VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
2401.13649
0
1
🏋️
Abstract
Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic textit{visually grounded tasks}. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web. Our code, baseline models, and data is publicly available at https://jykoh.com/vwa.
Create account to get full access
Overview
- This paper introduces VisualWebArena, a new benchmark for evaluating the performance of autonomous agents on web-based tasks that require processing visual and textual information.
- Existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information. VisualWebArena aims to bridge this gap.
- The benchmark comprises a diverse set of web-based tasks that evaluate an agent's ability to process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives.
- The authors conduct an extensive evaluation of state-of-the-art language models (LLMs), including several multimodal models, and identify limitations in their capabilities for these visually-grounded web tasks.
Plain English Explanation
Autonomous agents are computer programs that can plan, reason, and take actions on their own. VisualWebArena is a new tool designed to test how well these agents can handle tasks that involve both visual and textual information, which is common in real-world computer interfaces.
Most existing benchmarks for autonomous agents focus on text-based tasks, but many practical applications also require understanding and interacting with visual information. VisualWebArena aims to address this gap by presenting a diverse set of web-based tasks that challenge agents to process images, interpret instructions, and take actions on websites to achieve specific goals.
The researchers evaluated several state-of-the-art language models, including multimodal models that can handle both text and images. Through their analysis, they found that even the most advanced models struggle with these visually-grounded web tasks, revealing important limitations in the current capabilities of autonomous agents. VisualWebArena provides a framework for further research and development to build stronger autonomous agents for the web.
Technical Explanation
The paper introduces VisualWebArena, a new benchmark designed to assess the performance of autonomous agents on web-based tasks that require processing both visual and textual information. Existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that rely on visual inputs to solve effectively.
VisualWebArena comprises a diverse set of web-based tasks that evaluate an agent's ability to interpret image-text inputs, understand natural language instructions, and execute actions on websites to accomplish user-defined objectives. To perform well on this benchmark, agents need to demonstrate capabilities in areas such as visual perception, language understanding, and task planning and execution.
The authors conduct an extensive evaluation of several state-of-the-art language models (LLMs), including multimodal models that can handle both text and images. Through quantitative and qualitative analysis, they identify significant limitations in the capabilities of these models for the visually-grounded web tasks in VisualWebArena. The results reveal gaps in the current state of autonomous agents and highlight the need for further research and development to build stronger agents for web-based tasks.
WorkarenaQ and MMINA are two other benchmarks mentioned in the paper that also focus on evaluating the capabilities of autonomous agents in web-based environments and multimodal tasks, respectively. These benchmarks, alongside VisualWebArena, provide a comprehensive set of tools for advancing research in this area.
Critical Analysis
The VisualWebArena benchmark represents a valuable contribution to the field of autonomous agent research, as it addresses an important gap in existing benchmarks by focusing on visually-grounded web tasks. By incorporating both visual and textual information, VisualWebArena more closely reflects the real-world challenges faced by agents operating in modern computer interfaces.
However, the paper does not provide detailed insights into the specific limitations of the evaluated models, beyond noting their overall struggles with the benchmark tasks. A more in-depth analysis of the model failures and the underlying reasons for their poor performance would be helpful for guiding future research and development efforts.
Additionally, the paper could have explored the potential impact of the identified capability gaps on real-world applications and the societal implications of building more capable autonomous web agents. Discussing these broader considerations would further strengthen the paper's contribution and appeal to a wider audience.
Overall, VisualWebArena represents an important step forward in the assessment of autonomous agent capabilities, and the insights gained from this research can inform the development of more robust and versatile agents for web-based tasks.
Conclusion
This paper introduces VisualWebArena, a new benchmark designed to evaluate the performance of autonomous agents on web-based tasks that require processing both visual and textual information. Existing benchmarks have primarily focused on text-based agents, neglecting many natural tasks that rely on visual inputs.
Through an extensive evaluation of state-of-the-art language models, including multimodal models, the researchers identified significant limitations in the current capabilities of autonomous agents for these visually-grounded web tasks. The VisualWebArena benchmark provides a valuable framework for further research and development to build stronger autonomous agents that can effectively navigate and interact with the web.
The insights gained from this work can inform the development of more robust and versatile autonomous agents, with the potential to enhance various real-world applications that involve web-based tasks and interactions. WorkarenaQ, MMINA, and OSWorld are additional benchmarks that can further contribute to this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig
0
0
With advances in generative AI, there is now potential for autonomous agents to manage daily tasks via natural language commands. However, current agents are primarily created and tested in simplified synthetic environments, leading to a disconnect with real-world scenarios. In this paper, we build an environment for language-guided agents that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on the web, and create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and designed to emulate tasks that humans routinely perform on the internet. We experiment with several baseline agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 14.41%, significantly lower than the human performance of 78.24%. These results highlight the need for further development of robust agents, that current state-of-the-art large language models are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress.
4/17/2024

WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, Dong Yu
0
0
The rapid advancement of large language models (LLMs) has led to a new era marked by the development of autonomous applications in real-world scenarios, which drives innovation in creating advanced web agents. Existing web agents typically only handle one input modality and are evaluated only in simplified web simulators or static web snapshots, greatly limiting their applicability in real-world scenarios. To bridge this gap, we introduce WebVoyager, an innovative Large Multimodal Model (LMM) powered web agent that can complete user instructions end-to-end by interacting with real-world websites. Moreover, we establish a new benchmark by compiling real-world tasks from 15 popular websites and introduce an automatic evaluation protocol leveraging multimodal understanding abilities of GPT-4V to evaluate open-ended web agents. We show that WebVoyager achieves a 59.1% task success rate on our benchmark, significantly surpassing the performance of both GPT-4 (All Tools) and the WebVoyager (text-only) setups, underscoring the exceptional capability of WebVoyager. The proposed automatic evaluation metric achieves 85.3% agreement with human judgment, indicating its effectiveness in providing reliable and accurate assessments of web agents.
6/10/2024

VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, Xiang Yue
0
0
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
4/10/2024
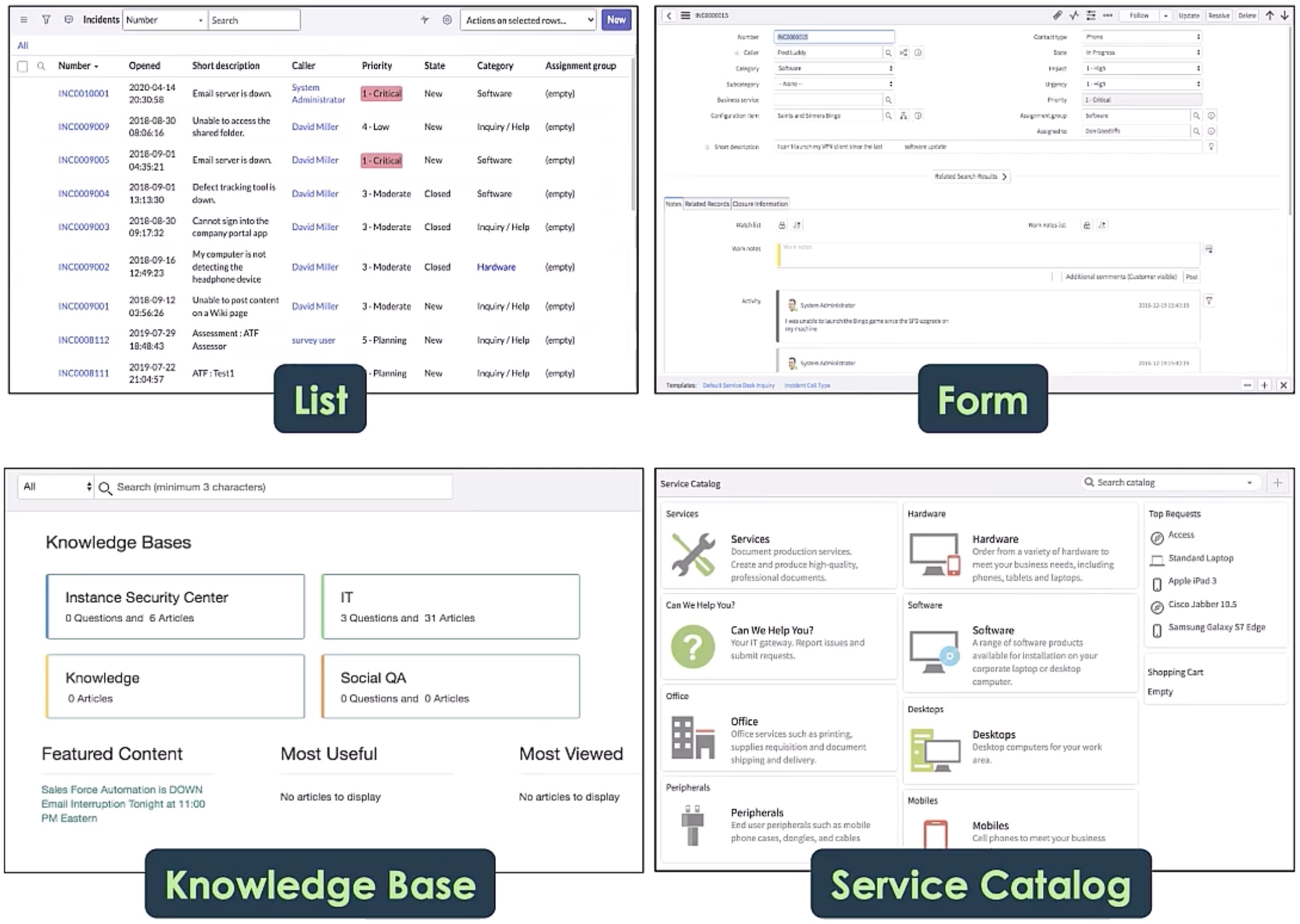
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, L'eo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, Alexandre Lacoste
0
0
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 33 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
6/18/2024