Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
2404.04478
2
1
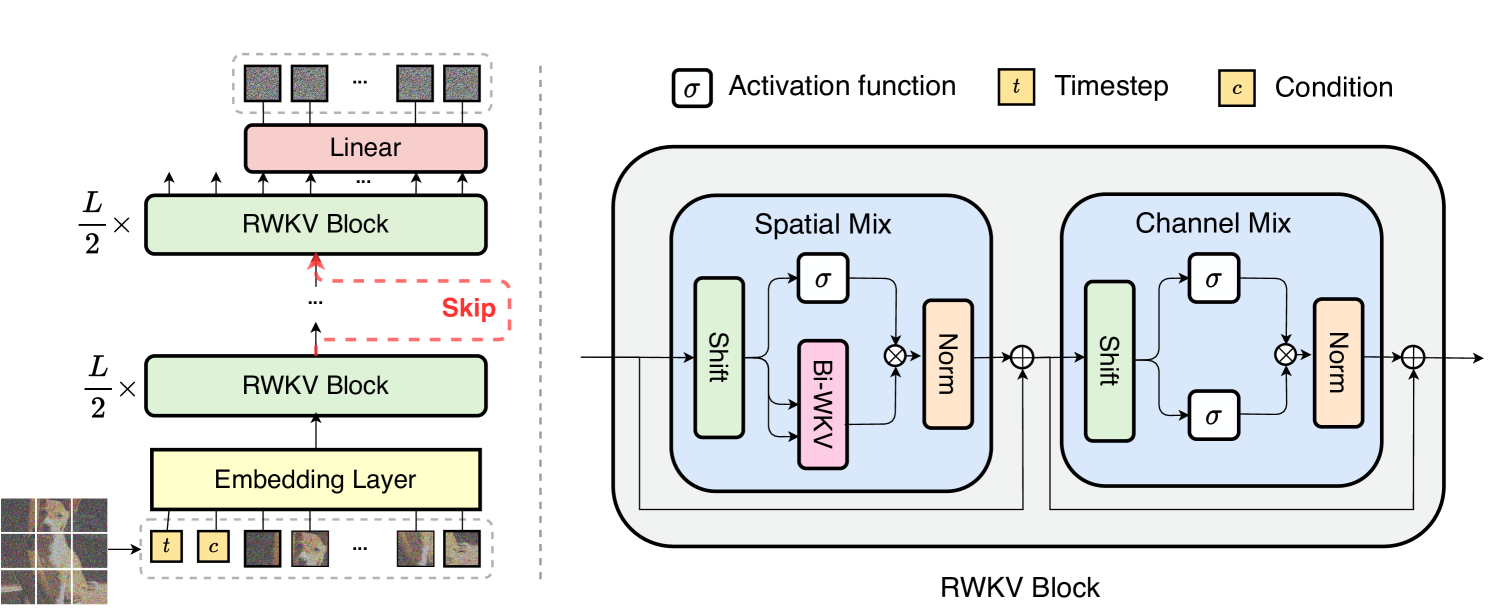
Abstract
Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation. This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for diffusion model applied to image generation tasks, referred to as Diffusion-RWKV. Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations. Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.
Create account to get full access
Overview
- This paper introduces "Diffusion-RWKV", a new architecture that scales RWKV-like models for diffusion-based image generation.
- RWKV is a recently proposed language model architecture that has shown promising results in various tasks.
- The authors investigate how RWKV-like architectures can be adapted and scaled for diffusion models, which are a powerful class of generative models.
- The proposed Diffusion-RWKV architecture aims to improve the performance and efficiency of diffusion models compared to existing approaches.
Plain English Explanation
Diffusion models are a type of machine learning model that can generate new images by gradually transforming random noise into realistic-looking pictures. These models have shown impressive results, but they can be computationally expensive to train and run.
The authors of this paper wanted to explore a new way to build diffusion models that could be more efficient and effective. They looked at a recent language model architecture called RWKV, which has some interesting properties that might be useful for diffusion models.
The key idea behind Diffusion-RWKV is to adapt the RWKV architecture to work with diffusion models. RWKV has a unique way of processing information that the authors believe could help diffusion models generate better images more quickly.
By scaling up the RWKV-like architecture and applying it to diffusion models, the researchers hope to create a new class of diffusion models that are more powerful and practical for real-world applications, such as generating high-quality images or fine-grained image editing.
Technical Explanation
The paper first provides some background on diffusion models and the RWKV architecture. Diffusion models work by gradually adding noise to an image and then learning to reverse that process, allowing them to generate new images from scratch. RWKV is a language model that uses a unique recurrent attention mechanism, which the authors believe could be beneficial for diffusion models.
The core of the Diffusion-RWKV architecture is the adaptation of the RWKV attention mechanism to work with diffusion models. This involves modifying the RWKV layers to handle the specific data and objectives of diffusion models, such as predicting the noise that was added to the image at each step of the diffusion process.
The authors also explore scaling up the Diffusion-RWKV model, experimenting with different model sizes and training regimes. They find that larger Diffusion-RWKV models can achieve state-of-the-art performance on several diffusion-based image generation benchmarks, outperforming previous approaches.
Through extensive experimentation, the paper provides insights into the strengths and limitations of the Diffusion-RWKV approach. For example, the authors note that the model can struggle with certain types of complex images, suggesting areas for future research and improvement.
Critical Analysis
The paper presents a well-designed study that thoroughly investigates the potential of RWKV-like architectures for diffusion models. The authors' attention to scaling and performance is commendable, as it helps to situate the Diffusion-RWKV approach within the broader context of diffusion model research.
However, the paper does acknowledge some limitations of the Diffusion-RWKV model, such as its struggles with certain types of complex images. This suggests that further research may be needed to fully understand the strengths and weaknesses of this approach, and to identify ways to overcome its current limitations.
Additionally, the authors do not provide a deep analysis of the underlying mechanisms and design choices that lead to the performance improvements of Diffusion-RWKV. A more detailed exploration of the model's inner workings and the reasons for its success could help to inform future research in this area.
Overall, the paper presents a compelling case for the potential of RWKV-like architectures in the context of diffusion models, but also highlights the need for continued investigation and refinement of this approach. Further research into diffusion-based models may help to uncover additional insights and opportunities for improvement.
Conclusion
The Diffusion-RWKV paper introduces a novel approach to scaling RWKV-like architectures for diffusion-based image generation. By adapting the unique properties of RWKV to the diffusion model framework, the authors have developed a promising new class of generative models that can achieve state-of-the-art performance on several benchmarks.
The findings of this research suggest that there is significant potential in exploring the intersection of RWKV-like architectures and diffusion models, and that further development of these techniques could lead to more powerful and efficient generative models in the future. As the field of diffusion-based image generation continues to evolve, the Diffusion-RWKV approach may serve as an important stepping stone towards even more advanced and capable systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

PointRWKV: Efficient RWKV-Like Model for Hierarchical Point Cloud Learning
Qingdong He, Jiangning Zhang, Jinlong Peng, Haoyang He, Yabiao Wang, Chengjie Wang
0
0
Transformers have revolutionized the point cloud learning task, but the quadratic complexity hinders its extension to long sequence and makes a burden on limited computational resources. The recent advent of RWKV, a fresh breed of deep sequence models, has shown immense potential for sequence modeling in NLP tasks. In this paper, we present PointRWKV, a model of linear complexity derived from the RWKV model in the NLP field with necessary modifications for point cloud learning tasks. Specifically, taking the embedded point patches as input, we first propose to explore the global processing capabilities within PointRWKV blocks using modified multi-headed matrix-valued states and a dynamic attention recurrence mechanism. To extract local geometric features simultaneously, we design a parallel branch to encode the point cloud efficiently in a fixed radius near-neighbors graph with a graph stabilizer. Furthermore, we design PointRWKV as a multi-scale framework for hierarchical feature learning of 3D point clouds, facilitating various downstream tasks. Extensive experiments on different point cloud learning tasks show our proposed PointRWKV outperforms the transformer- and mamba-based counterparts, while significantly saving about 46% FLOPs, demonstrating the potential option for constructing foundational 3D models.
5/27/2024
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
Qihao Liu, Zhanpeng Zeng, Ju He, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
0
0
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via patchification), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512. Project page: https://qihao067.github.io/projects/DiMR
6/14/2024

Diffscaler: Enhancing the Generative Prowess of Diffusion Transformers
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M. Patel
0
0
Recently, diffusion transformers have gained wide attention with its excellent performance in text-to-image and text-to-vidoe models, emphasizing the need for transformers as backbone for diffusion models. Transformer-based models have shown better generalization capability compared to CNN-based models for general vision tasks. However, much less has been explored in the existing literature regarding the capabilities of transformer-based diffusion backbones and expanding their generative prowess to other datasets. This paper focuses on enabling a single pre-trained diffusion transformer model to scale across multiple datasets swiftly, allowing for the completion of diverse generative tasks using just one model. To this end, we propose DiffScaler, an efficient scaling strategy for diffusion models where we train a minimal amount of parameters to adapt to different tasks. In particular, we learn task-specific transformations at each layer by incorporating the ability to utilize the learned subspaces of the pre-trained model, as well as the ability to learn additional task-specific subspaces, which may be absent in the pre-training dataset. As these parameters are independent, a single diffusion model with these task-specific parameters can be used to perform multiple tasks simultaneously. Moreover, we find that transformer-based diffusion models significantly outperform CNN-based diffusion models methods while performing fine-tuning over smaller datasets. We perform experiments on four unconditional image generation datasets. We show that using our proposed method, a single pre-trained model can scale up to perform these conditional and unconditional tasks, respectively, with minimal parameter tuning while performing as close as fine-tuning an entire diffusion model for that particular task.
4/16/2024

VisualRWKV: Exploring Recurrent Neural Networks for Visual Language Models
Haowen Hou, Peigen Zeng, Fei Ma, Fei Richard Yu
0
0
Visual Language Models (VLMs) have rapidly progressed with the recent success of large language models. However, there have been few attempts to incorporate efficient linear Recurrent Neural Networks (RNNs) architectures into VLMs. In this study, we introduce VisualRWKV, the first application of a linear RNN model to multimodal learning tasks, leveraging the pre-trained RWKV language model. We propose a data-dependent recurrence and sandwich prompts to enhance our modeling capabilities, along with a 2D image scanning mechanism to enrich the processing of visual sequences. Extensive experiments demonstrate that VisualRWKV achieves competitive performance compared to Transformer-based models like LLaVA-1.5 on various benchmarks. To facilitate further research and analysis, we have made the checkpoints and the associated code publicly accessible at the following GitHub repository: href{https://github.com/howard-hou/VisualRWKV}{https://github.com/howard-hou/VisualRWKV}.
6/21/2024