VL4AD: Vision-Language Models Improve Pixel-wise Anomaly Detection

0
❗
Sign in to get full access
Overview
- Semantic segmentation networks have been successful, but struggle to detect anomalies from unknown classes.
- Anomaly segmentation often requires fine-tuning on outlier samples, which is time-consuming.
- This paper proposes incorporating Vision-Language (VL) encoders into anomaly detectors to leverage broad VL pre-training for improved outlier awareness.
- A new scoring function is introduced that enables data- and training-free outlier supervision via textual prompts.
- The resulting VL4AD model, including max-logit prompt ensembling and class-merging, achieves competitive performance on benchmark datasets.
Plain English Explanation
Semantic segmentation is a technique used in computer vision to label each pixel in an image with the object or scene it represents. Existing segmentation networks work well when the images they're trained on are similar to the ones they'll be tested on. However, they often struggle to identify anomalies - things that are completely different from the visual concepts they were trained on.
Traditionally, to improve anomaly detection, researchers would fine-tune the segmentation network on samples of anomalies. This involves collecting, labeling, and retraining the model - a lot of time-consuming work.
Instead, the researchers in this paper took a different approach. They incorporated vision-language (VL) encoders - models that have been trained on a vast amount of image and text data - into their anomaly detection system. This allowed them to leverage the broad semantic understanding that VL models develop during their extensive pre-training.
Additionally, the researchers developed a new scoring function that enables detecting anomalies without needing any labeled anomaly samples. This function uses textual prompts - short descriptions of what the model should be looking for - to provide supervision for the anomaly detection.
The resulting VL4AD model, which combines the VL encoder, prompt-based scoring, and some other techniques, was able to achieve strong performance on standard anomaly detection benchmarks. This demonstrates the potential of vision-language models for detecting visual anomalies without the need for laborious data collection and model retraining.
Technical Explanation
The researchers started with the observation that existing semantic segmentation networks often struggle to identify anomalies - objects or scenes that are vastly different from the visual concepts they were trained on. To address this, the researchers proposed incorporating vision-language (VL) encoders into an anomaly detection system.
VL encoders are deep learning models that have been trained on a massive amount of image-text data, giving them a broad understanding of the semantic relationships between visual and linguistic concepts. By leveraging this pre-trained VL knowledge, the researchers hypothesized that the anomaly detection system would be better equipped to recognize outliers.
In addition to the VL encoder, the researchers introduced a novel scoring function that allows for data- and training-free anomaly supervision. This function takes in a textual prompt - a short description of the desired output - and computes a score for each pixel indicating how well it matches the prompt. Pixels with low scores are then flagged as anomalies.
The complete VL4AD model includes several other techniques, such as max-logit prompt ensembling and a class-merging strategy, which further improve its anomaly detection capabilities. The researchers evaluated VL4AD on several benchmark datasets and found that it achieves competitive performance compared to other state-of-the-art anomaly segmentation methods.
Critical Analysis
One key advantage of the VL4AD approach is that it avoids the need for collecting and labeling anomaly samples, which is a time-consuming and often challenging task. By leveraging the broad semantic understanding of VL models and the prompt-based scoring function, the system can detect anomalies without any additional data or training.
However, the researchers do acknowledge some limitations of their work. For example, the performance of VL4AD is still somewhat dependent on the quality and relevance of the textual prompts provided. Additionally, the model may struggle to detect anomalies that are very different from the visual concepts it has been exposed to during pre-training.
Further research could explore ways to make the prompt-based anomaly scoring more robust and less reliant on manual curation. Incorporating reinforcement learning techniques to automatically generate effective prompts could be one potential direction. Investigating how different VL model architectures and pre-training strategies affect anomaly detection performance would also be valuable.
Overall, the VL4AD work demonstrates the potential of vision-language models for anomaly detection and provides a promising alternative to traditional fine-tuning-based approaches.
Conclusion
This paper presents a novel approach to anomaly segmentation that leverages vision-language (VL) encoders and a prompt-based scoring function to detect outliers without the need for labeled anomaly samples or extensive model retraining.
The resulting VL4AD model achieves competitive performance on standard anomaly detection benchmarks, showcasing the potential of VL models for this task. By avoiding the cumbersome data collection and fine-tuning process, the VL4AD approach offers a more efficient and scalable solution for identifying anomalies in various computer vision applications.
While the method has some limitations, the work highlights the value of incorporating broad semantic understanding from VL pre-training to improve anomaly detection, and suggests exciting avenues for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
VL4AD: Vision-Language Models Improve Pixel-wise Anomaly Detection
Liangyu Zhong, Joachim Sicking, Fabian Huger, Hanno Gottschalk
Semantic segmentation networks have achieved significant success under the assumption of independent and identically distributed data. However, these networks often struggle to detect anomalies from unknown semantic classes due to the limited set of visual concepts they are typically trained on. To address this issue, anomaly segmentation often involves fine-tuning on outlier samples, necessitating additional efforts for data collection, labeling, and model retraining. Seeking to avoid this cumbersome work, we take a different approach and propose to incorporate Vision-Language (VL) encoders into existing anomaly detectors to leverage the semantically broad VL pre-training for improved outlier awareness. Additionally, we propose a new scoring function that enables data- and training-free outlier supervision via textual prompts. The resulting VL4AD model, which includes max-logit prompt ensembling and a class-merging strategy, achieves competitive performance on widely used benchmark datasets, thereby demonstrating the potential of vision-language models for pixel-wise anomaly detection.
Read more9/27/2024
0
Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
Jiaqi Zhu, Shaofeng Cai, Fang Deng, Beng Chin Ooi, Junran Wu
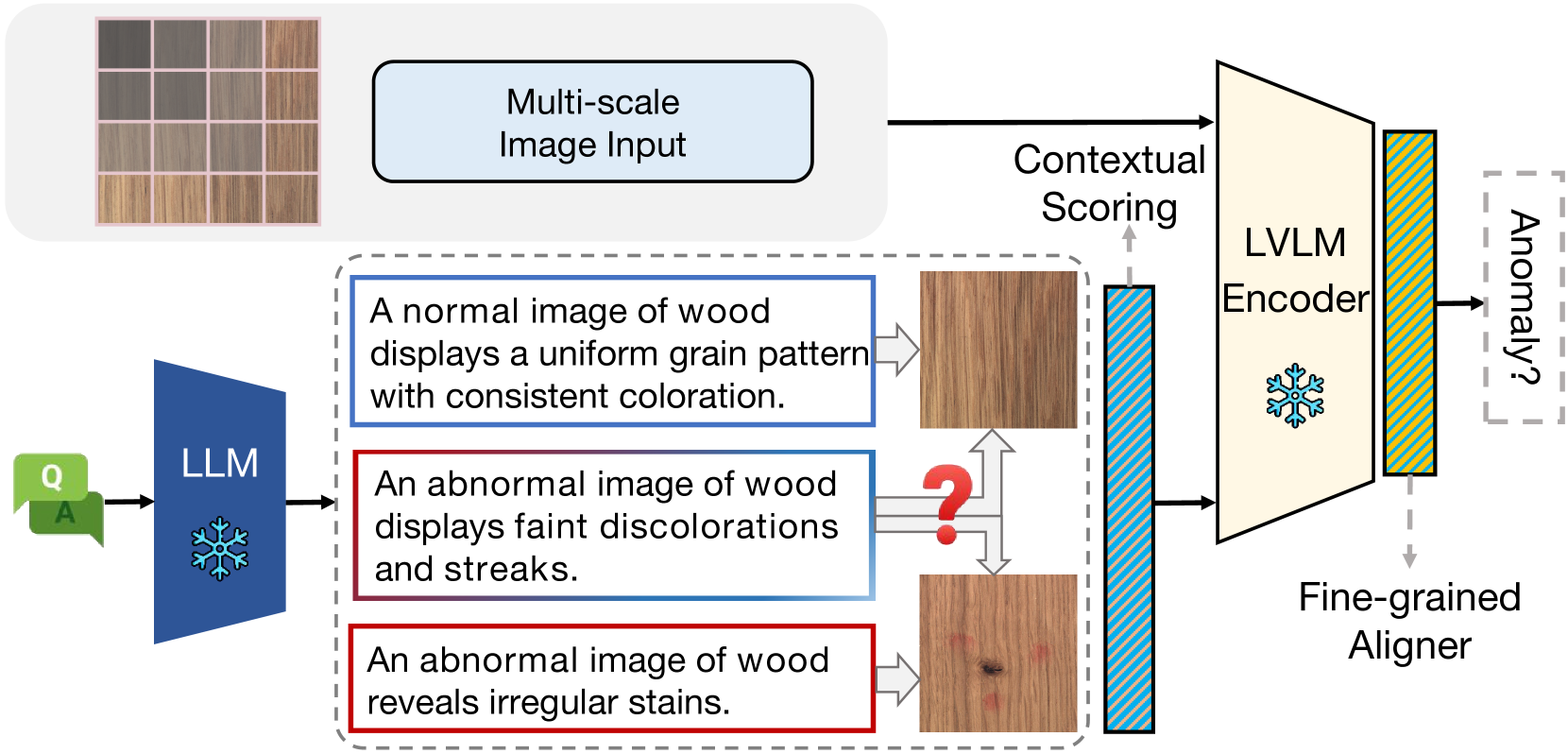
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec and 8.9% on VisA compared to state-of-the-art approaches.
Read more9/11/2024
0
Video Anomaly Detection in 10 Years: A Survey and Outlook
Moshira Abdalla, Sajid Javed, Muaz Al Radi, Anwaar Ulhaq, Naoufel Werghi
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
Read more7/2/2024

0
Human-free Prompted Based Anomaly Detection: prompt optimization with Meta-guiding prompt scheme
Pi-Wei Chen, Jerry Chun-Wei Lin, Jia Ji, Feng-Hao Yeh, Zih-Ching Chen, Chao-Chun Chen
Pre-trained vision-language models (VLMs) are highly adaptable to various downstream tasks through few-shot learning, making prompt-based anomaly detection a promising approach. Traditional methods depend on human-crafted prompts that require prior knowledge of specific anomaly types. Our goal is to develop a human-free prompt-based anomaly detection framework that optimally learns prompts through data-driven methods, eliminating the need for human intervention. The primary challenge in this approach is the lack of anomalous samples during the training phase. Additionally, the Vision Transformer (ViT)-based image encoder in VLMs is not ideal for pixel-wise anomaly segmentation due to a locality feature mismatch between the original image and the output feature map. To tackle the first challenge, we have developed the Object-Attention Anomaly Generation Module (OAGM) to synthesize anomaly samples for training. Furthermore, our Meta-Guiding Prompt-Tuning Scheme (MPTS) iteratively adjusts the gradient-based optimization direction of learnable prompts to avoid overfitting to the synthesized anomalies. For the second challenge, we propose Locality-Aware Attention, which ensures that each local patch feature attends only to nearby patch features, preserving the locality features corresponding to their original locations. This framework allows for the optimal prompt embeddings by searching in the continuous latent space via backpropagation, free from human semantic constraints. Additionally, the modified locality-aware attention improves the precision of pixel-wise anomaly segmentation.
Read more9/12/2024