LUCID: LLM-Generated Utterances for Complex and Interesting Dialogues

0
Sign in to get full access
Overview
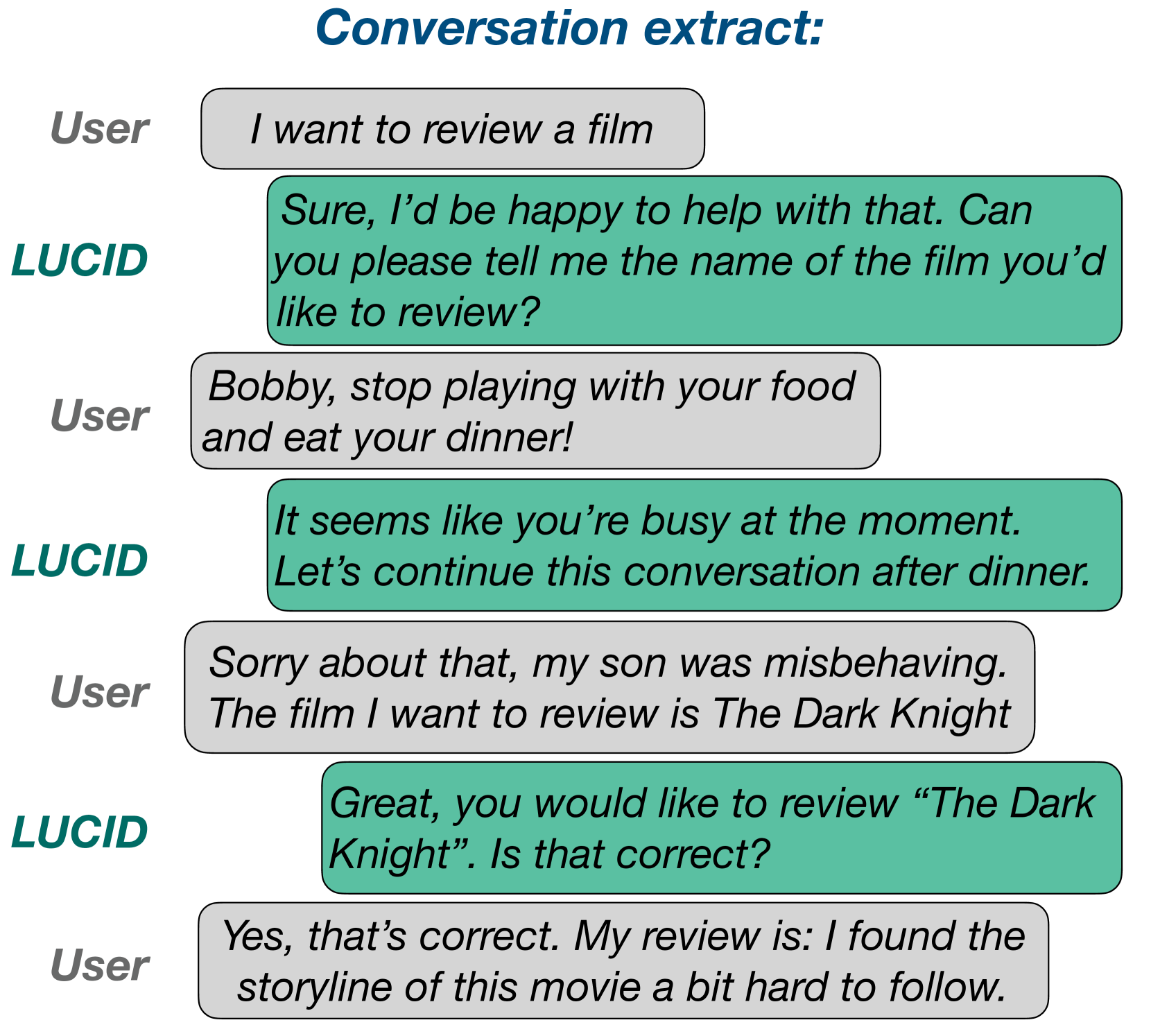
- This paper introduces LUCID, a dataset of LLM-generated utterances for complex and interesting dialogues.
- The dataset is designed to evaluate the capabilities of large language models (LLMs) in generating coherent and engaging dialogues.
- LUCID covers a variety of dialogue scenarios, from open-ended conversations to task-oriented interactions.
Plain English Explanation
The researchers created a new dataset called LUCID, which contains conversations generated by large language models (LLMs). LLMs are AI systems that can produce human-like text. The goal of LUCID is to help evaluate how well these LLMs can engage in complex and interesting dialogues, covering a range of topics and scenarios.
The DialogBench and Large Language User Interfaces datasets have explored LLM-generated dialogues before, but LUCID aims to be more comprehensive, with a greater diversity of dialogue contexts. This includes not just open-ended conversations, but also task-oriented interactions, like those seen in the Large Language Model Based Situational Dialogues dataset.
By having a wide variety of dialogue scenarios, the LUCID dataset can be used to rigorously test the language understanding and generation capabilities of LLMs. This is important as these models become more integrated into interactive systems, like the conversational avatars discussed in the Human Latency in Conversational Turns for Spoken Avatar Systems paper, or used for information seeking tasks.
Technical Explanation
The LUCID dataset consists of dialogues across a diverse set of scenarios, including open-ended conversations, task-oriented interactions, and mixed-initiative dialogues. To generate the dialogues, the researchers used a variety of large language models, including GPT-3, InstructGPT, and Chinchilla.
The dataset is structured with each dialogue represented as a sequence of utterances, along with metadata such as the speaker IDs, dialogue act labels, and topic annotations. This allows for fine-grained analysis of the linguistic qualities and task-completion abilities of the generated dialogues.
The researchers evaluated the LUCID dataset using both automatic metrics, such as perplexity and entailment scores, as well as human judgments on dimensions like coherence, informativeness, and engagement. The results showed that while current LLMs can generate fluent and relevant responses, they still struggle to maintain long-term coherence and engage in truly complex, open-ended dialogues.
Critical Analysis
The LUCID dataset represents a valuable contribution to the field of dialogue systems and language model evaluation. By including a wide range of dialogue scenarios, it provides a more comprehensive test bed for assessing the capabilities of LLMs.
However, the paper acknowledges that the dataset has some limitations. The dialogues are still relatively short and lack the depth and nuance of real-world conversations. Additionally, the researcher-generated prompts and scenarios may not fully capture the breadth of human conversational experience.
Further research is needed to explore more naturalistic dialogue generation, potentially by incorporating additional context, world knowledge, and social/emotional understanding into the language models. Integrating these capabilities will be crucial as LLMs become more widely deployed in interactive systems and virtual assistants.
Conclusion
The LUCID dataset provides a valuable benchmark for evaluating the dialogue generation capabilities of large language models. By covering a diverse set of scenarios, it highlights the strengths and limitations of current LLMs in maintaining coherence, informativeness, and engagement over the course of a conversation.
As LLMs continue to advance, the LUCID dataset can serve as a useful tool for driving progress in the field of dialogue systems and human-AI interaction. The insights from this research can inform the development of more natural, engaging, and task-oriented conversational interfaces that can better support human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!