VIVID: Human-AI Collaborative Authoring of Vicarious Dialogues from Lecture Videos

0
Sign in to get full access
Overview
- This paper presents a system called "\sysname" that allows human-AI collaboration in creating vicarious dialogues from lecture videos.
- Vicarious learning involves observing others engage in a task or activity, and then learning from that experience.
- The \sysname system aims to facilitate vicarious learning by generating dialogues that simulate discussions between students and instructors based on lecture content.
- The system leverages large language models (LLMs) to assist human authors in crafting these dialogues, making the authoring process more efficient and scalable.
Plain English Explanation
The paper describes a tool called "\sysname" that helps create imaginary conversations based on lecture videos. The idea is that by watching these simulated discussions between students and instructors, people can learn the material in a more engaging and interactive way, even if they weren't able to attend the original lecture.
The tool uses powerful language models, which are AI systems trained on huge amounts of text data, to assist human authors in writing these dialogues. This makes the process of creating the dialogues faster and easier, allowing for more content to be generated. The goal is to provide an alternative way for people to learn from lecture videos, by imagining themselves as part of the discussion, rather than just passively watching.
Technical Explanation
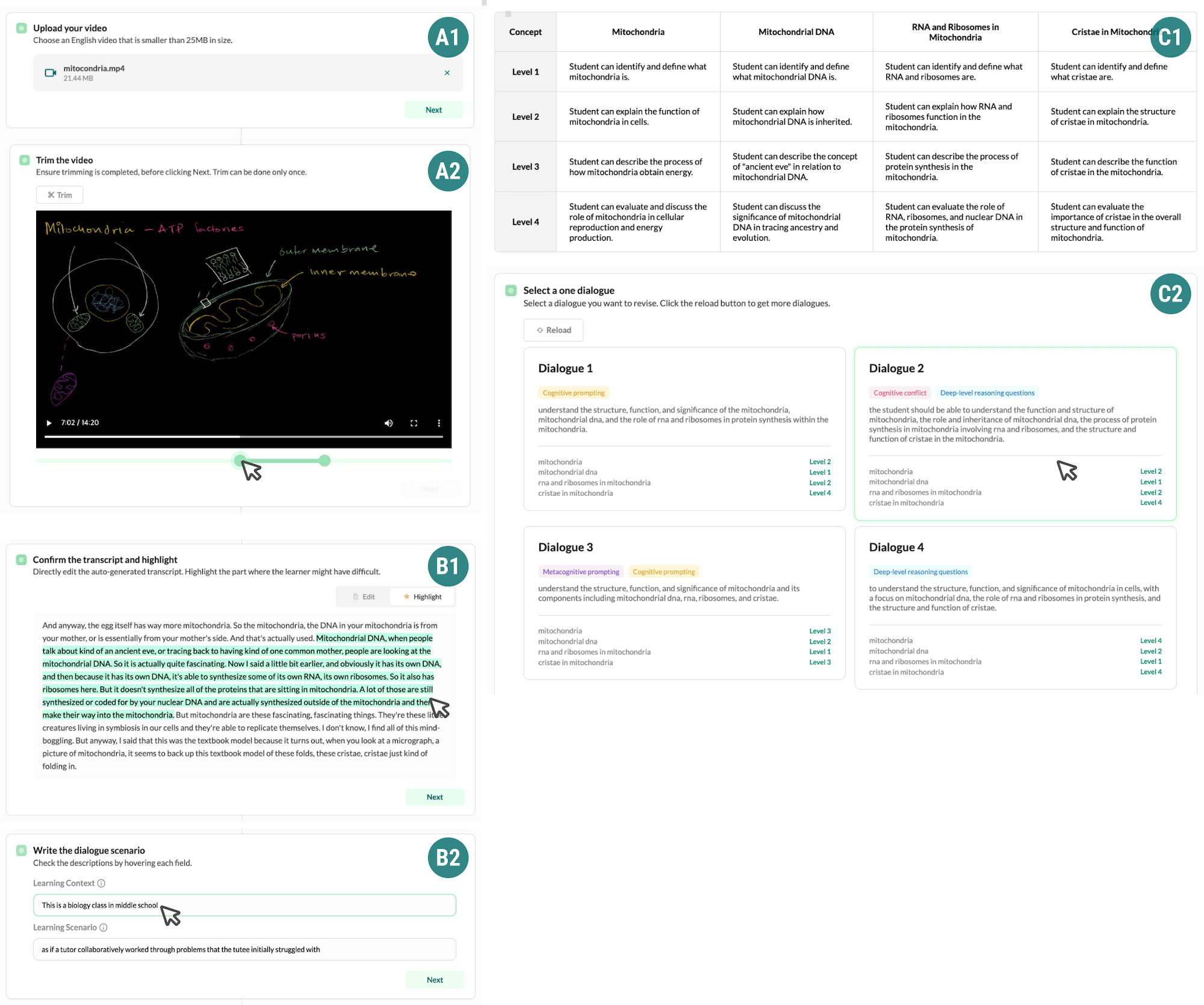
The \sysname system leverages large language models (LLMs) to support human authors in creating vicarious dialogues from lecture videos. The core architecture involves a human user interface that allows authors to upload lecture videos and collaboratively generate dialogues with the assistance of the LLM.
The system first transcribes the lecture video and extracts key concepts and talking points. The human author then interacts with the LLM to propose dialogue scenarios, character roles, and specific dialogue exchanges. The LLM generates draft dialogue content, which the human author can then refine and iterate on. This collaborative process allows the human and AI to work together to craft engaging, contextually-relevant conversations that simulate the learning experience.
The paper describes experiments evaluating the quality and usefulness of the generated dialogues, as perceived by both instructors and students. The results suggest that the \sysname system can effectively support the creation of vicarious learning content that enhances engagement and understanding of lecture material.
Critical Analysis
The \sysname system presents an intriguing approach to leveraging large language models to facilitate more immersive and interactive learning experiences from lecture videos. By generating simulated dialogues, the system aims to encourage vicarious learning, where students can observe and learn from the interactions between instructors and other students.
One potential limitation of the system is the reliance on the quality and capabilities of the underlying language model. As with any LLM-based system, the generated dialogues may exhibit biases, factual inaccuracies, or lack of coherence, which could undermine the learning experience. The authors note the importance of careful curation and refinement by human authors to address these issues.
Additionally, the evaluation of the system's effectiveness is based on subjective assessments by instructors and students. While these provide valuable insights, more rigorous and quantitative measures of learning outcomes could further validate the system's impact. Longitudinal studies tracking student performance and engagement could also shed light on the long-term benefits of vicarious learning through simulated dialogues.
Conclusion
The \sysname system represents a promising approach to enhancing the learning experience from lecture videos by generating simulated dialogues between students and instructors. By leveraging large language models to assist human authors, the system aims to make the creation of these vicarious learning resources more efficient and scalable.
If successful, the \sysname system could pave the way for more engaging and immersive learning experiences, where students can actively participate in discussions and observe the thought processes of their instructors and peers. As language models continue to advance, the potential for AI-assisted authoring tools like \sysname to transform educational content and delivery is an exciting area of research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VIVID: Human-AI Collaborative Authoring of Vicarious Dialogues from Lecture Videos
Seulgi Choi, Hyewon Lee, Yoonjoo Lee, Juho Kim
The lengthy monologue-style online lectures cause learners to lose engagement easily. Designing lectures in a vicarious dialogue format can foster learners' cognitive activities more than monologue-style. However, designing online lectures in a dialogue style catered to the diverse needs of learners is laborious for instructors. We conducted a design workshop with eight educational experts and seven instructors to present key guidelines and the potential use of large language models (LLM) to transform a monologue lecture script into pedagogically meaningful dialogue. Applying these design guidelines, we created VIVID which allows instructors to collaborate with LLMs to design, evaluate, and modify pedagogical dialogues. In a within-subjects study with instructors (N=12), we show that VIVID helped instructors select and revise dialogues efficiently, thereby supporting the authoring of quality dialogues. Our findings demonstrate the potential of LLMs to assist instructors with creating high-quality educational dialogues across various learning stages.
Read more4/11/2024

0
Designing and Evaluating Dialogue LLMs for Co-Creative Improvised Theatre
Boyd Branch, Piotr Mirowski, Kory Mathewson, Sophia Ppali, Alexandra Covaci
Social robotics researchers are increasingly interested in multi-party trained conversational agents. With a growing demand for real-world evaluations, our study presents Large Language Models (LLMs) deployed in a month-long live show at the Edinburgh Festival Fringe. This case study investigates human improvisers co-creating with conversational agents in a professional theatre setting. We explore the technical capabilities and constraints of on-the-spot multi-party dialogue, providing comprehensive insights from both audience and performer experiences with AI on stage. Our human-in-the-loop methodology underlines the challenges of these LLMs in generating context-relevant responses, stressing the user interface's crucial role. Audience feedback indicates an evolving interest for AI-driven live entertainment, direct human-AI interaction, and a diverse range of expectations about AI's conversational competence and utility as a creativity support tool. Human performers express immense enthusiasm, varied satisfaction, and the evolving public opinion highlights mixed emotions about AI's role in arts.
Read more5/14/2024

0
Is the Lecture Engaging for Learning? Lecture Voice Sentiment Analysis for Knowledge Graph-Supported Intelligent Lecturing Assistant (ILA) System
Yuan An, Samarth Kolanupaka, Jacob An, Matthew Ma, Unnat Chhatwal, Alex Kalinowski, Michelle Rogers, Brian Smith
This paper introduces an intelligent lecturing assistant (ILA) system that utilizes a knowledge graph to represent course content and optimal pedagogical strategies. The system is designed to support instructors in enhancing student learning through real-time analysis of voice, content, and teaching methods. As an initial investigation, we present a case study on lecture voice sentiment analysis, in which we developed a training set comprising over 3,000 one-minute lecture voice clips. Each clip was manually labeled as either engaging or non-engaging. Utilizing this dataset, we constructed and evaluated several classification models based on a variety of features extracted from the voice clips. The results demonstrate promising performance, achieving an F1-score of 90% for boring lectures on an independent set of over 800 test voice clips. This case study lays the groundwork for the development of a more sophisticated model that will integrate content analysis and pedagogical practices. Our ultimate goal is to aid instructors in teaching more engagingly and effectively by leveraging modern artificial intelligence techniques.
Read more8/21/2024
0
LUCID: LLM-Generated Utterances for Complex and Interesting Dialogues
Joe Stacey, Jianpeng Cheng, John Torr, Tristan Guigue, Joris Driesen, Alexandru Coca, Mark Gaynor, Anders Johannsen
Spurred by recent advances in Large Language Models (LLMs), virtual assistants are poised to take a leap forward in terms of their dialogue capabilities. Yet a major bottleneck to achieving genuinely transformative task-oriented dialogue capabilities remains the scarcity of high quality data. Existing datasets, while impressive in scale, have limited domain coverage and contain few genuinely challenging conversational phenomena; those which are present are typically unlabelled, making it difficult to assess the strengths and weaknesses of models without time-consuming and costly human evaluation. Moreover, creating high quality dialogue data has until now required considerable human input, limiting both the scale of these datasets and the ability to rapidly bootstrap data for a new target domain. We aim to overcome these issues with LUCID, a modularised and highly automated LLM-driven data generation system that produces realistic, diverse and challenging dialogues. We use LUCID to generate a seed dataset of 4,277 conversations across 100 intents to demonstrate its capabilities, with a human review finding consistently high quality labels in the generated data.
Read more5/6/2024