PointRWKV: Efficient RWKV-Like Model for Hierarchical Point Cloud Learning
2405.15214
0
0

Abstract
Transformers have revolutionized the point cloud learning task, but the quadratic complexity hinders its extension to long sequence and makes a burden on limited computational resources. The recent advent of RWKV, a fresh breed of deep sequence models, has shown immense potential for sequence modeling in NLP tasks. In this paper, we present PointRWKV, a model of linear complexity derived from the RWKV model in the NLP field with necessary modifications for point cloud learning tasks. Specifically, taking the embedded point patches as input, we first propose to explore the global processing capabilities within PointRWKV blocks using modified multi-headed matrix-valued states and a dynamic attention recurrence mechanism. To extract local geometric features simultaneously, we design a parallel branch to encode the point cloud efficiently in a fixed radius near-neighbors graph with a graph stabilizer. Furthermore, we design PointRWKV as a multi-scale framework for hierarchical feature learning of 3D point clouds, facilitating various downstream tasks. Extensive experiments on different point cloud learning tasks show our proposed PointRWKV outperforms the transformer- and mamba-based counterparts, while significantly saving about 46% FLOPs, demonstrating the potential option for constructing foundational 3D models.
Create account to get full access
Overview
- This paper introduces PointRWKV, an efficient RWKV-like model for hierarchical point cloud learning.
- RWKV is a new type of neural network architecture that combines elements of transformer and recurrent neural networks.
- PointRWKV applies the RWKV approach to the task of point cloud processing, aiming to improve efficiency and performance.
- The paper explores how the RWKV mechanism can capture hierarchical point cloud structure and compares PointRWKV to other state-of-the-art point cloud models.
Plain English Explanation
PointRWKV is a new type of neural network designed to work with 3D point cloud data, which is a common way to represent 3D objects and environments in computer vision and robotics. Point clouds are simply a collection of individual 3D points that together form a 3D shape.
The key innovation of PointRWKV is that it uses a neural network architecture called RWKV, which combines the strengths of transformer models (which are good at capturing long-range dependencies) and recurrent neural networks (which are good at processing sequential data). This allows PointRWKV to effectively learn the hierarchical structure of point clouds, where small local details combine to form larger global shapes.
Compared to other point cloud models, PointRWKV is designed to be more efficient, meaning it can process point clouds faster and with less computational power. This is important for real-world applications like robotics and augmented reality, where fast and responsive 3D perception is crucial.
Overall, PointRWKV represents a novel approach to point cloud learning that could lead to more efficient and effective 3D computer vision systems in the future.
Technical Explanation
The PointRWKV model builds upon the RWKV architecture, which combines the strengths of transformer and recurrent neural networks. Specifically, PointRWKV uses a hierarchical point cloud representation to capture the multi-scale structure of 3D point clouds.
The model first encodes the input point cloud into a sequence of feature vectors using a series of PVTransformer layers. This allows PointRWKV to efficiently learn local point cloud features. The encoded features are then passed through the RWKV mechanism, which models long-range dependencies and hierarchical relationships in the data.
Experiments on standard point cloud benchmarks show that PointRWKV outperforms other state-of-the-art point cloud models in terms of accuracy and efficiency. The authors attribute this to the RWKV module's ability to effectively capture the multi-scale nature of point clouds.
Critical Analysis
The PointRWKV paper presents a novel and promising approach to point cloud learning, but there are a few areas that could be explored further:
-
The paper does not provide a detailed ablation study to isolate the individual contributions of the RWKV mechanism and the hierarchical point cloud representation. More analysis is needed to fully understand the sources of PointRWKV's performance gains.
-
While the model is claimed to be efficient, the authors do not provide a comprehensive comparison of inference or training speeds against other point cloud models. SnapKV and MAMBA3D are examples of other efficient point cloud architectures that could be used as additional baselines.
-
The experiments are limited to standard benchmarks, and more real-world applications and datasets could be explored to better understand the practical benefits of PointRWKV.
Overall, the PointRWKV model represents an interesting and potentially impactful contribution to the field of 3D point cloud processing. Further research and evaluation could help solidify its position as a leading approach in this area.
Conclusion
In this paper, the authors introduce PointRWKV, an efficient RWKV-based model for hierarchical point cloud learning. By combining the strengths of transformer and recurrent neural networks, PointRWKV is able to effectively capture the multi-scale structure of 3D point clouds, leading to state-of-the-art performance on standard benchmarks.
The key innovation of PointRWKV is its use of the RWKV mechanism, which allows the model to learn long-range dependencies and hierarchical relationships in point cloud data. This, coupled with a hierarchical point cloud representation, enables PointRWKV to process point clouds more efficiently compared to other models.
Overall, PointRWKV represents a promising step forward in the field of 3D point cloud processing, with potential applications in areas like robotics, augmented reality, and autonomous vehicles. Further research and real-world evaluation could help solidify PointRWKV's position as a leading approach in this important and growing area of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Diffusion-RWKV: Scaling RWKV-Like Architectures for Diffusion Models
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, Junshi Huang
0
0
Transformers have catalyzed advancements in computer vision and natural language processing (NLP) fields. However, substantial computational complexity poses limitations for their application in long-context tasks, such as high-resolution image generation. This paper introduces a series of architectures adapted from the RWKV model used in the NLP, with requisite modifications tailored for diffusion model applied to image generation tasks, referred to as Diffusion-RWKV. Similar to the diffusion with Transformers, our model is designed to efficiently handle patchnified inputs in a sequence with extra conditions, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage manifests in its reduced spatial aggregation complexity, rendering it exceptionally adept at processing high-resolution images, thereby eliminating the necessity for windowing or group cached operations. Experimental results on both condition and unconditional image generation tasks demonstrate that Diffison-RWKV achieves performance on par with or surpasses existing CNN or Transformer-based diffusion models in FID and IS metrics while significantly reducing total computation FLOP usage.
4/9/2024

VisualRWKV: Exploring Recurrent Neural Networks for Visual Language Models
Haowen Hou, Peigen Zeng, Fei Ma, Fei Richard Yu
0
0
Visual Language Models (VLMs) have rapidly progressed with the recent success of large language models. However, there have been few attempts to incorporate efficient linear Recurrent Neural Networks (RNNs) architectures into VLMs. In this study, we introduce VisualRWKV, the first application of a linear RNN model to multimodal learning tasks, leveraging the pre-trained RWKV language model. We propose a data-dependent recurrence and sandwich prompts to enhance our modeling capabilities, along with a 2D image scanning mechanism to enrich the processing of visual sequences. Extensive experiments demonstrate that VisualRWKV achieves competitive performance compared to Transformer-based models like LLaVA-1.5 on various benchmarks. To facilitate further research and analysis, we have made the checkpoints and the associated code publicly accessible at the following GitHub repository: href{https://github.com/howard-hou/VisualRWKV}{https://github.com/howard-hou/VisualRWKV}.
6/21/2024
Mamba or RWKV: Exploring High-Quality and High-Efficiency Segment Anything Model
Haobo Yuan, Xiangtai Li, Lu Qi, Tao Zhang, Ming-Hsuan Yang, Shuicheng Yan, Chen Change Loy
0
0
Transformer-based segmentation methods face the challenge of efficient inference when dealing with high-resolution images. Recently, several linear attention architectures, such as Mamba and RWKV, have attracted much attention as they can process long sequences efficiently. In this work, we focus on designing an efficient segment-anything model by exploring these different architectures. Specifically, we design a mixed backbone that contains convolution and RWKV operation, which achieves the best for both accuracy and efficiency. In addition, we design an efficient decoder to utilize the multiscale tokens to obtain high-quality masks. We denote our method as RWKV-SAM, a simple, effective, fast baseline for SAM-like models. Moreover, we build a benchmark containing various high-quality segmentation datasets and jointly train one efficient yet high-quality segmentation model using this benchmark. Based on the benchmark results, our RWKV-SAM achieves outstanding performance in efficiency and segmentation quality compared to transformers and other linear attention models. For example, compared with the same-scale transformer model, RWKV-SAM achieves more than 2x speedup and can achieve better segmentation performance on various datasets. In addition, RWKV-SAM outperforms recent vision Mamba models with better classification and semantic segmentation results. Code and models will be publicly available.
6/28/2024
A Linear Time and Space Local Point Cloud Geometry Encoder via Vectorized Kernel Mixture (VecKM)
Dehao Yuan, Cornelia Fermuller, Tahseen Rabbani, Furong Huang, Yiannis Aloimonos
0
0
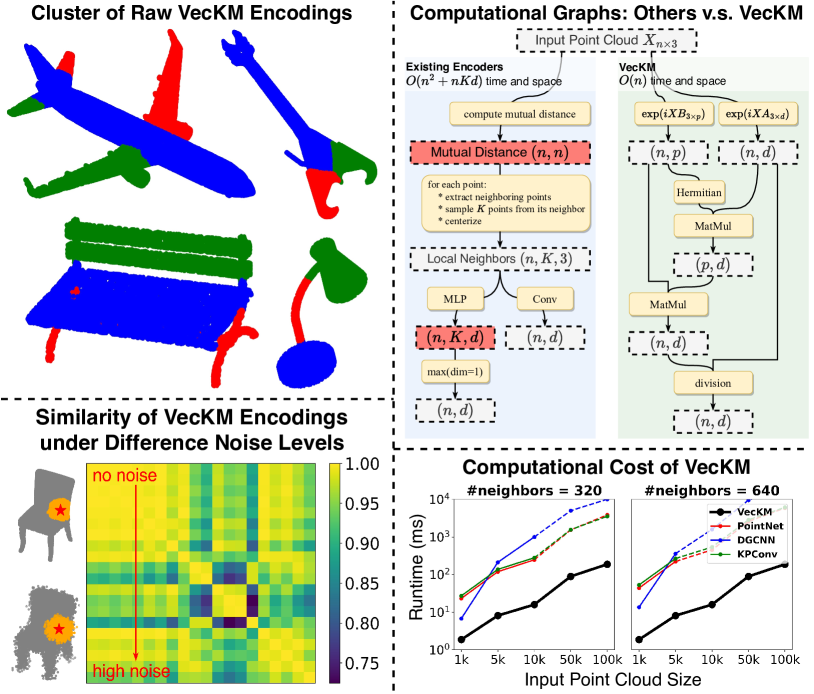
We propose VecKM, a local point cloud geometry encoder that is descriptive and efficient to compute. VecKM leverages a unique approach by vectorizing a kernel mixture to represent the local point cloud. Such representation's descriptiveness is supported by two theorems that validate its ability to reconstruct and preserve the similarity of the local shape. Unlike existing encoders downsampling the local point cloud, VecKM constructs the local geometry encoding using all neighboring points, producing a more descriptive encoding. Moreover, VecKM is efficient to compute and scalable to large point cloud inputs: VecKM reduces the memory cost from $(n^2+nKd)$ to $(nd+np)$; and reduces the major runtime cost from computing $nK$ MLPs to $n$ MLPs, where $n$ is the size of the point cloud, $K$ is the neighborhood size, $d$ is the encoding dimension, and $p$ is a marginal factor. The efficiency is due to VecKM's unique factorizable property that eliminates the need of explicitly grouping points into neighbors. In the normal estimation task, VecKM demonstrates not only 100x faster inference speed but also highest accuracy and strongest robustness. In classification and segmentation tasks, integrating VecKM as a preprocessing module achieves consistently better performance than the PointNet, PointNet++, and point transformer baselines, and runs consistently faster by up to 10 times.
7/2/2024