKV, the researchers first pre-trained the RWKV model on a large corpus of text data. They then fine-tuned this pre-trained model using the CLIP vision-language dataset, which consists of image-text pairs. This allowed the model to learn the visual-semantic associations between images and the corresponding textual descriptions.
The key architectural innovation of VisualRWKV is the way it integrates the CLIP model. Instead of simply appending the CLIP features to the RWKV hidden state, the researchers designed a more sophisticated fusion mechanism that allows the two components to interact more deeply. This includes using CLIP features to modulate the RWKV state, as well as incorporating CLIP attention weights into the RWKV update process.
The researchers evaluated VisualRWKV on a range of visual-language tasks, including zero-shot image classification and image-text retrieval. They showed that VisualRWKV outperformed both pure RNN-based models and transformer-based vision-language models on these benchmarks. The model's ability to effectively leverage the complementary strengths of RNNs and vision-language models appears to be a key factor in its strong performance.
Critical Analysis
One potential limitation of VisualRWKV is that it relies on the availability of large-scale, high-quality vision-language datasets like CLIP for fine-tuning. While the researchers demonstrate that VisualRWKV can be trained on relatively small datasets, its full potential may be dependent on access to extensive multimodal training data.
Additionally, the authors do not provide a detailed analysis of the model's computational efficiency or memory footprint, which could be important considerations for real-world deployment, especially on resource-constrained devices. Further research into the scalability and deployment characteristics of VisualRWKV would be valuable.
That said, the core idea of combining the sequential processing capabilities of RNNs with the multimodal understanding of vision-language models is a promising direction for future work. PointRWKV: Efficient RWKV-like Model for Hierarchical Point Cloud Processing and Diffusion-RWKV: Scaling RWKV-like Architectures with Diffusion demonstrate the versatility of the RWKV architecture and suggest that VisualRWKV could be extended to other modalities beyond images and text.
Conclusion
VisualRWKV represents an exciting step forward in the development of versatile and powerful visual-language models. By combining the strengths of recurrent neural networks and vision-language models, the researchers have created a system that can effectively tackle a wide range of multimodal tasks, from image classification to image-text retrieval. The model's strong performance and potential for further development suggest that VisualRWKV could have significant implications for fields such as Vision-Language Models Provide Promptable Representations for Reinforcement Learning and Advancing Regular Language Reasoning with Linear Recurrent Neural Networks, where the integration of visual and linguistic understanding is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
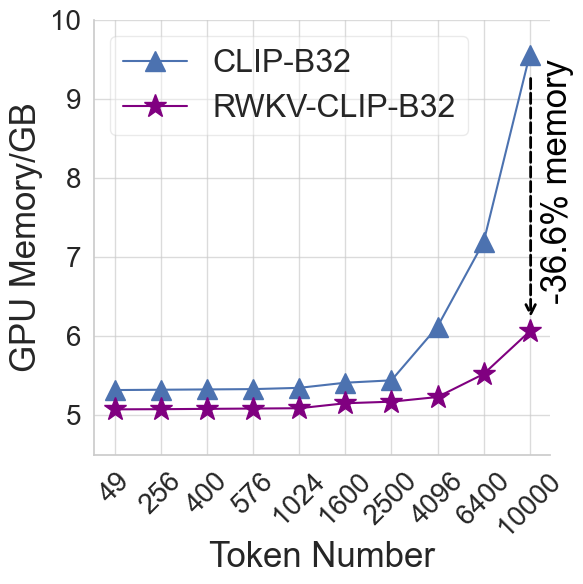
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024
Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Junshi Huang
0
0
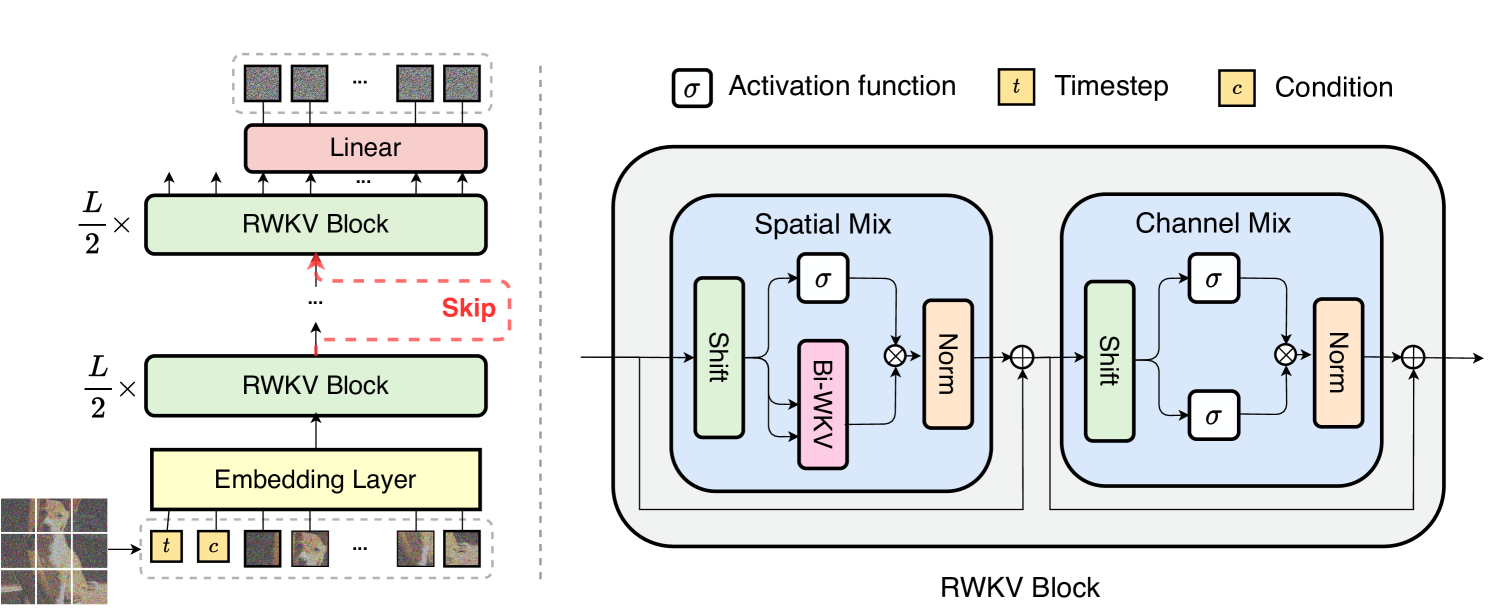
Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation. This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for diffusion model applied to image generation tasks, referred to as Diffusion-RWKV. Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations. Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.
4/9/2024

PointRWKV: Efficient RWKV-Like Model for Hierarchical Point Cloud Learning
Qingdong He, Jiangning Zhang, Jinlong Peng, Haoyang He, Yabiao Wang, Chengjie Wang
0
0
Transformers have revolutionized the point cloud learning task, but the quadratic complexity hinders its extension to long sequence and makes a burden on limited computational resources. The recent advent of RWKV, a fresh breed of deep sequence models, has shown immense potential for sequence modeling in NLP tasks. In this paper, we present PointRWKV, a model of linear complexity derived from the RWKV model in the NLP field with necessary modifications for point cloud learning tasks. Specifically, taking the embedded point patches as input, we first propose to explore the global processing capabilities within PointRWKV blocks using modified multi-headed matrix-valued states and a dynamic attention recurrence mechanism. To extract local geometric features simultaneously, we design a parallel branch to encode the point cloud efficiently in a fixed radius near-neighbors graph with a graph stabilizer. Furthermore, we design PointRWKV as a multi-scale framework for hierarchical feature learning of 3D point clouds, facilitating various downstream tasks. Extensive experiments on different point cloud learning tasks show our proposed PointRWKV outperforms the transformer- and mamba-based counterparts, while significantly saving about 46% FLOPs, demonstrating the potential option for constructing foundational 3D models.
5/27/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024