VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
2406.07595
0
0
Abstract
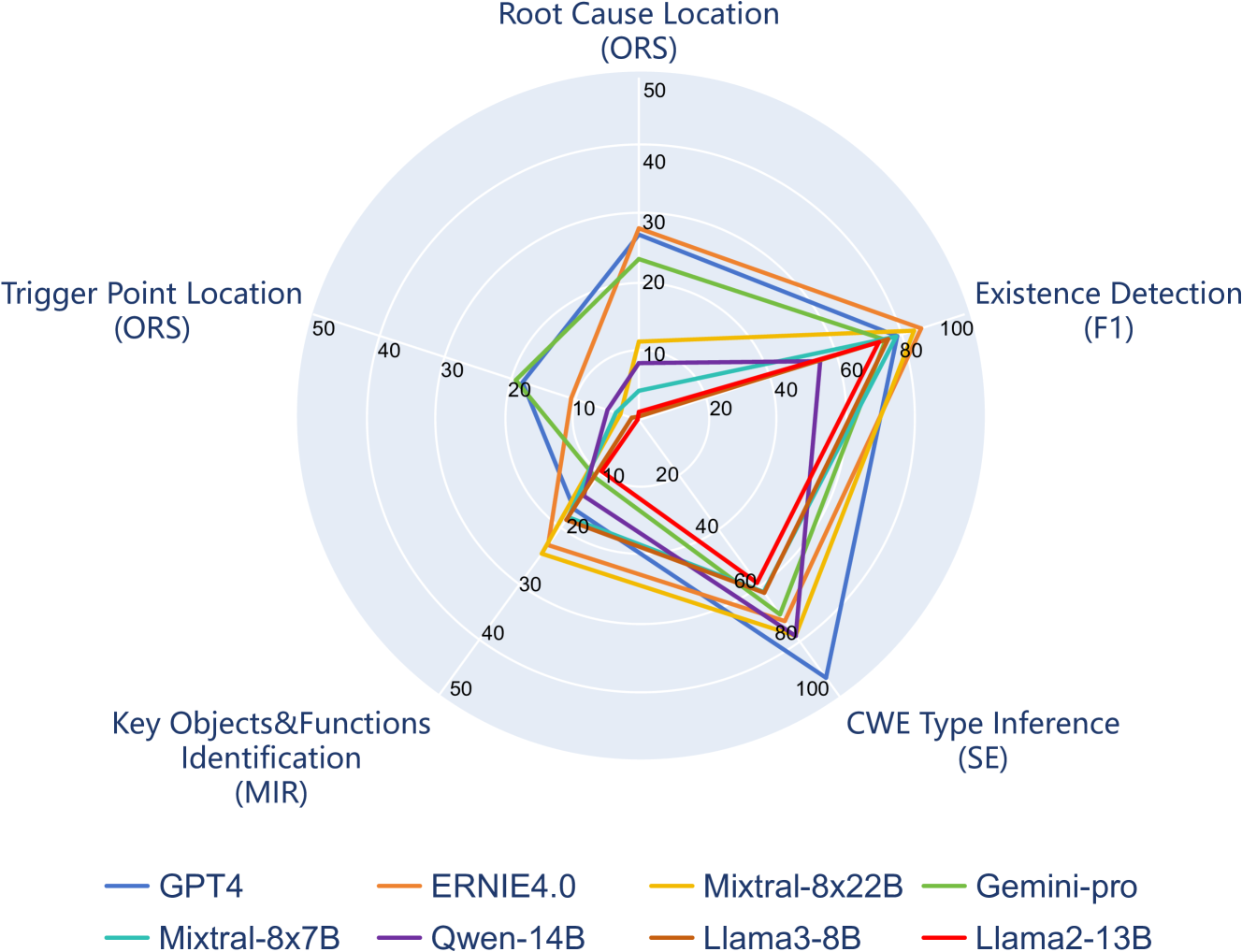
Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
Create account to get full access
Overview
- This paper presents VulDetectBench, a benchmark for evaluating the performance of large language models (LLMs) in detecting software vulnerabilities.
- The authors assess the deep capability of LLMs in vulnerability detection tasks across a diverse dataset of real-world vulnerabilities.
- VulDetectBench covers a wide range of vulnerability types and is designed to provide a rigorous and comprehensive evaluation of LLM-based vulnerability detection systems.
Plain English Explanation
The paper describes a new benchmark called VulDetectBench that is designed to test how well large language models (LLMs) can detect software vulnerabilities. Software vulnerabilities are weaknesses in software that can be exploited by attackers to gain unauthorized access or cause harm. As LLMs become more advanced, the researchers wanted to see how capable they are at identifying these vulnerabilities.
VulDetectBench is a collection of real-world software vulnerabilities that the researchers use to evaluate LLMs. It covers many different types of vulnerabilities, from basic coding errors to more complex security flaws. By testing the LLMs on this diverse set of vulnerabilities, the researchers can get a comprehensive understanding of the models' capabilities in this important area of cybersecurity.
The goal is to provide a rigorous and standardized way to assess how well LLMs can be used for vulnerability detection, which could have significant implications for improving software security. If LLMs prove to be effective at this task, it could lead to new tools and techniques for automatically finding and fixing vulnerabilities in software before they can be exploited by attackers.
Technical Explanation
The paper introduces VulDetectBench, a benchmark designed to evaluate the performance of large language models (LLMs) in detecting software vulnerabilities. The benchmark consists of a diverse dataset of real-world vulnerabilities from popular open-source projects, covering a wide range of vulnerability types.
To assess the deep capability of LLMs in vulnerability detection, the authors conduct experiments using several state-of-the-art LLM models, including GPT-3, T5, and InstructGPT. The models are evaluated on their ability to accurately identify the presence of vulnerabilities in code snippets, as well as provide relevant vulnerability details and mitigation strategies.
The authors also compare the performance of the LLM-based approaches to traditional machine learning and rule-based vulnerability detection techniques, using the CyberSecEval-2 benchmark as a reference.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of LLM-based vulnerability detection, which is an important and rapidly evolving area of research. The authors have carefully designed the VulDetectBench dataset to capture a diverse range of vulnerability types, which is crucial for assessing the generalization capabilities of the models.
However, the paper does not discuss potential limitations or biases in the dataset, such as the overrepresentation of certain vulnerability types or the potential for dataset shift between the training and evaluation data. Additionally, the authors do not explore the interpretability or explainability of the LLM-based vulnerability detection models, which could be a crucial factor in their real-world deployment and adoption.
Further research is needed to understand the robustness and reliability of LLM-based vulnerability detection systems in the face of adversarial attacks or evolving vulnerability patterns. The authors could also explore the potential for LLMs to assist in vulnerability remediation and mitigation, rather than just detection.
Conclusion
The VulDetectBench benchmark presented in this paper represents a significant contribution to the field of software vulnerability detection, providing a rigorous and standardized way to evaluate the performance of large language models in this important cybersecurity domain. The authors' comprehensive assessment of state-of-the-art LLMs suggests that these models have substantial potential for improving the automated detection of software vulnerabilities, which could lead to more secure software systems and better protect users from cyber threats. As the field of LLM-based vulnerability detection continues to evolve, the insights and lessons learned from this work will undoubtedly inform future research and development efforts in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
0
0
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
5/27/2024
🔎
Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning
Xiaohu Du, Ming Wen, Jiahao Zhu, Zifan Xie, Bin Ji, Huijun Liu, Xuanhua Shi, Hai Jin
0
0
Code Pre-trained Models (CodePTMs) based vulnerability detection have achieved promising results over recent years. However, these models struggle to generalize as they typically learn superficial mapping from source code to labels instead of understanding the root causes of code vulnerabilities, resulting in poor performance in real-world scenarios beyond the training instances. To tackle this challenge, we introduce VulLLM, a novel framework that integrates multi-task learning with Large Language Models (LLMs) to effectively mine deep-seated vulnerability features. Specifically, we construct two auxiliary tasks beyond the vulnerability detection task. First, we utilize the vulnerability patches to construct a vulnerability localization task. Second, based on the vulnerability features extracted from patches, we leverage GPT-4 to construct a vulnerability interpretation task. VulLLM innovatively augments vulnerability classification by leveraging generative LLMs to understand complex vulnerability patterns, thus compelling the model to capture the root causes of vulnerabilities rather than overfitting to spurious features of a single task. The experiments conducted on six large datasets demonstrate that VulLLM surpasses seven state-of-the-art models in terms of effectiveness, generalization, and robustness.
6/7/2024
Multitask-based Evaluation of Open-Source LLM on Software Vulnerability
Xin Yin, Chao Ni
0
0
This paper proposes a pipeline for quantitatively evaluating interactive LLMs using publicly available datasets. We carry out an extensive technical evaluation of LLMs using Big-Vul covering four different common software vulnerability tasks. We evaluate the multitask and multilingual aspects of LLMs based on this dataset. We find that the existing state-of-the-art methods are generally superior to LLMs in software vulnerability detection. Although LLMs improve accuracy when providing context information, they still have limitations in accurately predicting severity ratings for certain CWE types. In addition, LLMs demonstrate some ability to locate vulnerabilities for certain CWE types, but their performance varies among different CWE types. Finally, LLMs show uneven performance in generating CVE descriptions for various CWE types, with limited accuracy in a few-shot setting. Overall, though LLMs perform well in some aspects, they still need improvement in understanding the subtle differences in code vulnerabilities and the ability to describe vulnerabilities to fully realize their potential. Our evaluation pipeline provides valuable insights for further enhancing LLMs' software vulnerability handling capabilities.
4/3/2024

Security Vulnerability Detection with Multitask Self-Instructed Fine-Tuning of Large Language Models
Aidan Z. H. Yang, Haoye Tian, He Ye, Ruben Martins, Claire Le Goues
0
0
Software security vulnerabilities allow attackers to perform malicious activities to disrupt software operations. Recent Transformer-based language models have significantly advanced vulnerability detection, surpassing the capabilities of static analysis based deep learning models. However, language models trained solely on code tokens do not capture either the explanation of vulnerability type or the data flow structure information of code, both of which are crucial for vulnerability detection. We propose a novel technique that integrates a multitask sequence-to-sequence LLM with pro-gram control flow graphs encoded as a graph neural network to achieve sequence-to-classification vulnerability detection. We introduce MSIVD, multitask self-instructed fine-tuning for vulnerability detection, inspired by chain-of-thought prompting and LLM self-instruction. Our experiments demonstrate that MSIVD achieves superior performance, outperforming the highest LLM-based vulnerability detector baseline (LineVul), with a F1 score of 0.92 on the BigVul dataset, and 0.48 on the PreciseBugs dataset. By training LLMs and GNNs simultaneously using a combination of code and explanatory metrics of a vulnerable program, MSIVD represents a promising direction for advancing LLM-based vulnerability detection that generalizes to unseen data. Based on our findings, we further discuss the necessity for new labelled security vulnerability datasets, as recent LLMs have seen or memorized prior datasets' held-out evaluation data.
6/11/2024