QUCE: The Minimisation and Quantification of Path-Based Uncertainty for Generative Counterfactual Explanations
2402.17516
0
0

Abstract
Deep Neural Networks (DNNs) stand out as one of the most prominent approaches within the Machine Learning (ML) domain. The efficacy of DNNs has surged alongside recent increases in computational capacity, allowing these approaches to scale to significant complexities for addressing predictive challenges in big data. However, as the complexity of DNN models rises, interpretability diminishes. In response to this challenge, explainable models such as Adversarial Gradient Integration (AGI) leverage path-based gradients provided by DNNs to elucidate their decisions. Yet the performance of path-based explainers can be compromised when gradients exhibit irregularities during out-of-distribution path traversal. In this context, we introduce Quantified Uncertainty Counterfactual Explanations (QUCE), a method designed to mitigate out-of-distribution traversal by minimizing path uncertainty. QUCE not only quantifies uncertainty when presenting explanations but also generates more certain counterfactual examples. We showcase the performance of the QUCE method by comparing it with competing methods for both path-based explanations and generative counterfactual examples.
Create account to get full access
Overview
- This paper proposes a method called QUCE (Quantification of Uncertainty for Counterfactual Explanations) that aims to minimize and quantify the uncertainty in path-based counterfactual explanations for machine learning models.
- Counterfactual explanations are a type of explainable AI that show how an input could be modified to change the model's prediction, providing insights into the model's decision-making process.
- The researchers identify key axioms for path-based explainers and develop QUCE to address the uncertainty inherent in these types of explanations.
- QUCE uses optimization techniques to find counterfactual examples that minimize uncertainty, and it provides a quantitative measure of the remaining uncertainty.
Plain English Explanation
The paper discusses a new method called QUCE that helps address a key challenge with a type of explainable AI called counterfactual explanations. Counterfactual explanations show how an input could be changed to get a different prediction from a machine learning model, providing insights into how the model made its decision.
However, there is often significant uncertainty in these counterfactual explanations - it may not be clear exactly how to modify the input to achieve the desired outcome. QUCE aims to minimize this uncertainty by using optimization techniques to find the "best" counterfactual example that changes the model's prediction while introducing the least amount of uncertainty.
QUCE also provides a way to quantify the remaining uncertainty in the counterfactual explanation, giving users a sense of how reliable the explanation is. This can help users better interpret the insights provided by the counterfactual explanation and understand the limitations of the model's decision-making process.
Overall, QUCE represents an important advance in explainable AI by making counterfactual explanations more robust and informative for users.
Technical Explanation
The key technical contributions of this paper are:
- Identifying a set of axioms that path-based explainers (like counterfactual explanations) should satisfy, such as minimizing the distance between the original and counterfactual examples.
- Developing the QUCE method, which uses optimization techniques to find counterfactual examples that minimize a novel uncertainty measure. This uncertainty measure captures both the distance between the original and counterfactual examples, as well as the confidence in the model's prediction for the counterfactual example.
- Demonstrating through experiments on various datasets that QUCE can effectively reduce uncertainty in counterfactual explanations compared to other state-of-the-art approaches, while still maintaining high-quality explanations.
The researchers evaluate QUCE on several benchmark datasets and machine learning models, showing that it can indeed provide more certain and informative counterfactual explanations than previous methods. This represents an important step forward in making explainable AI systems more reliable and trustworthy.
Critical Analysis
The paper makes a strong case for the importance of quantifying uncertainty in counterfactual explanations, and the QUCE method represents a promising approach to addressing this challenge. However, there are a few potential limitations and areas for further research:
- The uncertainty measure used in QUCE relies on the model's confidence in its predictions, which may not always be a reliable indicator of true uncertainty. Uncertainty quantification in deep learning models is an active area of research, and more robust techniques could potentially be integrated into QUCE.
- The paper focuses on path-based counterfactual explanations, but other types of explanations (e.g., example-based) may also benefit from uncertainty quantification. Extending QUCE or developing similar techniques for a wider range of explainable AI methods could increase its impact.
- The evaluation in the paper is limited to relatively simple datasets and models. Assessing the performance of QUCE on more complex, real-world applications would help validate its practical utility and identify any additional challenges that may arise.
Overall, the QUCE method represents an important contribution to the field of explainable AI, and the researchers' focus on quantifying uncertainty is a crucial step towards more reliable and trustworthy AI systems.
Conclusion
This paper introduces QUCE, a novel method for minimizing and quantifying the uncertainty in path-based counterfactual explanations for machine learning models. By identifying key axioms for path-based explainers and developing an optimization-based approach to find counterfactual examples with low uncertainty, QUCE helps address a significant limitation of existing explainable AI techniques.
The ability to provide counterfactual explanations with quantified uncertainty can greatly improve the interpretability and trustworthiness of AI systems, empowering users to better understand the model's decision-making process and its limitations. As AI becomes more pervasive in critical domains, advancements like QUCE will be essential to ensuring these systems are transparent, reliable, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
A Comprehensive Survey on Uncertainty Quantification for Deep Learning
Wenchong He, Zhe Jiang
0
0
Deep neural networks (DNNs) have achieved tremendous success in making accurate predictions for computer vision, natural language processing, as well as science and engineering domains. However, it is also well-recognized that DNNs sometimes make unexpected, incorrect, but overconfident predictions. This can cause serious consequences in high-stake applications, such as autonomous driving, medical diagnosis, and disaster response. Uncertainty quantification (UQ) aims to estimate the confidence of DNN predictions beyond prediction accuracy. In recent years, many UQ methods have been developed for DNNs. It is of great practical value to systematically categorize these UQ methods and compare their advantages and disadvantages. However, existing surveys mostly focus on categorizing UQ methodologies from a neural network architecture perspective or a Bayesian perspective and ignore the source of uncertainty that each methodology can incorporate, making it difficult to select an appropriate UQ method in practice. To fill the gap, this paper presents a systematic taxonomy of UQ methods for DNNs based on the types of uncertainty sources (data uncertainty versus model uncertainty). We summarize the advantages and disadvantages of methods in each category. We show how our taxonomy of UQ methodologies can potentially help guide the choice of UQ method in different machine learning problems (e.g., active learning, robustness, and reinforcement learning). We also identify current research gaps and propose several future research directions.
4/11/2024
🧠
Epistemic Uncertainty Quantification For Pre-trained Neural Network
Hanjing Wang, Qiang Ji
0
0
Epistemic uncertainty quantification (UQ) identifies where models lack knowledge. Traditional UQ methods, often based on Bayesian neural networks, are not suitable for pre-trained non-Bayesian models. Our study addresses quantifying epistemic uncertainty for any pre-trained model, which does not need the original training data or model modifications and can ensure broad applicability regardless of network architectures or training techniques. Specifically, we propose a gradient-based approach to assess epistemic uncertainty, analyzing the gradients of outputs relative to model parameters, and thereby indicating necessary model adjustments to accurately represent the inputs. We first explore theoretical guarantees of gradient-based methods for epistemic UQ, questioning the view that this uncertainty is only calculable through differences between multiple models. We further improve gradient-driven UQ by using class-specific weights for integrating gradients and emphasizing distinct contributions from neural network layers. Additionally, we enhance UQ accuracy by combining gradient and perturbation methods to refine the gradients. We evaluate our approach on out-of-distribution detection, uncertainty calibration, and active learning, demonstrating its superiority over current state-of-the-art UQ methods for pre-trained models.
4/17/2024
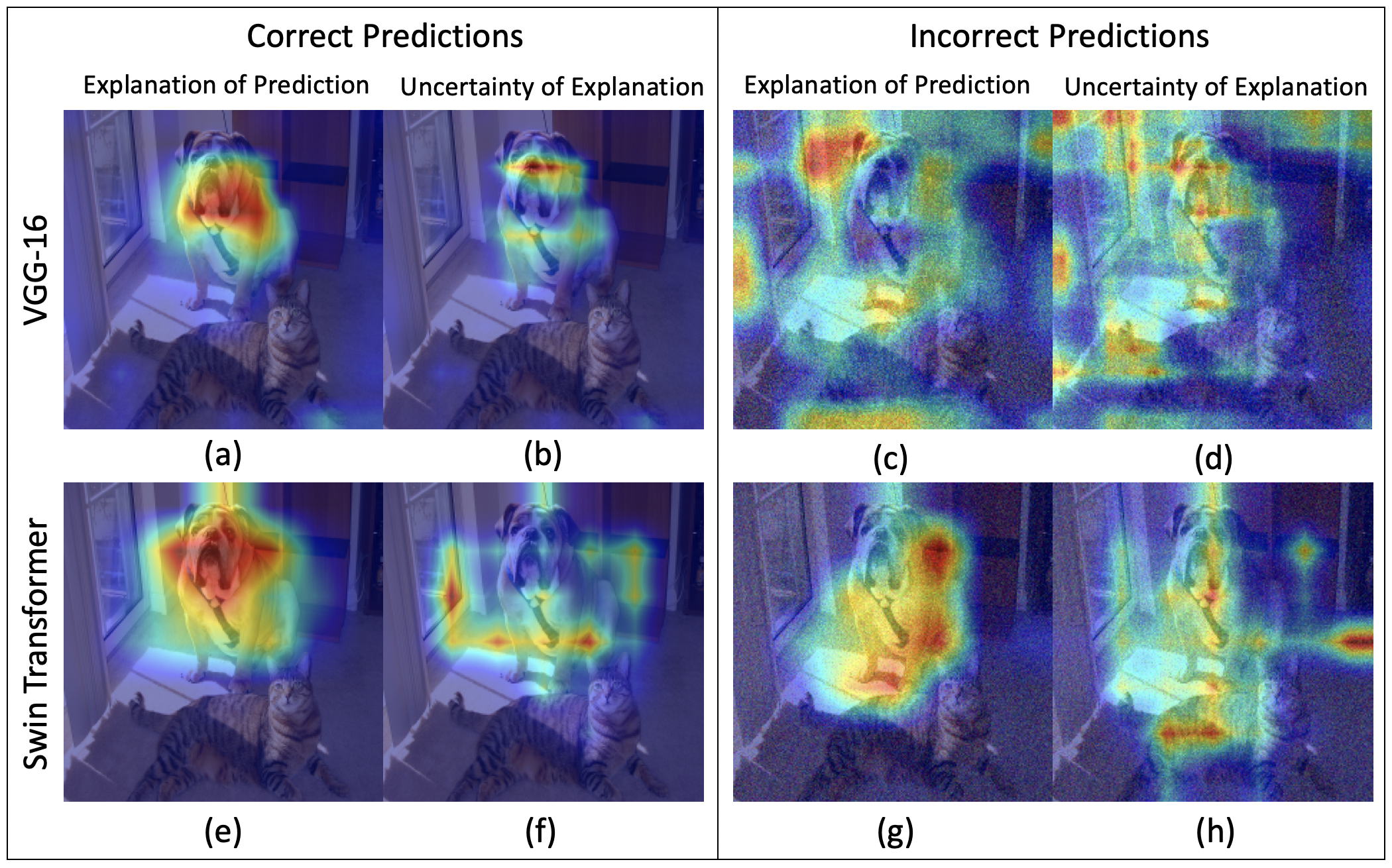
VOICE: Variance of Induced Contrastive Explanations to quantify Uncertainty in Neural Network Interpretability
Mohit Prabhushankar, Ghassan AlRegib
0
0
In this paper, we visualize and quantify the predictive uncertainty of gradient-based post hoc visual explanations for neural networks. Predictive uncertainty refers to the variability in the network predictions under perturbations to the input. Visual post hoc explainability techniques highlight features within an image to justify a network's prediction. We theoretically show that existing evaluation strategies of visual explanatory techniques partially reduce the predictive uncertainty of neural networks. This analysis allows us to construct a plug in approach to visualize and quantify the remaining predictive uncertainty of any gradient-based explanatory technique. We show that every image, network, prediction, and explanatory technique has a unique uncertainty. The proposed uncertainty visualization and quantification yields two key observations. Firstly, oftentimes under incorrect predictions, explanatory techniques are uncertain about the same features that they are attributing the predictions to, thereby reducing the trustworthiness of the explanation. Secondly, objective metrics of an explanation's uncertainty, empirically behave similarly to epistemic uncertainty. We support these observations on two datasets, four explanatory techniques, and six neural network architectures. The code is available at https://github.com/olivesgatech/VOICE-Uncertainty.
6/4/2024
🤔
Navigating Explanatory Multiverse Through Counterfactual Path Geometry
Kacper Sokol, Edward Small, Yueqing Xuan
0
0
Counterfactual explanations are the de facto standard when tasked with interpreting decisions of (opaque) predictive models. Their generation is often subject to algorithmic and domain-specific constraints -- such as density-based feasibility, and attribute (im)mutability or directionality of change -- that aim to maximise their real-life utility. In addition to desiderata with respect to the counterfactual instance itself, existence of a viable path connecting it with the factual data point, known as algorithmic recourse, has become an important technical consideration. While both of these requirements ensure that the steps of the journey as well as its destination are admissible, current literature neglects the multiplicity of such counterfactual paths. To address this shortcoming we introduce the novel concept of explanatory multiverse that encompasses all the possible counterfactual journeys. We then show how to navigate, reason about and compare the geometry of these trajectories with two methods: vector spaces and graphs. To this end, we overview their spacial properties -- such as affinity, branching, divergence and possible future convergence -- and propose an all-in-one metric, called opportunity potential, to quantify them. Implementing this (possibly interactive) explanatory process grants explainees agency by allowing them to select counterfactuals based on the properties of the journey leading to them in addition to their absolute differences. We show the flexibility, benefit and efficacy of such an approach through examples and quantitative evaluation on the German Credit and MNIST data sets.
5/7/2024