VLM's Eye Examination: Instruct and Inspect Visual Competency of Vision Language Models

0

Sign in to get full access
Overview
- Provides a dataset called LENS for evaluating visual competency of vision language models (VLMs)
- Proposes a framework for instructing and inspecting VLMs' visual capabilities
- Aims to assess whether VLMs can follow visual instructions and reason about visual concepts
Plain English Explanation
The research paper introduces a dataset called LENS (Language-Enabled Noticing of Scenes) to evaluate the visual competency of vision language models (VLMs). VLMs are AI models that can understand and process both textual and visual information.
The key idea is to use LENS to instruct VLMs to perform specific visual tasks, such as finding an object in an image or reasoning about visual relationships. This allows researchers to assess whether the VLMs can accurately follow the instructions and demonstrate a true understanding of the visual concepts, rather than just memorizing associations between images and text.
By testing VLMs in this way, the researchers aim to gain insights into the models' underlying visual competencies and limitations. This can help guide the development of more robust and capable VLMs that can reliably interact with the visual world.
Technical Explanation
The paper presents the LENS dataset, which consists of visual scenes with associated natural language instructions. The instructions ask the VLM to perform various tasks, such as identifying specific objects, describing relationships between elements, or explaining visual reasoning.
The researchers evaluate VLMs on their ability to accurately follow the instructions and provide correct responses. This is done through a combination of automatic metrics (e.g., instruction-following accuracy) and human evaluation (e.g., assessing the quality and relevance of the VLM's outputs).
The paper also explores different approaches to instructing VLMs, such as using prompts with varying levels of detail and complexity. This helps understand the boundaries of the models' visual understanding and their ability to generalize beyond the training data.
Critical Analysis
The paper recognizes that the LENS dataset and evaluation framework are an initial step in understanding VLM capabilities, and there are several limitations to consider:
- The dataset may not capture the full breadth of visual reasoning tasks that VLMs are expected to handle in real-world applications.
- The evaluation metrics may not fully capture the nuances of visual understanding and may miss important aspects of model performance.
- The research is focused on a specific set of VLM architectures and training approaches, and the findings may not generalize to other models or future developments in the field.
The authors encourage further research to expand the dataset, explore alternative evaluation methodologies, and investigate the visual competencies of a wider range of VLM architectures and training approaches.
Conclusion
This research paper introduces the LENS dataset and a framework for instructing and inspecting the visual competency of VLMs. By evaluating VLMs on their ability to follow visual instructions and reason about visual concepts, the researchers aim to gain deeper insights into the models' underlying capabilities and limitations.
The findings from this work can inform the development of more robust and capable VLMs, which have the potential to enable more natural and effective human-AI interaction in a wide range of applications, from assistive technologies to creative tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VLM's Eye Examination: Instruct and Inspect Visual Competency of Vision Language Models
Nam Hyeon-Woo, Moon Ye-Bin, Wonseok Choi, Lee Hyun, Tae-Hyun Oh
Vision language models (VLMs) have shown promising reasoning capabilities across various benchmarks; however, our understanding of their visual perception remains limited. In this work, we propose an eye examination process to investigate how a VLM perceives images, specifically focusing on key elements of visual recognition, from primitive color and shape to semantic levels. To this end, we introduce a dataset named LENS to guide a VLM to follow the examination and check its readiness. Once the model is ready, we conduct the examination. Through this examination, we quantify and visualize VLMs' sensitivities to color and shape, and semantic matching. Our findings reveal that VLMs have varying sensitivity to different colors while consistently showing insensitivity to green across different VLMs. Also, we found different shape sensitivity and semantic recognition depending on LLM's capacity despite using the same fixed visual encoder. Our analyses and findings have potential to inspire the design of VLMs and the pre-processing of visual input to VLMs for improving application performance.
Read more9/24/2024
💬
0
Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization, and challenge sets that probe properties such as hallucination; evaluations that provide fine-grained insight VLM capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and training from base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible training code, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open VLMs.
Read more5/31/2024

0
Vision-Language Models under Cultural and Inclusive Considerations
Antonia Karamolegkou, Phillip Rust, Yong Cao, Ruixiang Cui, Anders S{o}gaard, Daniel Hershcovich
Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Read more7/9/2024
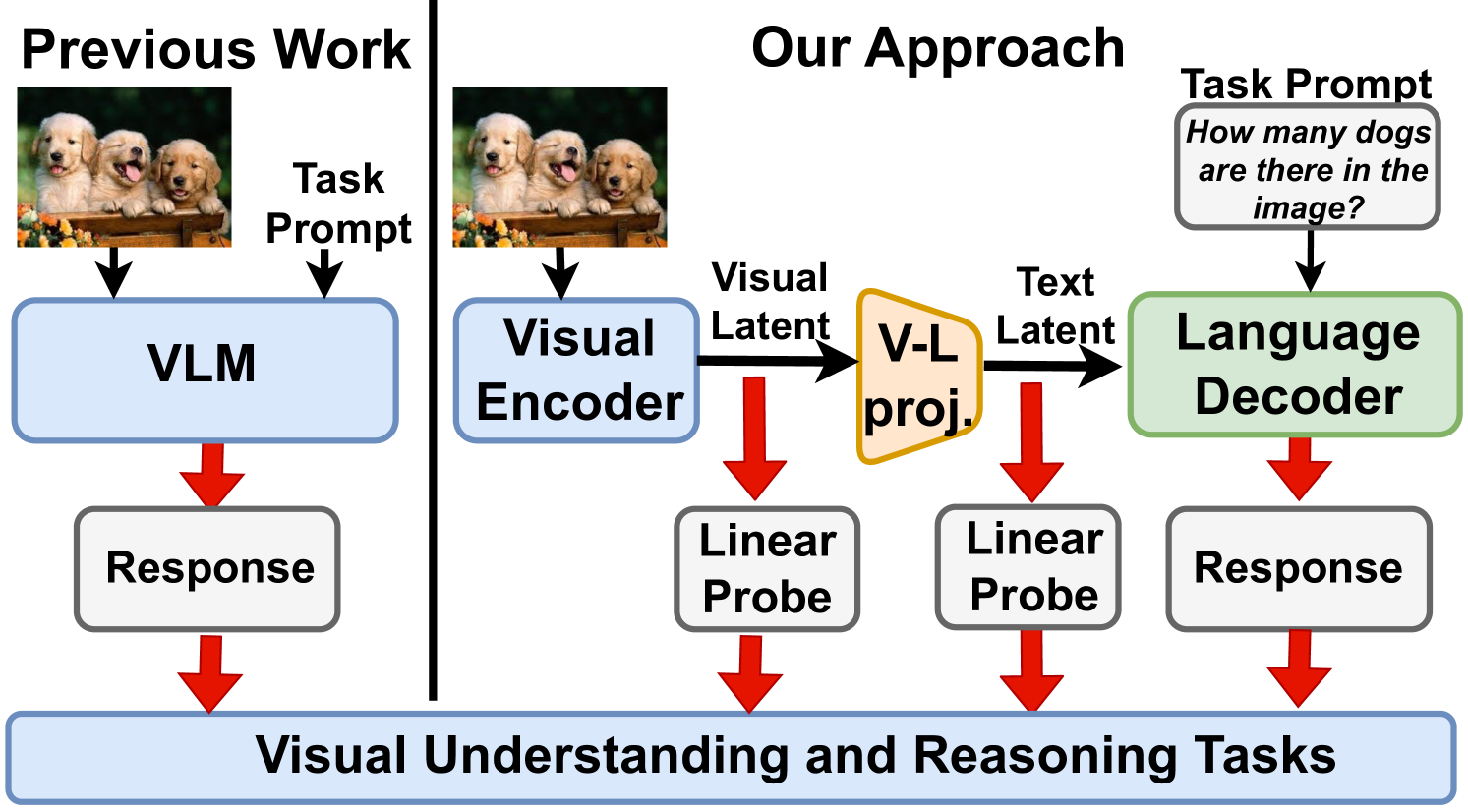
0
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Shivam Chandhok, Wan-Cyuan Fan, Leonid Sigal
Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
Read more8/14/2024