MMInA: Benchmarking Multihop Multimodal Internet Agents

0

Sign in to get full access
Overview
- This paper introduces the MMInA (Multihop Multimodal Internet Agents) benchmark, which aims to evaluate the capabilities of AI systems in navigating and interacting with the internet in a multimodal and multihop manner.
- The benchmark focuses on tasks that require agents to gather information from various online sources, reason about it, and generate coherent responses, while handling multimodal inputs and outputs.
- The goal is to drive progress in developing AI agents that can effectively leverage the vast resources available on the internet to assist humans in complex tasks.
Plain English Explanation
The paper describes a new benchmark called MMInA (Multihop Multimodal Internet Agents) that is designed to test the abilities of AI systems to navigate and interact with the internet in a more comprehensive way. Unlike some previous benchmarks that focused on specific tasks, MMInA challenges AI agents to gather information from various online sources, understand the connections between them, and generate meaningful responses, all while handling different types of media like text, images, and videos.
The key idea behind MMInA is to push the development of AI agents that can truly leverage the wealth of information available on the internet to assist humans with complex tasks. Instead of just searching for and retrieving specific pieces of information, these agents would need to understand the broader context, make inferences, and provide well-reasoned and multimodal outputs. This could lead to AI systems that are much more useful and versatile in real-world applications.
Technical Explanation
The MMInA benchmark consists of a set of tasks that require agents to navigate the internet, gather relevant information from multiple sources, and generate coherent responses that integrate insights from those sources. The tasks involve multimodal inputs and outputs, such as combining text, images, and videos to answer questions or complete open-ended prompts.
To develop the benchmark, the researchers curated a diverse dataset of internet resources, including web pages, images, and videos, and designed a suite of tasks that test an agent's ability to reason across these modalities and make connections between disparate pieces of information. The tasks cover a range of domains, from answering factual questions to generating creative story ideas, and are designed to be challenging for current state-of-the-art AI systems.
The paper also introduces an evaluation framework for MMInA, which includes both automated metrics and human-based assessments to measure the performance, robustness, and qualitative aspects of the agent responses. This multi-faceted evaluation approach aims to provide a more comprehensive understanding of the agent's capabilities and limitations.
Critical Analysis
The MMInA benchmark represents an important step forward in the field of AI and internet-based agents. By focusing on multihop, multimodal reasoning and generation, it addresses key limitations of existing benchmarks that tend to assess more narrow, single-task capabilities.
However, the paper acknowledges several challenges and limitations of the current MMInA setup. For example, the dataset and tasks may not fully capture the complexity and diversity of real-world internet-based interactions, and the evaluation metrics may not perfectly align with human judgments of task performance and usefulness.
Additionally, the paper does not provide a detailed analysis of the performance of existing AI systems on the MMInA benchmark, making it difficult to assess the current state of the art and the magnitude of the challenge posed by the benchmark.
Future work could explore ways to expand the benchmark's scope, refine the evaluation methods, and provide more comprehensive benchmarking results to better guide the development of robust and versatile internet-based AI agents.
Conclusion
The MMInA benchmark represents an important advancement in the field of AI and internet-based agents. By focusing on multihop, multimodal reasoning and generation, it challenges AI systems to leverage the vast resources available on the internet in a more comprehensive and useful way.
The development of AI agents that can effectively navigate and interact with the internet has the potential to significantly enhance human capabilities and productivity across a wide range of domains. The MMInA benchmark provides a valuable tool for driving progress in this direction and promoting the development of AI systems that can truly assist and empower humans in complex, real-world tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MMInA: Benchmarking Multihop Multimodal Internet Agents
Ziniu Zhang, Shulin Tian, Liangyu Chen, Ziwei Liu
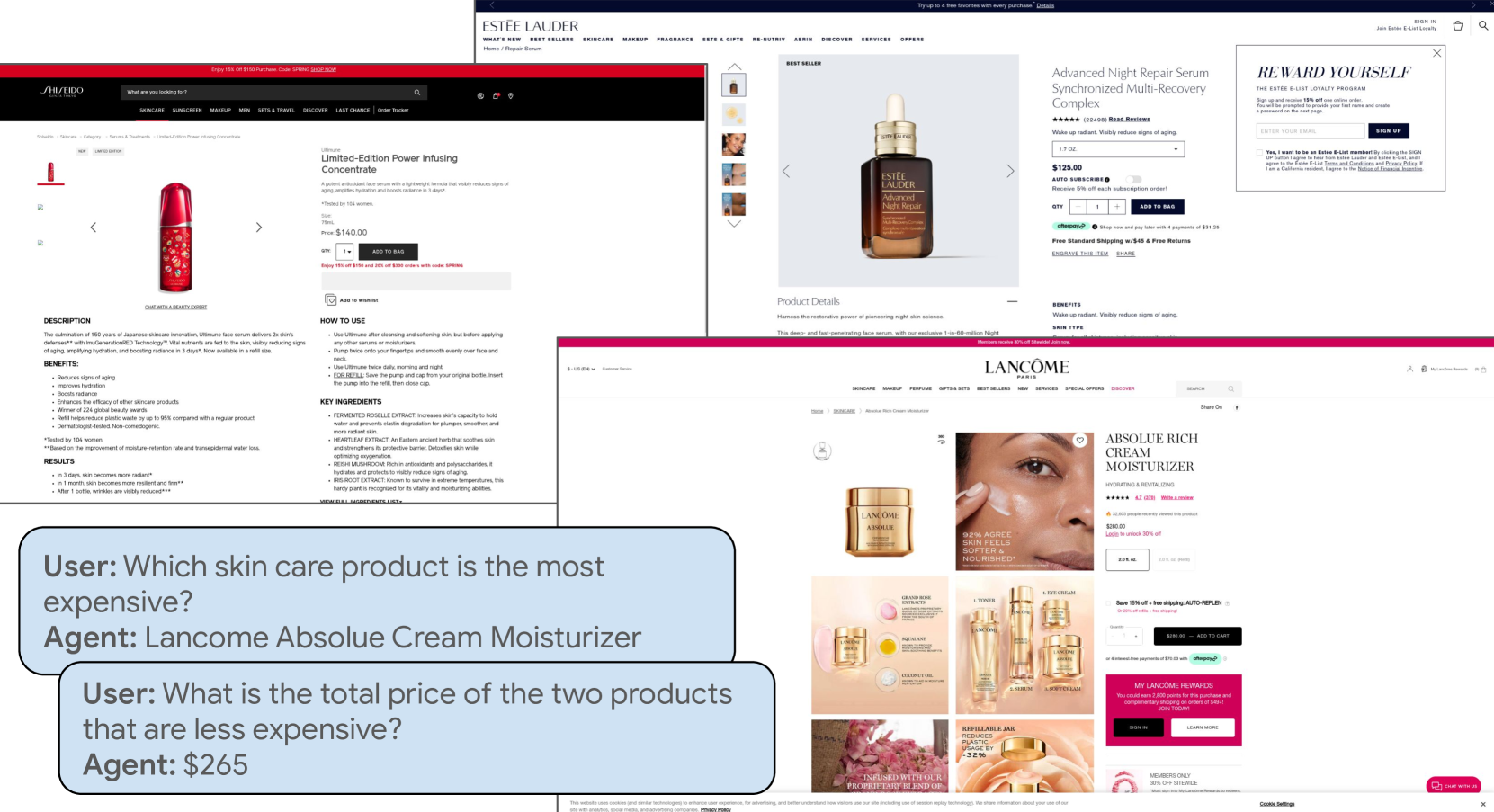
Autonomous embodied agents live on an Internet of multimedia websites. Can they hop around multimodal websites to complete complex user tasks? Existing benchmarks fail to assess them in a realistic, evolving environment for their embodiment across websites. To answer this question, we present MMInA, a multihop and multimodal benchmark to evaluate the embodied agents for compositional Internet tasks, with several appealing properties: 1) Evolving real-world multimodal websites. Our benchmark uniquely operates on evolving real-world websites, ensuring a high degree of realism and applicability to natural user tasks. Our data includes 1,050 human-written tasks covering various domains such as shopping and travel, with each task requiring the agent to autonomously extract multimodal information from web pages as observations; 2) Multihop web browsing. Our dataset features naturally compositional tasks that require information from or actions on multiple websites to solve, to assess long-range reasoning capabilities on web tasks; 3) Holistic evaluation. We propose a novel protocol for evaluating an agent's progress in completing multihop tasks. We experiment with both standalone (multimodal) language models and heuristic-based web agents. Extensive experiments demonstrate that while long-chain multihop web tasks are easy for humans, they remain challenging for state-of-the-art web agents. We identify that agents are more likely to fail on the early hops when solving tasks of more hops, which results in lower task success rates. To address this issue, we propose a simple memory augmentation approach replaying past action trajectories to reflect. Our method significantly improved both the single-hop and multihop web browsing abilities of agents. See our code and data at https://mmina.cliangyu.com
Read more4/16/2024
🏋️
0
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, Daniel Fried
Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic textit{visually grounded tasks}. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web. Our code, baseline models, and data is publicly available at https://jykoh.com/vwa.
Read more6/7/2024

0
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, Xiang Yue
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
Read more4/10/2024
0
WebQuest: A Benchmark for Multimodal QA on Web Page Sequences
Maria Wang, Srinivas Sunkara, Gilles Baechler, Jason Lin, Yun Zhu, Fedir Zubach, Lei Shu, Jindong Chen
The rise of powerful multimodal LLMs has enhanced the viability of building web agents which can, with increasing levels of autonomy, assist users to retrieve information and complete tasks on various human-computer interfaces. It is hence necessary to build challenging benchmarks that span a wide-variety of use cases reflecting real-world usage. In this work, we present WebQuest, a multi-page question-answering dataset that requires reasoning across multiple related web pages. In contrast to existing UI benchmarks that focus on multi-step web navigation and task completion, our dataset evaluates information extraction, multimodal retrieval and composition of information from many web pages. WebQuest includes three question categories: single-screen QA, multi-screen QA, and QA based on navigation traces. We evaluate leading proprietary multimodal models like GPT-4V, Gemini Flash, Claude 3, and open source models like InstructBLIP, PaliGemma on our dataset, revealing a significant gap between single-screen and multi-screen reasoning. Finally, we investigate inference time techniques like Chain-of-Thought prompting to improve model capabilities on multi-screen reasoning.
Read more9/26/2024