VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition

0

Sign in to get full access
Overview
- This paper proposes VLM-KD, a method for distilling knowledge from large vision-language models (VLMs) to improve the performance of long-tail visual recognition tasks.
- The key idea is to leverage the rich semantic knowledge captured by VLMs to guide the training of compact models for long-tail visual recognition.
- VLM-KD outperforms prior knowledge distillation approaches on several long-tail visual recognition benchmarks.
Plain English Explanation
Visual recognition models trained on large datasets often struggle to classify objects or scenes that are less common or "long-tail" in the dataset. VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition proposes a way to improve the performance of these models on long-tail visual recognition tasks.
The key innovation is to "distill" or transfer the knowledge from large, powerful vision-language models (VLMs) to smaller, more specialized models. VLMs are trained on massive amounts of image and text data, allowing them to build rich semantic representations of visual concepts. VLM-KD leverages this knowledge to guide the training of compact models for long-tail visual recognition.
By distilling the knowledge from VLMs, the compact models are able to better recognize and classify rare or unusual visual objects and scenes, improving their overall performance on long-tail visual recognition tasks. This approach outperforms previous knowledge distillation methods on several benchmark datasets.
Technical Explanation
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition introduces a new knowledge distillation technique to improve the performance of compact models on long-tail visual recognition tasks.
The core idea is to leverage the rich semantic knowledge captured by large vision-language models (VLMs) to guide the training of specialized models for long-tail visual recognition. VLMs are trained on massive datasets of images and text, allowing them to build powerful representations of visual concepts. VLM-KD distills this knowledge into smaller, more efficient models.
The authors propose two key components of VLM-KD:
- VLM Feature Distillation: The compact model is trained to mimic the intermediate feature representations of the VLM, allowing it to learn the VLM's semantic understanding of visual concepts.
- VLM-guided Classifier Training: The compact model's classifier layer is trained using the VLM's predictions as "soft targets", further aligning the model's outputs with the VLM's knowledge.
VLM-KD is evaluated on several long-tail visual recognition benchmarks, including iNaturalist and Places-LT. The results show that VLM-KD outperforms previous knowledge distillation methods, improving the compact model's performance on rare and unusual visual classes.
Critical Analysis
The key strength of VLM-KD is its ability to leverage the rich semantic knowledge of large VLMs to enhance the performance of compact models on long-tail visual recognition tasks. By distilling this knowledge, the compact models are able to better recognize and classify rare or unusual visual concepts.
However, the paper does not fully address the potential limitations of this approach. For example, the authors do not discuss the computational overhead or memory requirements of incorporating the VLM into the training pipeline, which could be a significant practical concern. Additionally, the paper does not explore the generalization of VLM-KD to other types of compact models or task domains beyond visual recognition.
Further research could investigate ways to make the VLM-KD process more efficient or explore its applicability to other areas of machine learning. It would also be valuable to understand the potential biases or limitations of the VLM knowledge being distilled and how that might impact the compact model's performance.
Conclusion
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition presents a promising approach for improving the performance of compact models on long-tail visual recognition tasks. By distilling the rich semantic knowledge of large vision-language models, VLM-KD enables compact models to better recognize and classify rare or unusual visual concepts.
This work highlights the potential of leveraging the capabilities of powerful models to enhance the performance of more specialized and efficient models, which could have important implications for a wide range of real-world applications. As machine learning models become increasingly complex and capable, techniques like VLM-KD may play a key role in democratizing access to advanced AI capabilities and unlocking new possibilities in areas like computer vision, natural language processing, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Zaiwei Zhang, Gregory P. Meyer, Zhichao Lu, Ashish Shrivastava, Avinash Ravichandran, Eric M. Wolff
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
Read more9/2/2024
0
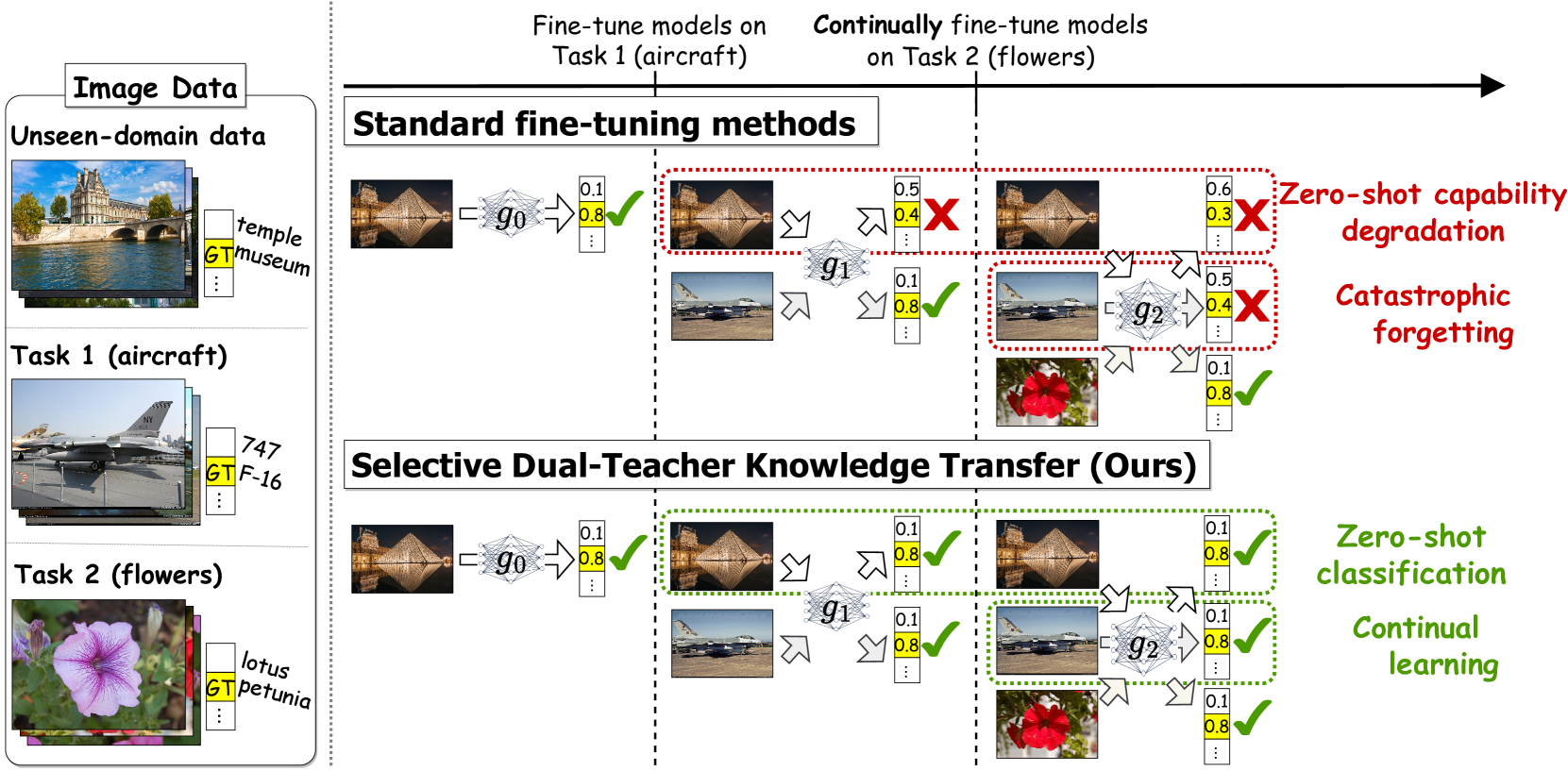
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
Yu-Chu Yu, Chi-Pin Huang, Jr-Jen Chen, Kai-Po Chang, Yung-Hsuan Lai, Fu-En Yang, Yu-Chiang Frank Wang
Large-scale vision-language models (VLMs) have shown a strong zero-shot generalization capability on unseen-domain data. However, adapting pre-trained VLMs to a sequence of downstream tasks often leads to the forgetting of previously learned knowledge and a reduction in zero-shot classification performance. To tackle this problem, we propose a unique Selective Dual-Teacher Knowledge Transfer framework that leverages the most recent fine-tuned and the original pre-trained VLMs as dual teachers to preserve the previously learned knowledge and zero-shot capabilities, respectively. With only access to an unlabeled reference dataset, our proposed framework performs a selective knowledge distillation mechanism by measuring the feature discrepancy from the dual-teacher VLMs. Consequently, our selective dual-teacher knowledge distillation mitigates catastrophic forgetting of previously learned knowledge while preserving the zero-shot capabilities of pre-trained VLMs. Extensive experiments on benchmark datasets demonstrate that our framework is favorable against state-of-the-art continual learning approaches for preventing catastrophic forgetting and zero-shot degradation. Project page: https://chuyu.org/research/snd
Read more7/18/2024
🔮
0
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jordy Van Landeghem, Subhajit Maity, Ayan Banerjee, Matthew Blaschko, Marie-Francine Moens, Josep Llad'os, Sanket Biswas
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
Read more6/13/2024

0
MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
Read more4/11/2024