VMAS: Video-to-Music Generation via Semantic Alignment in Web Music Videos

0

Sign in to get full access
Overview
- The paper proposes a video-to-music generation system called VMAs (Video-to-Music Generation via Semantic Alignment) that aligns video and music semantically.
- It leverages web music videos to learn the relationships between visual and audio features, enabling the generation of music that matches the content of input videos.
- The system utilizes a self-supervised learning approach to learn the video-music correspondence without the need for paired training data.
Plain English Explanation
The researchers developed a system called VMAs that can automatically generate music to match the content of a given video. Rather than requiring a large dataset of pre-paired video and music clips, VMAs learns the connections between visual and audio features by analyzing a collection of web-based music videos.
[The core idea is to leverage the wealth of online music videos to learn how visual elements like people, objects, and actions relate to musical elements like melody, harmony, and rhythm. This allows the system to generate new music that aligns with the semantics of an input video, even if no direct pairing of that video and music existed before.]
Once trained, the VMAs system can take a new video as input and produce an original music track that feels cohesive and complementary to the visuals. This could be useful for applications like video game soundtracks, social media content, or artistic projects where the music needs to closely match the video.
Technical Explanation
The [VMAs] system consists of several key components. First, it uses pre-trained computer vision and audio models to extract visual and audio features from a collection of web-based music videos. This allows it to learn the relationships between things like objects, actions, and emotions visible in the videos, and the corresponding musical elements like melody, rhythm, and instrumentation.
[The researchers then employ a self-supervised training approach to map the visual and audio features into a shared semantic space. This enables the system to predict the music that is most likely to match the content of a new input video, even if that exact video-music pairing has never been seen before.]
Experiments show that VMAs is able to generate music that is rated as more coherent and aligned with the video content, compared to baseline approaches that don't leverage the web-scale video-music data. The system also demonstrates the ability to adapt the generated music to match different moods or emotional tones conveyed in the input video.
Critical Analysis
One limitation of the VMAs approach is that it relies on the quality and diversity of the web-based music video dataset used for training. If the dataset is biased or lacks certain genres/styles, the system's ability to generate suitable music for all types of video content may be constrained.
[Additionally, while the self-supervised training process is an innovative way to learn video-music correspondences without requiring explicitly paired data, there may be some nuanced relationships that are difficult for the model to capture fully in this unsupervised manner.]
Further research could explore ways to incorporate more explicit supervision, either through human annotations or reinforcement from user feedback, to refine the video-to-music generation capabilities. Addressing these potential issues could help make VMAs a more robust and versatile system for real-world applications.
Conclusion
The [VMAs] paper presents an interesting approach to automatically generating music that aligns with the semantic content of input videos. By leveraging the wealth of web-based music videos, the system is able to learn the connections between visual and audio elements without needing a large dataset of pre-paired examples.
[This work demonstrates the potential for AI-powered music generation systems to enhance various multimedia applications, from video games to social media content. As these technologies continue to evolve, they may open up new creative possibilities for seamlessly integrating music and visuals in engaging and meaningful ways.]
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VMAS: Video-to-Music Generation via Semantic Alignment in Web Music Videos
Yan-Bo Lin, Yu Tian, Linjie Yang, Gedas Bertasius, Heng Wang
We present a framework for learning to generate background music from video inputs. Unlike existing works that rely on symbolic musical annotations, which are limited in quantity and diversity, our method leverages large-scale web videos accompanied by background music. This enables our model to learn to generate realistic and diverse music. To accomplish this goal, we develop a generative video-music Transformer with a novel semantic video-music alignment scheme. Our model uses a joint autoregressive and contrastive learning objective, which encourages the generation of music aligned with high-level video content. We also introduce a novel video-beat alignment scheme to match the generated music beats with the low-level motions in the video. Lastly, to capture fine-grained visual cues in a video needed for realistic background music generation, we introduce a new temporal video encoder architecture, allowing us to efficiently process videos consisting of many densely sampled frames. We train our framework on our newly curated DISCO-MV dataset, consisting of 2.2M video-music samples, which is orders of magnitude larger than any prior datasets used for video music generation. Our method outperforms existing approaches on the DISCO-MV and MusicCaps datasets according to various music generation evaluation metrics, including human evaluation. Results are available at https://genjib.github.io/project_page/VMAs/index.html
Read more9/12/2024
0
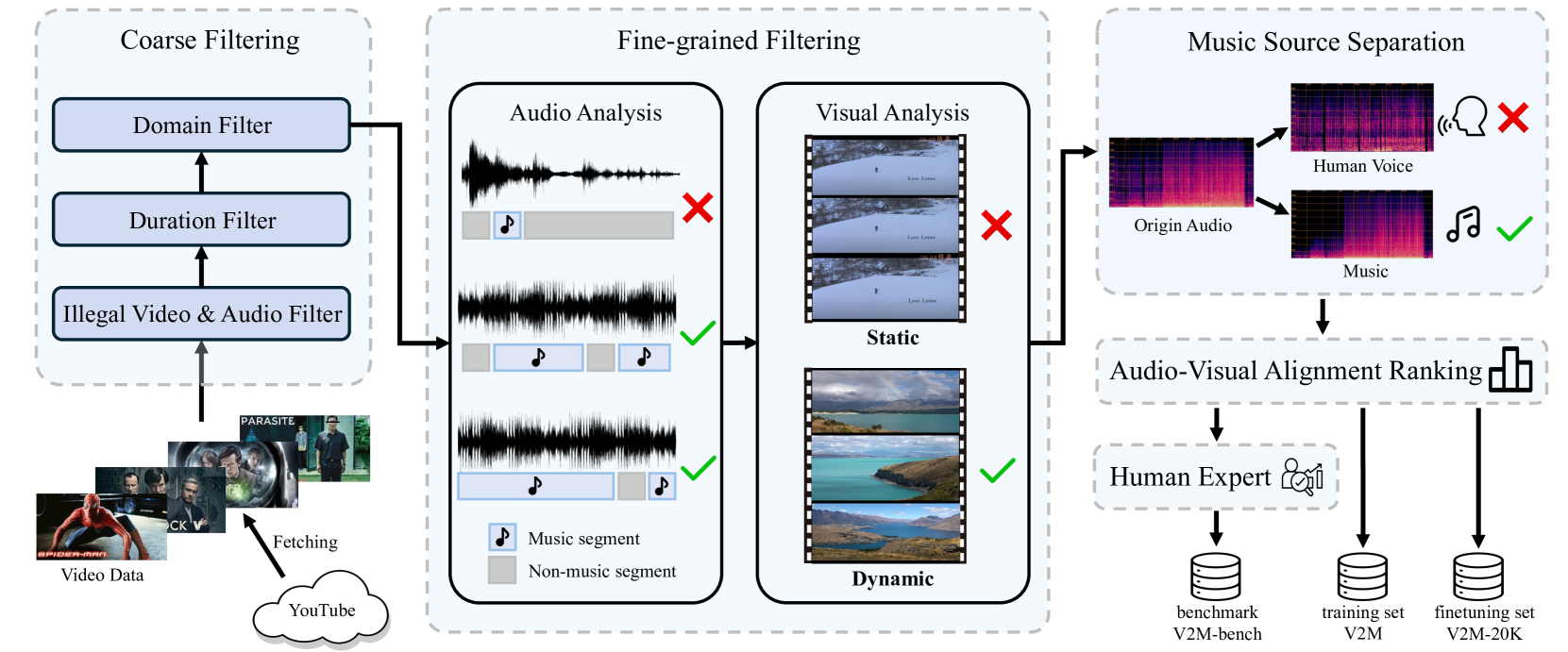
VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
Zeyue Tian, Zhaoyang Liu, Ruibin Yuan, Jiahao Pan, Xiaoqiang Huang, Qifeng Liu, Xu Tan, Qifeng Chen, Wei Xue, Yike Guo
In this work, we systematically study music generation conditioned solely on the video. First, we present a large-scale dataset comprising 190K video-music pairs, including various genres such as movie trailers, advertisements, and documentaries. Furthermore, we propose VidMuse, a simple framework for generating music aligned with video inputs. VidMuse stands out by producing high-fidelity music that is both acoustically and semantically aligned with the video. By incorporating local and global visual cues, VidMuse enables the creation of musically coherent audio tracks that consistently match the video content through Long-Short-Term modeling. Through extensive experiments, VidMuse outperforms existing models in terms of audio quality, diversity, and audio-visual alignment. The code and datasets will be available at https://github.com/ZeyueT/VidMuse/.
Read more6/7/2024
0
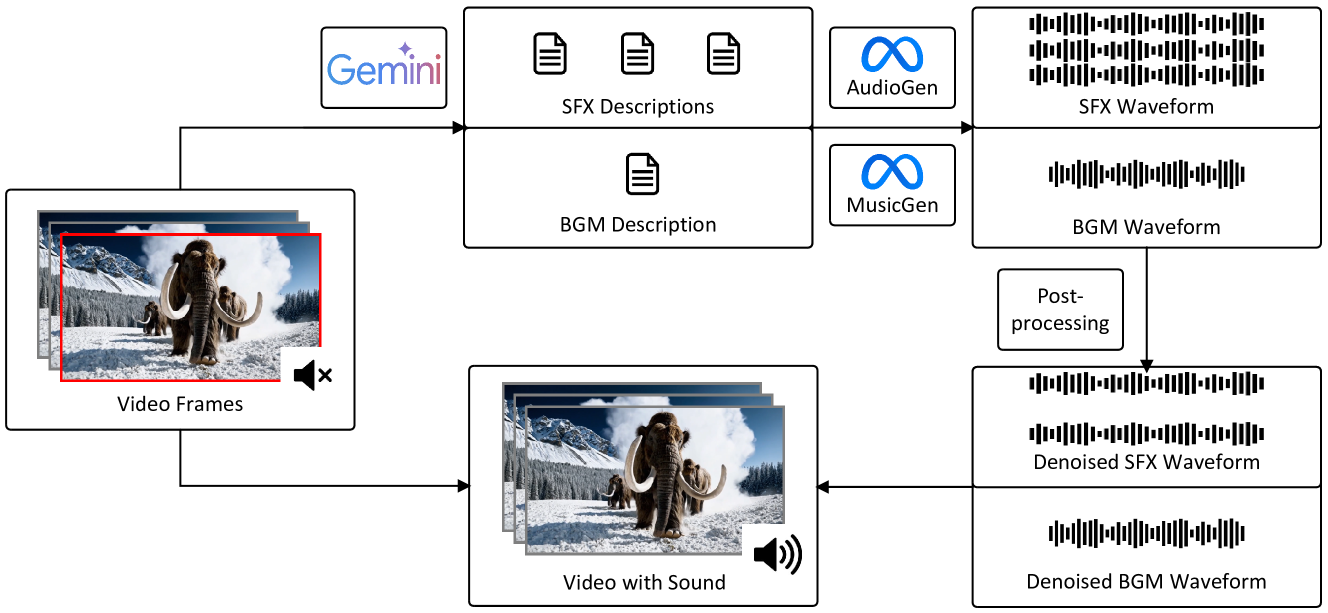
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Read more4/29/2024
0
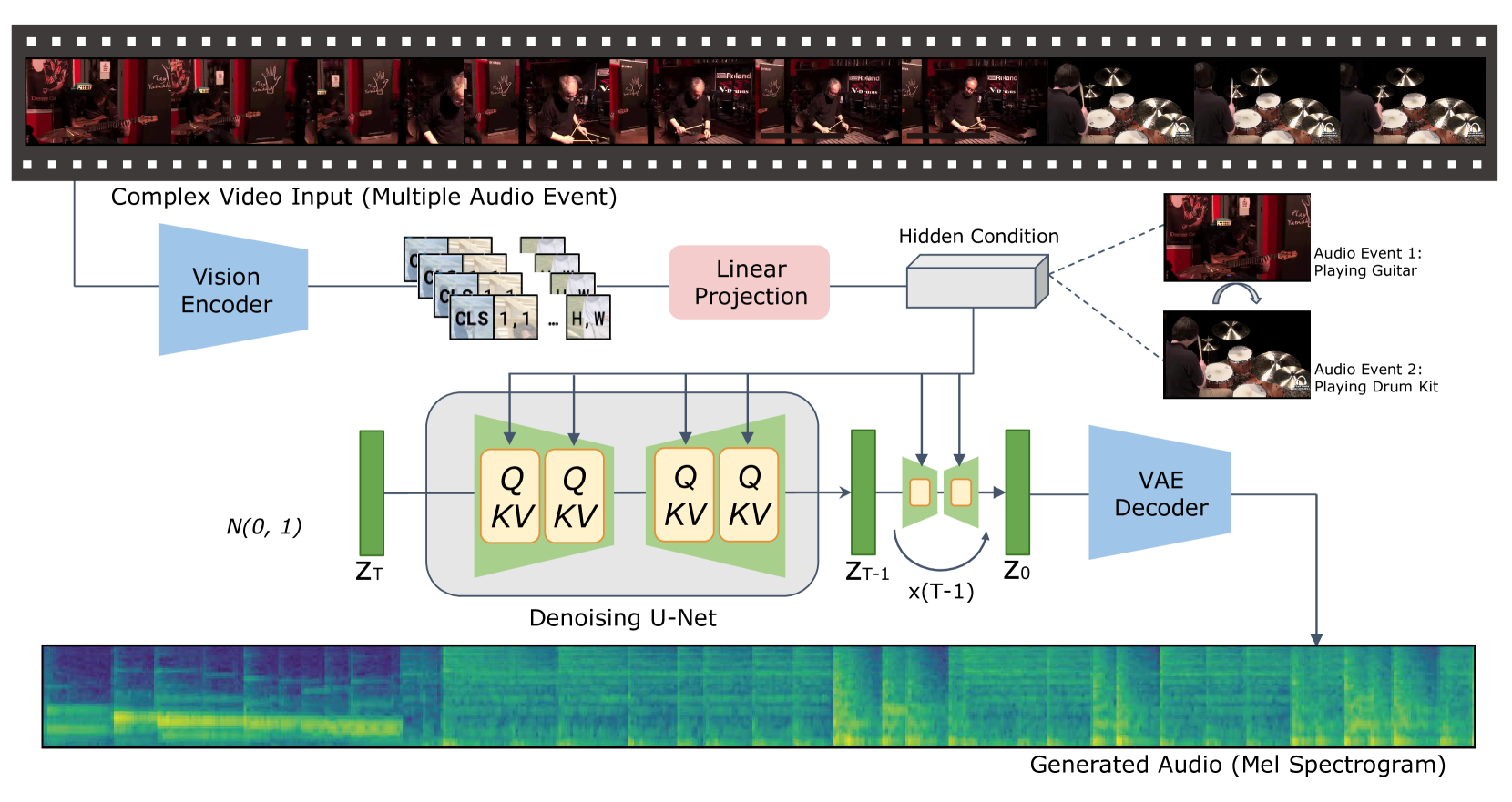
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024