VOICE: Variance of Induced Contrastive Explanations to quantify Uncertainty in Neural Network Interpretability

0
Sign in to get full access
Overview
- This paper introduces VOICE, a method to quantify the uncertainty in neural network interpretability by analyzing the variance of induced contrastive explanations.
- Contrastive explanations highlight the differences between a model's prediction for the input and a counterfactual input, providing insight into the model's decision-making process.
- The authors propose that the variance in these contrastive explanations can serve as a proxy for the model's uncertainty in its predictions.
Plain English Explanation
Neural networks, a type of machine learning model, are powerful tools for making predictions. However, it's often difficult to understand how these models arrive at their decisions. Contrastive explanations can help by highlighting the key differences between the model's prediction for the input and a "counterfactual" input - an altered version of the original input that would result in a different prediction.
The authors of this paper introduce a method called VOICE (Variance of Induced Contrastive Explanations) that uses the variability, or "variance," in these contrastive explanations to quantify the uncertainty in the neural network's interpretability. The idea is that if the contrastive explanations for a particular input vary a lot, it suggests the model is less certain about its prediction for that input.
By understanding the model's uncertainty, researchers and developers can better interpret the model's behavior and make more informed decisions about its use.
Technical Explanation
The authors propose the VOICE method to quantify the uncertainty in neural network interpretability. VOICE leverages contrastive explanations, which highlight the key differences between the model's prediction for an input and a counterfactual input that would result in a different prediction.
The authors hypothesize that the variance in these contrastive explanations can serve as a proxy for the model's uncertainty in its predictions. To test this, they conduct experiments on several image classification tasks using pre-trained neural network models.
The VOICE method works as follows:
- For a given input, the model generates a contrastive explanation highlighting the differences between the predicted class and a counterfactual class.
- This process is repeated multiple times, with small perturbations to the input, to generate a set of contrastive explanations.
- The variance in these contrastive explanations is calculated and used as a measure of the model's uncertainty in its prediction for that input.
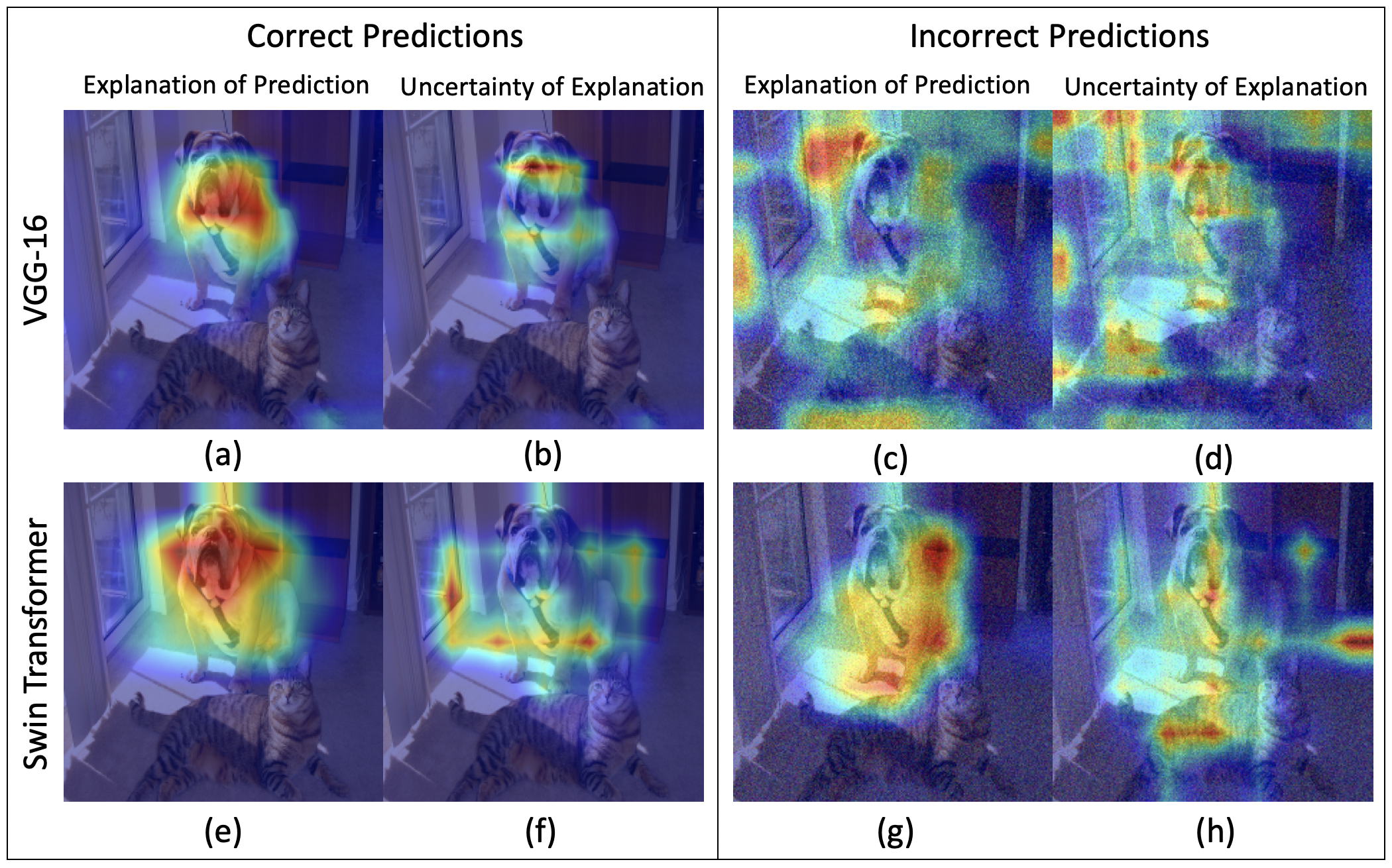
The experiments demonstrate that the VOICE metric correlates with other measures of model uncertainty, such as predictive entropy and Monte Carlo dropout. This suggests that the variance in contrastive explanations can indeed be a useful proxy for quantifying the uncertainty in neural network interpretability.
Critical Analysis
The VOICE method provides a novel approach to quantifying the uncertainty in neural network interpretability, which is an important consideration for the real-world deployment of these models.
One potential limitation of the VOICE method is that it relies on the availability of contrastive explanations, which may not always be easy to generate or interpret. The authors acknowledge that the quality and interpretability of the contrastive explanations can impact the VOICE metric, and further research may be needed to improve the explanation generation process.
Additionally, the experiments in the paper focus on image classification tasks, and it's unclear how well the VOICE method would generalize to other types of machine learning problems, such as natural language processing or reinforcement learning. Further research is needed to explore the broader applicability of the VOICE approach.
Despite these potential limitations, the VOICE method represents a valuable contribution to the field of uncertainty quantification in machine learning. By providing a way to assess the reliability of neural network interpretations, the VOICE approach can help developers and researchers make more informed decisions about the deployment and use of these powerful models.
Conclusion
The VOICE method introduced in this paper offers a novel way to quantify the uncertainty in neural network interpretability by analyzing the variance in contrastive explanations. This approach can provide valuable insights into the reliability of a model's predictions and decision-making process, which is crucial for the responsible deployment of machine learning systems in real-world applications.
While the method has some potential limitations, the authors' work represents an important step forward in uncertainty quantification for neural networks and opens up new avenues for further research in this critical area of machine learning and AI safety.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VOICE: Variance of Induced Contrastive Explanations to quantify Uncertainty in Neural Network Interpretability
Mohit Prabhushankar, Ghassan AlRegib
In this paper, we visualize and quantify the predictive uncertainty of gradient-based post hoc visual explanations for neural networks. Predictive uncertainty refers to the variability in the network predictions under perturbations to the input. Visual post hoc explainability techniques highlight features within an image to justify a network's prediction. We theoretically show that existing evaluation strategies of visual explanatory techniques partially reduce the predictive uncertainty of neural networks. This analysis allows us to construct a plug in approach to visualize and quantify the remaining predictive uncertainty of any gradient-based explanatory technique. We show that every image, network, prediction, and explanatory technique has a unique uncertainty. The proposed uncertainty visualization and quantification yields two key observations. Firstly, oftentimes under incorrect predictions, explanatory techniques are uncertain about the same features that they are attributing the predictions to, thereby reducing the trustworthiness of the explanation. Secondly, objective metrics of an explanation's uncertainty, empirically behave similarly to epistemic uncertainty. We support these observations on two datasets, four explanatory techniques, and six neural network architectures. The code is available at https://github.com/olivesgatech/VOICE-Uncertainty.
Read more6/4/2024
🔮
0
Visual Analysis of Prediction Uncertainty in Neural Networks for Deep Image Synthesis
Soumya Dutta, Faheem Nizar, Ahmad Amaan, Ayan Acharya
Ubiquitous applications of Deep neural networks (DNNs) in different artificial intelligence systems have led to their adoption in solving challenging visualization problems in recent years. While sophisticated DNNs offer an impressive generalization, it is imperative to comprehend the quality, confidence, robustness, and uncertainty associated with their prediction. A thorough understanding of these quantities produces actionable insights that help application scientists make informed decisions. Unfortunately, the intrinsic design principles of the DNNs cannot beget prediction uncertainty, necessitating separate formulations for robust uncertainty-aware models for diverse visualization applications. To that end, this contribution demonstrates how the prediction uncertainty and sensitivity of DNNs can be estimated efficiently using various methods and then interactively compared and contrasted for deep image synthesis tasks. Our inspection suggests that uncertainty-aware deep visualization models generate illustrations of informative and superior quality and diversity. Furthermore, prediction uncertainty improves the robustness and interpretability of deep visualization models, making them practical and convenient for various scientific domains that thrive on visual analyses.
Read more6/28/2024
0
Identifying Drivers of Predictive Aleatoric Uncertainty
Pascal Iversen, Simon Witzke, Katharina Baum, Bernhard Y. Renard
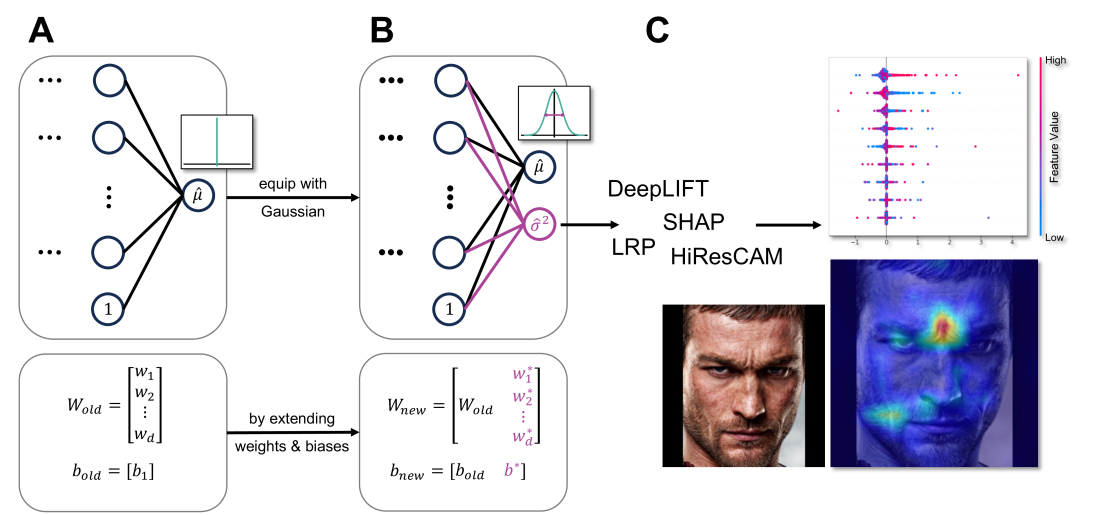
Explainability and uncertainty quantification are two pillars of trustable artificial intelligence. However, the reasoning behind uncertainty estimates is generally left unexplained. Identifying the drivers of uncertainty complements explanations of point predictions in recognizing model limitations and enhances trust in decisions and their communication. So far, explanations of uncertainties have been rarely studied. The few exceptions rely on Bayesian neural networks or technically intricate approaches, such as auxiliary generative models, thereby hindering their broad adoption. We present a simple approach to explain predictive aleatoric uncertainties. We estimate uncertainty as predictive variance by adapting a neural network with a Gaussian output distribution. Subsequently, we apply out-of-the-box explainers to the model's variance output. This approach can explain uncertainty influences more reliably than literature baselines, which we evaluate in a synthetic setting with a known data-generating process. We further adapt multiple metrics from conventional XAI research to uncertainty explanations. We quantify our findings with a nuanced benchmark analysis that includes real-world datasets. Finally, we apply our approach to an age regression model and discover reasonable sources of uncertainty. Overall, we explain uncertainty estimates with little modifications to the model architecture and demonstrate that our approach competes effectively with more intricate methods.
Read more5/31/2024
🧠
0
Epistemic Uncertainty Quantification For Pre-trained Neural Network
Hanjing Wang, Qiang Ji
Epistemic uncertainty quantification (UQ) identifies where models lack knowledge. Traditional UQ methods, often based on Bayesian neural networks, are not suitable for pre-trained non-Bayesian models. Our study addresses quantifying epistemic uncertainty for any pre-trained model, which does not need the original training data or model modifications and can ensure broad applicability regardless of network architectures or training techniques. Specifically, we propose a gradient-based approach to assess epistemic uncertainty, analyzing the gradients of outputs relative to model parameters, and thereby indicating necessary model adjustments to accurately represent the inputs. We first explore theoretical guarantees of gradient-based methods for epistemic UQ, questioning the view that this uncertainty is only calculable through differences between multiple models. We further improve gradient-driven UQ by using class-specific weights for integrating gradients and emphasizing distinct contributions from neural network layers. Additionally, we enhance UQ accuracy by combining gradient and perturbation methods to refine the gradients. We evaluate our approach on out-of-distribution detection, uncertainty calibration, and active learning, demonstrating its superiority over current state-of-the-art UQ methods for pre-trained models.
Read more4/17/2024