Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection

0
Sign in to get full access
Overview
• This paper explores whether large language models (LLMs) can understand visual anomalies, which are unusual or unexpected elements in images. The researchers investigate the zero-shot anomaly detection capabilities of LLMs, meaning the models' ability to detect anomalies without being explicitly trained on that task.
Plain English Explanation
• The paper examines whether powerful language models like GPT-3 and CLIP can recognize when an image contains something unusual or out of the ordinary, even if they haven't been shown examples of anomalies before.
• The researchers wanted to see if these large language models, which are trained on a vast amount of text data, could leverage their understanding of language and visual concepts to spot anomalies in images in a "zero-shot" setting - without any special training on anomaly detection.
• This is an interesting capability, as being able to identify unusual elements in images could have many practical applications, like detecting defects in manufacturing or identifying potentially harmful objects.
Technical Explanation
• The researchers conducted a series of experiments to evaluate the zero-shot anomaly detection capabilities of various LLMs, including GPT-3, CLIP, and Improved Zero-Shot Classification.
• They assembled a dataset of images containing visual anomalies, such as unexpected objects or unusual arrangements. The models were then prompted to classify each image as containing an anomaly or not.
• The results showed that the LLMs were surprisingly effective at this zero-shot anomaly detection task, often outperforming specialized anomaly detection algorithms. The models seemed to leverage their broad understanding of visual concepts and language to identify the anomalies.
Critical Analysis
• The paper acknowledges that the LLMs' performance was not perfect, and their anomaly detection abilities may be limited to certain types of anomalies or visual domains. More research is needed to fully understand the scope and limitations of this capability.
• Additionally, the paper does not explore how the LLMs arrive at their anomaly predictions or what specific visual cues they are using. Further analysis of the model's internal representations and decision-making process could provide valuable insights.
• Overall, the findings suggest that LLMs have surprising capabilities in zero-shot visual anomaly detection, but more work is needed to understand the practical implications and potential applications of this technology.
Conclusion
• This research demonstrates that large language models can exhibit impressive zero-shot anomaly detection capabilities, suggesting they have a deeper understanding of visual concepts than previously thought.
• These findings could pave the way for new applications of LLMs in areas like quality control, safety, and security, where the ability to quickly identify unusual or potentially problematic elements in images could be highly valuable.
• However, the limitations and underlying mechanisms of this capability require further exploration to fully harness the potential of LLMs in visual anomaly detection tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
Jiaqi Zhu, Shaofeng Cai, Fang Deng, Beng Chin Ooi, Junran Wu
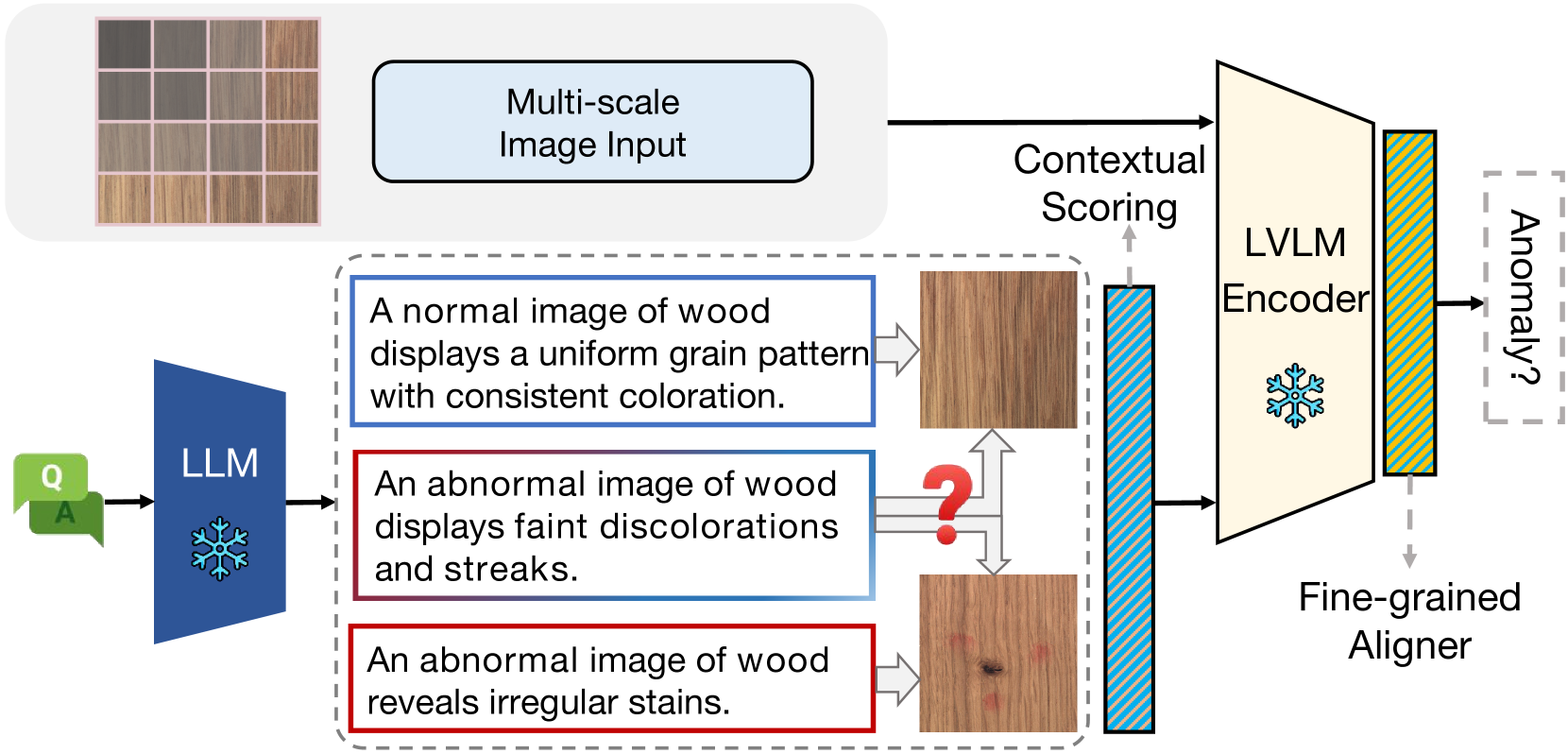
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec and 8.9% on VisA compared to state-of-the-art approaches.
Read more9/11/2024

0
Zero-Shot Visual Reasoning by Vision-Language Models: Benchmarking and Analysis
Aishik Nagar, Shantanu Jaiswal, Cheston Tan
Vision-language models (VLMs) have shown impressive zero- and few-shot performance on real-world visual question answering (VQA) benchmarks, alluding to their capabilities as visual reasoning engines. However, the benchmarks being used conflate pure visual reasoning with world knowledge, and also have questions that involve a limited number of reasoning steps. Thus, it remains unclear whether a VLM's apparent visual reasoning performance is due to its world knowledge, or due to actual visual reasoning capabilities. To clarify this ambiguity, we systematically benchmark and dissect the zero-shot visual reasoning capabilities of VLMs through synthetic datasets that require minimal world knowledge, and allow for analysis over a broad range of reasoning steps. We focus on two novel aspects of zero-shot visual reasoning: i) evaluating the impact of conveying scene information as either visual embeddings or purely textual scene descriptions to the underlying large language model (LLM) of the VLM, and ii) comparing the effectiveness of chain-of-thought prompting to standard prompting for zero-shot visual reasoning. We find that the underlying LLMs, when provided textual scene descriptions, consistently perform better compared to being provided visual embeddings. In particular, 18% higher accuracy is achieved on the PTR dataset. We also find that CoT prompting performs marginally better than standard prompting only for the comparatively large GPT-3.5-Turbo (175B) model, and does worse for smaller-scale models. This suggests the emergence of CoT abilities for visual reasoning in LLMs at larger scales even when world knowledge is limited. Overall, we find limitations in the abilities of VLMs and LLMs for more complex visual reasoning, and highlight the important role that LLMs can play in visual reasoning.
Read more9/4/2024

0
Multimodal Misinformation Detection using Large Vision-Language Models
Sahar Tahmasebi, Eric Muller-Budack, Ralph Ewerth
The increasing proliferation of misinformation and its alarming impact have motivated both industry and academia to develop approaches for misinformation detection and fact checking. Recent advances on large language models (LLMs) have shown remarkable performance in various tasks, but whether and how LLMs could help with misinformation detection remains relatively underexplored. Most of existing state-of-the-art approaches either do not consider evidence and solely focus on claim related features or assume the evidence to be provided. Few approaches consider evidence retrieval as part of the misinformation detection but rely on fine-tuning models. In this paper, we investigate the potential of LLMs for misinformation detection in a zero-shot setting. We incorporate an evidence retrieval component into the process as it is crucial to gather pertinent information from various sources to detect the veracity of claims. To this end, we propose a novel re-ranking approach for multimodal evidence retrieval using both LLMs and large vision-language models (LVLM). The retrieved evidence samples (images and texts) serve as the input for an LVLM-based approach for multimodal fact verification (LVLM4FV). To enable a fair evaluation, we address the issue of incomplete ground truth for evidence samples in an existing evidence retrieval dataset by annotating a more complete set of evidence samples for both image and text retrieval. Our experimental results on two datasets demonstrate the superiority of the proposed approach in both evidence retrieval and fact verification tasks and also better generalization capability across dataset compared to the supervised baseline.
Read more7/22/2024

0
The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
Read more5/24/2024