Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities

0
Sign in to get full access
Overview
- The paper examines the capabilities and limitations of basic vision language models (VLMs) in understanding and reasoning about images.
- The authors perform a series of experiments to test VLM performance on various visual tasks, uncovering some surprising observations.
- They find that VLMs often struggle with simple visual concepts and reasoning, despite their strong performance on image-text matching.
Plain English Explanation
Vision language models (VLMs) are AI systems that can understand and generate text based on visual inputs. They have shown impressive capabilities in tasks like describing images and answering questions about images.
However, this paper suggests that VLMs may have significant limitations when it comes to basic visual understanding and reasoning. The authors conduct a series of experiments to probe the capabilities of these models, and their findings are quite surprising.
For example, they find that VLMs often struggle to recognize simple visual concepts, like the difference between a chair and a table. They also have trouble with basic visual reasoning, such as determining if an object is occluded or reflected in a mirror.
Despite their strong performance on tasks like image-text matching, these basic visual shortcomings suggest that VLMs may not truly understand the content of the images they are processing. The authors conclude that these models are still quite "blind" in certain ways, and that more research is needed to address these limitations.
Technical Explanation
The paper begins by noting the impressive capabilities of VLMs in tasks like image-text matching and captioning. However, the authors argue that these models may still have significant limitations when it comes to basic visual understanding and reasoning.
To investigate this, they conduct a series of experiments using a variety of VLM architectures, including CLIP, ALIGN, and DALL-E. They test the models on tasks designed to probe their ability to recognize simple visual concepts, reason about occlusion and reflections, and understand the spatial relationships between objects.
The results of these experiments reveal some surprising shortcomings. For example, the VLMs often struggle to distinguish between conceptually similar objects, like chairs and tables. They also have trouble identifying when an object is occluded or reflected in a mirror.
The authors hypothesize that these limitations may stem from the way VLMs are trained, which often emphasizes high-level image-text matching over more granular visual understanding. They suggest that addressing these shortcomings may require rethinking the training approaches and architectures used for VLMs.
Critical Analysis
The paper provides a valuable and thought-provoking examination of the limitations of current VLM systems. The authors acknowledge that these models have achieved impressive results on many tasks, but they rightly point out that their performance may not always reflect true visual understanding.
One potential limitation of the research is the relatively small scale of the experiments. While the authors test multiple VLM architectures, the specific tasks and datasets used may not be fully representative of the models' broader capabilities. Additionally, the paper does not delve into the potential reasons behind the models' performance issues in depth, leaving some open questions.
Nevertheless, the findings presented in this paper are significant and suggest that the field of VLM research still has significant room for improvement. Addressing the blindspots and limitations uncovered here could lead to the development of more robust and capable vision-language systems.
Conclusion
This paper offers a valuable critique of the current state of vision language models, highlighting their surprising weaknesses in basic visual understanding and reasoning. The experiments conducted by the authors reveal that despite their strong performance on tasks like image-text matching, VLMs may still be quite "blind" to certain fundamental aspects of visual processing.
These findings suggest that the development of truly capable vision-language systems will require a deeper understanding of how these models perceive and reason about visual information. By addressing the limitations uncovered in this research, the field can work towards creating VLMs that better reflect human-like visual understanding and cognition.
The insights presented in this paper underscore the importance of continued research and innovation in the field of vision-language AI. As these models become increasingly prevalent and influential, it is crucial that their capabilities and limitations are thoroughly explored and understood.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Shivam Chandhok, Wan-Cyuan Fan, Leonid Sigal
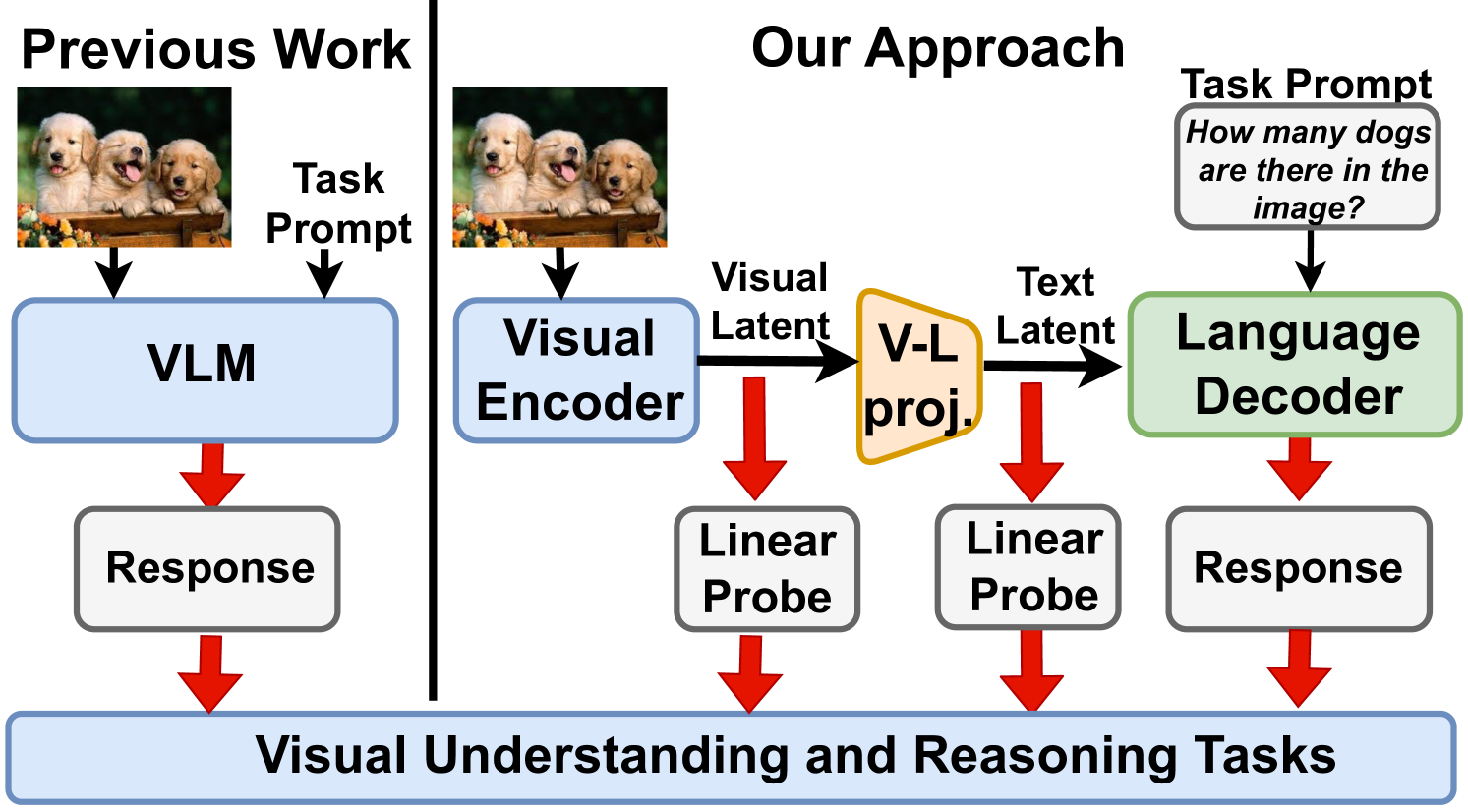
Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
Read more8/14/2024

2
Vision language models are blind
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
While large language models with vision capabilities (VLMs), e.g., GPT-4o and Gemini 1.5 Pro, are powering various image-text applications and scoring high on many vision-understanding benchmarks, we find that they are surprisingly still struggling with low-level vision tasks that are easy to humans. Specifically, on BlindTest, our suite of 7 very simple tasks such as identifying (a) whether two circles overlap; (b) whether two lines intersect; (c) which letter is being circled in a word; and (d) counting circles in an Olympic-like logo, four state-of-the-art VLMs are only 58.57% accurate on average. Claude 3.5 Sonnet performs the best at 74.94% accuracy, but this is still far from the human expected accuracy of 100%. Across different image resolutions and line widths, VLMs consistently struggle with tasks that require precise spatial information and recognizing geometric primitives that overlap or are close together. Code and data are available at: https://vlmsareblind.github.io
Read more7/29/2024

0
Evaluation and Comparison of Visual Language Models for Transportation Engineering Problems
Sanjita Prajapati, Tanu Singh, Chinmay Hegde, Pranamesh Chakraborty
Recent developments in vision language models (VLM) have shown great potential for diverse applications related to image understanding. In this study, we have explored state-of-the-art VLM models for vision-based transportation engineering tasks such as image classification and object detection. The image classification task involves congestion detection and crack identification, whereas, for object detection, helmet violations were identified. We have applied open-source models such as CLIP, BLIP, OWL-ViT, Llava-Next, and closed-source GPT-4o to evaluate the performance of these state-of-the-art VLM models to harness the capabilities of language understanding for vision-based transportation tasks. These tasks were performed by applying zero-shot prompting to the VLM models, as zero-shot prompting involves performing tasks without any training on those tasks. It eliminates the need for annotated datasets or fine-tuning for specific tasks. Though these models gave comparative results with benchmark Convolutional Neural Networks (CNN) models in the image classification tasks, for object localization tasks, it still needs improvement. Therefore, this study provides a comprehensive evaluation of the state-of-the-art VLM models highlighting the advantages and limitations of the models, which can be taken as the baseline for future improvement and wide-scale implementation.
Read more9/5/2024

0
Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Read more4/16/2024