VLPrompt: Vision-Language Prompting for Panoptic Scene Graph Generation

0

Sign in to get full access
Overview
- This paper presents VLPrompt, a novel approach to panoptic scene graph generation that leverages vision-language prompting.
- VLPrompt uses a pre-trained vision-language model to generate scene graphs from images, where objects, their attributes, and relationships are represented as a structured knowledge graph.
- The key innovations of VLPrompt include the use of prompting techniques to guide the model in understanding the visual scene and pseudo-prompting to efficiently generate scene graphs.
Plain English Explanation
VLPrompt is a new way to automatically create detailed descriptions of images, called "scene graphs." Scene graphs represent the objects in an image, their properties, and how they are related to each other. This is a valuable tool for understanding and reasoning about complex visual scenes.
The key idea behind VLPrompt is to use pre-trained vision-language models that have been taught to understand both images and text. By giving the model prompts, or guiding instructions, VLPrompt can direct the model to focus on the important aspects of the visual scene and generate a comprehensive scene graph.
VLPrompt also uses a technique called "pseudo-prompting" to make the scene graph generation process more efficient. This means the model can quickly and accurately produce the scene graph without having to do a lot of extra work.
Overall, VLPrompt is an innovative approach that leverages the power of vision-language models to provide detailed and structured descriptions of images, which could be useful for a wide range of applications, such as image understanding, robotics, and visual question answering.
Technical Explanation
VLPrompt builds on recent advancements in vision-language models that can understand both visual and textual information. The key technical innovations of VLPrompt include:
-
Vision-Language Prompting: VLPrompt uses prompts, or guiding instructions, to direct the vision-language model to focus on the important elements of the visual scene and generate a comprehensive scene graph. This prompting technique allows the model to better understand the relationships between objects, their attributes, and the overall scene.
-
Pseudo-Prompting: To make the scene graph generation process more efficient, VLPrompt employs a pseudo-prompting approach. This involves automatically generating prompts that closely match the target scene graph, allowing the model to quickly and accurately produce the final output.
-
Memory-Efficient Prompting: VLPrompt also introduces a memory-efficient prompting strategy, which reduces the memory footprint of the prompting process and enables the use of VLPrompt with large, high-capacity vision-language models.
The authors evaluate VLPrompt on several benchmark datasets for panoptic scene graph generation and demonstrate that it outperforms state-of-the-art methods, while being more efficient and scalable.
Critical Analysis
The authors of the VLPrompt paper have made a compelling contribution to the field of scene graph generation by leveraging the power of vision-language models and prompting techniques. However, there are a few potential limitations and areas for further research:
-
Generalization: While VLPrompt has shown strong performance on the evaluated benchmark datasets, it would be valuable to assess its generalization capabilities on a wider range of visual scenes and domains. Extending the evaluation to more diverse and challenging datasets could provide additional insights into the model's robustness.
-
Interpretability: As with many complex machine learning models, the inner workings of VLPrompt may not be entirely transparent. Further research into the interpretability of the model's decision-making process could help users better understand how it generates scene graphs and potentially uncover biases or limitations.
-
Real-World Applications: The authors mention potential applications of VLPrompt in areas such as image understanding, robotics, and visual question answering. However, more research is needed to explore the practical deployment of VLPrompt in these real-world settings and address any challenges that may arise.
-
Ethical Considerations: As with any powerful AI system, the deployment of VLPrompt should be accompanied by careful consideration of its ethical implications, such as potential biases, privacy concerns, and the responsible use of the generated scene graphs.
Overall, the VLPrompt paper represents an innovative and promising approach to panoptic scene graph generation. By continuing to build on this work and addressing the aforementioned areas, the research community can further advance the field of vision-language understanding and unlock even more impactful applications.
Conclusion
The VLPrompt paper introduces a novel vision-language prompting approach for generating comprehensive and efficient panoptic scene graphs from images. By leveraging pre-trained vision-language models and innovative prompting techniques, VLPrompt demonstrates state-of-the-art performance on benchmark scene graph generation tasks.
The key innovations of VLPrompt, including vision-language prompting, pseudo-prompting, and memory-efficient prompting, showcase the power of combining advanced machine learning techniques to tackle complex visual understanding problems. As the research community continues to push the boundaries of vision-language models, VLPrompt serves as an exciting example of how these models can be leveraged to provide rich and structured representations of visual scenes, with potential applications in areas such as image understanding, robotics, and visual reasoning.
While the VLPrompt paper presents a compelling contribution, there are opportunities for further research to address the limitations and explore the real-world deployment of this technology. By continuing to advance the state-of-the-art in scene graph generation and vision-language understanding, the research community can unlock new possibilities for AI-powered visual analysis and decision-making, ultimately benefiting a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VLPrompt: Vision-Language Prompting for Panoptic Scene Graph Generation
Zijian Zhou, Miaojing Shi, Holger Caesar
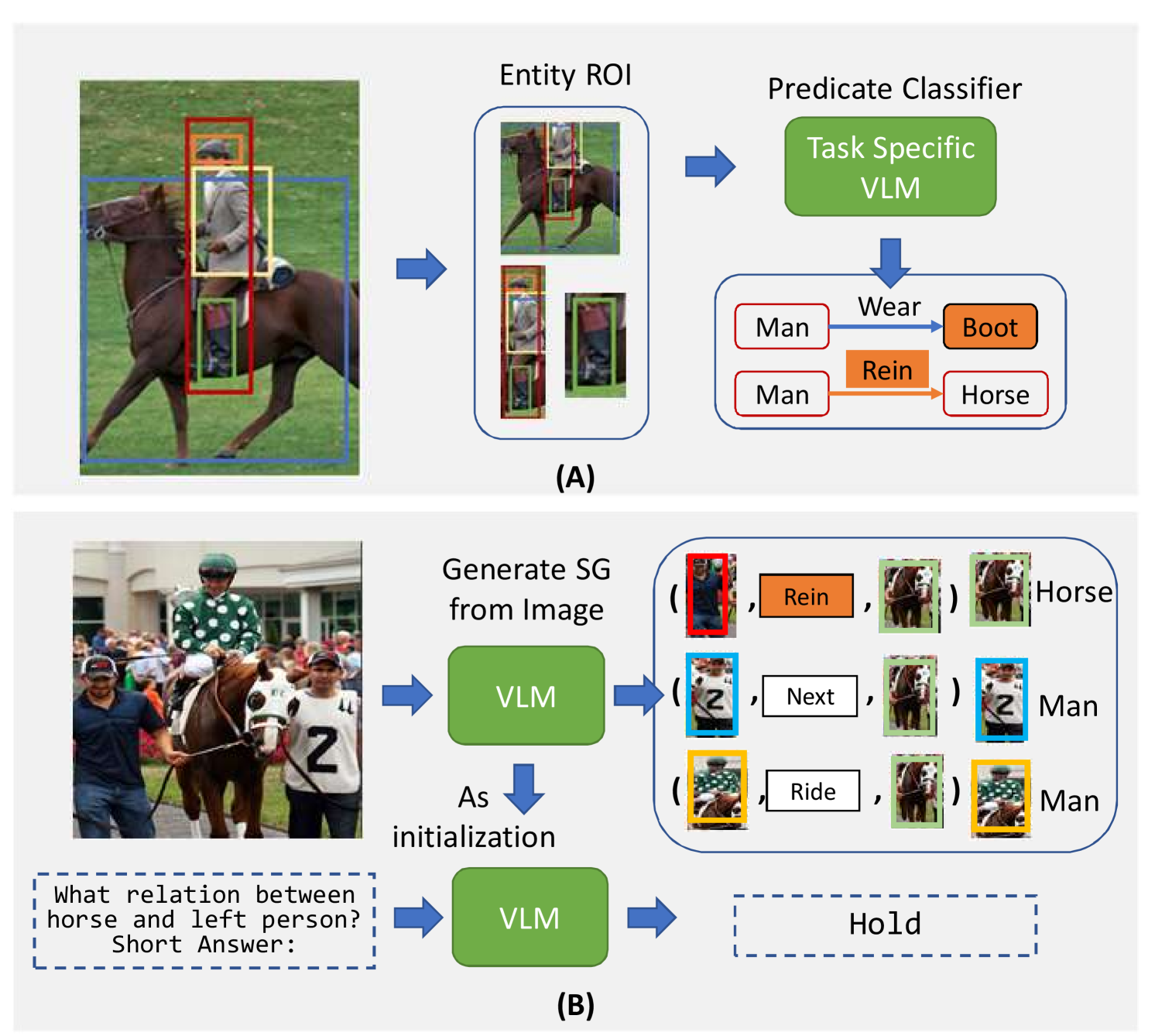
Panoptic Scene Graph Generation (PSG) aims at achieving a comprehensive image understanding by simultaneously segmenting objects and predicting relations among objects. However, the long-tail problem among relations leads to unsatisfactory results in real-world applications. Prior methods predominantly rely on vision information or utilize limited language information, such as object or relation names, thereby overlooking the utility of language information. Leveraging the recent progress in Large Language Models (LLMs), we propose to use language information to assist relation prediction, particularly for rare relations. To this end, we propose the Vision-Language Prompting (VLPrompt) model, which acquires vision information from images and language information from LLMs. Then, through a prompter network based on attention mechanism, it achieves precise relation prediction. Our extensive experiments show that VLPrompt significantly outperforms previous state-of-the-art methods on the PSG dataset, proving the effectiveness of incorporating language information and alleviating the long-tail problem of relations. Code is available at url{https://github.com/franciszzj/TP-SIS}.
Read more6/21/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024
0
Transitive Vision-Language Prompt Learning for Domain Generalization
Liyuan Wang, Yan Jin, Zhen Chen, Jinlin Wu, Mengke Li, Yang Lu, Hanzi Wang
The vision-language pre-training has enabled deep models to make a huge step forward in generalizing across unseen domains. The recent learning method based on the vision-language pre-training model is a great tool for domain generalization and can solve this problem to a large extent. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. In this paper, we introduce a novel prompt learning strategy that leverages deep vision prompts to address domain invariance while utilizing language prompts to ensure class separability, coupled with adaptive weighting mechanisms to balance domain invariance and class separability. Extensive experiments demonstrate that deep vision prompts effectively extract domain-invariant features, significantly improving the generalization ability of deep models and achieving state-of-the-art performance on three datasets.
Read more4/30/2024
🖼️
0
Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
Yaoqin Ye, Junjie Zhang, Hongwei Shi
The task of medical image recognition is notably complicated by the presence of varied and multiple pathological indications, presenting a unique challenge in multi-label classification with unseen labels. This complexity underlines the need for computer-aided diagnosis methods employing multi-label zero-shot learning. Recent advancements in pre-trained vision-language models (VLMs) have showcased notable zero-shot classification abilities on medical images. However, these methods have limitations on leveraging extensive pre-trained knowledge from broader image datasets, and often depend on manual prompt construction by expert radiologists. By automating the process of prompt tuning, prompt learning techniques have emerged as an efficient way to adapt VLMs to downstream tasks. Yet, existing CoOp-based strategies fall short in performing class-specific prompts on unseen categories, limiting generalizability in fine-grained scenarios. To overcome these constraints, we introduce a novel prompt generation approach inspirited by text generation in natural language processing (NLP). Our method, named Pseudo-Prompt Generating (PsPG), capitalizes on the priori knowledge of multi-modal features. Featuring a RNN-based decoder, PsPG autoregressively generates class-tailored embedding vectors, i.e., pseudo-prompts. Comparative evaluations on various multi-label chest radiograph datasets affirm the superiority of our approach against leading medical vision-language and multi-label prompt learning methods. The source code is available at https://github.com/fallingnight/PsPG
Read more9/16/2024