DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
2406.08226
0
0
🔮
Abstract
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
Create account to get full access
Overview
- This paper explores the use of knowledge distillation (KD) for improving the efficiency of visually-rich document (VRD) applications, such as document layout analysis (DLA) and document image classification (DIC).
- The researchers designed a KD experimentation methodology to create more lean and performant models for document understanding (DU) tasks, which are crucial components within larger task pipelines.
- The study investigates different KD strategies, including response-based and feature-based approaches, for distilling knowledge between backbone models with varying architectures (ResNet, ViT, DiT) and capacities (base, small, tiny).
- The paper examines factors that affect the teacher-student knowledge gap and finds that some KD methods can outperform supervised student training.
- The researchers also evaluate the robustness of distilled DLA models on a downstream task, zero-shot layout-aware document visual question answering (DocVQA), to assess covariate shift.
Plain English Explanation
The paper focuses on making document-related AI models more efficient and easier to use. Many of these models are becoming increasingly complex and cumbersome, which can make them difficult to deploy in real-world applications. The researchers investigate a technique called knowledge distillation to address this issue.
Knowledge distillation involves training a smaller, more efficient "student" model to mimic the behavior of a larger, more sophisticated "teacher" model. The researchers experimented with different strategies for transferring knowledge from the teacher to the student, such as matching the outputs or internal features of the models.
They found that some of these knowledge distillation methods can produce student models that outperform those trained from scratch, even though the student models are much smaller and simpler. This suggests that knowledge distillation can be an effective way to create more efficient document understanding models without sacrificing too much performance.
The researchers also looked at how well the distilled models perform on a specific downstream task, document visual question answering. This allowed them to assess the models' ability to maintain their understanding of document layout and structure, even when applied to new situations.
Overall, this work highlights the potential of knowledge distillation to make visually-rich document AI systems more practical and accessible, by developing smaller and more efficient models without losing critical capabilities.
Technical Explanation
The paper explores the use of knowledge distillation (KD) to improve the efficiency of visually-rich document (VRD) applications, such as document layout analysis (DLA) and document image classification (DIC). While VRD research has increasingly relied on sophisticated and complex models, the field has not adequately studied model compression techniques to improve efficiency.
The researchers designed a KD experimentation methodology to create more lean and performant models for document understanding (DU) tasks, which are integral components within larger task pipelines. They carefully selected KD strategies, including response-based (e.g., vanilla KD, knowledge distillation for LLMs and automatic scoring) and feature-based (e.g., SimKD with an appropriate projector) approaches, for distilling knowledge between backbone models with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny).
The study investigates factors that affect the teacher-student knowledge gap and finds that some KD methods, such as tuned vanilla KD, MSE, and SimKD with an apt projector, can consistently outperform supervised student training. Furthermore, the researchers designed downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). The DLA-KD experiments resulted in a large mAP knowledge gap, which unpredictably translates to downstream robustness, highlighting the need for further exploration on how to efficiently obtain more semantic document layout awareness.
Critical Analysis
The paper presents a thorough exploration of knowledge distillation techniques for improving the efficiency of visually-rich document AI models. The researchers' design of a KD experimentation methodology and their careful selection of KD strategies are commendable. The finding that some KD methods can outperform supervised student training is a promising result, suggesting that knowledge distillation can be an effective way to create more efficient document understanding models without sacrificing too much performance.
However, the paper also highlights the challenges in translating the improvements in the primary task (DLA) to downstream robustness, as seen in the unpredictable results on the zero-shot layout-aware DocVQA task. This accentuates the need for further research on how to ensure that the distilled models maintain a more comprehensive and semantic understanding of document layout, which is crucial for their application in larger task pipelines.
Additionally, the paper does not provide much detail on the specific architectural choices and hyperparameter tuning for the various KD strategies explored. More information on these aspects could help researchers and practitioners better understand the factors that contribute to the observed performance differences.
Overall, this work makes a valuable contribution to the field of visually-rich document AI by demonstrating the potential of knowledge distillation to improve model efficiency. The insights and lessons learned from this study can inform future research aimed at developing more robust and practical document understanding systems.
Conclusion
This paper explores the use of knowledge distillation to improve the efficiency of visually-rich document (VRD) AI models, such as those used for document layout analysis and document image classification. The researchers designed a KD experimentation methodology to create more lean and performant models for document understanding tasks, which are crucial components within larger task pipelines.
The study investigates various KD strategies, including response-based and feature-based approaches, for distilling knowledge between backbone models with different architectures and capacities. The findings indicate that some KD methods can consistently outperform supervised student training, suggesting that knowledge distillation can be an effective way to develop more efficient document understanding models without significant performance degradation.
However, the paper also highlights the challenge of maintaining the models' semantic understanding of document layout when applying them to downstream tasks, which is an area that requires further exploration. Addressing this issue could lead to the development of more robust and practical visually-rich document AI systems that can be more easily deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
A Comprehensive Review of Knowledge Distillation in Computer Vision
Sheikh Musa Kaleem, Tufail Rouf, Gousia Habib, Tausifa jan Saleem, Brejesh Lall
0
0
Deep learning techniques have been demonstrated to surpass preceding cutting-edge machine learning techniques in recent years, with computer vision being one of the most prominent examples. However, deep learning models suffer from significant drawbacks when deployed in resource-constrained environments due to their large model size and high complexity. Knowledge Distillation is one of the prominent solutions to overcome this challenge. This review paper examines the current state of research on knowledge distillation, a technique for compressing complex models into smaller and simpler ones. The paper provides an overview of the major principles and techniques associated with knowledge distillation and reviews the applications of knowledge distillation in the domain of computer vision. The review focuses on the benefits of knowledge distillation, as well as the problems that must be overcome to improve its effectiveness.
4/9/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024
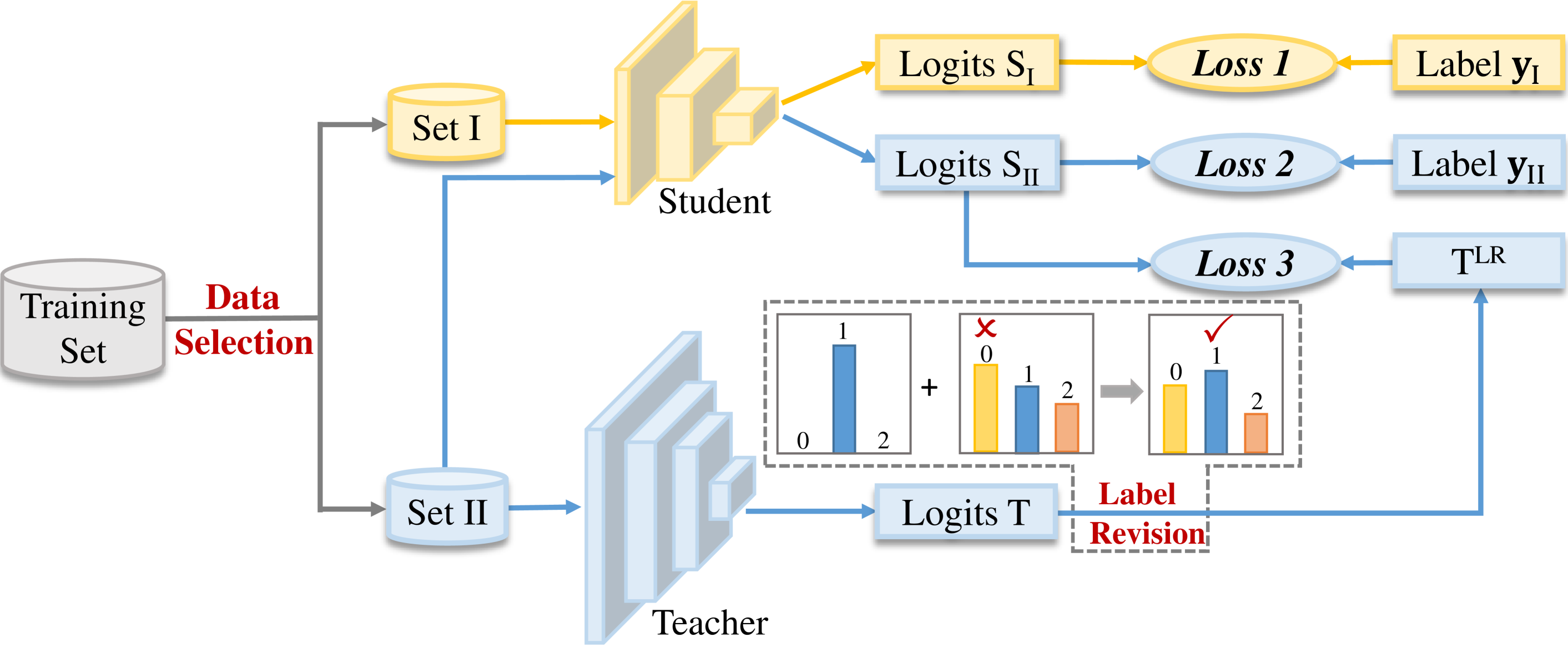
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024

Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jinyin Chen, Xiaoming Zhao, Haibin Zheng, Xiao Li, Sheng Xiang, Haifeng Guo
0
0
Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
6/6/2024