Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study

0
💬
Sign in to get full access
Overview
• The paper presents a comprehensive benchmarking study to assess the capabilities of large language models (LLMs) for software vulnerability detection.
• The researchers evaluate multiple LLM-based approaches on a diverse set of software vulnerability datasets, providing insights into the strengths and limitations of these models for this task.
• The study aims to serve as a reference for future research and development of LLM-based vulnerability detection systems.
Plain English Explanation
Large language models (LLMs) are advanced artificial intelligence systems that can process and generate human-like text. Researchers have been exploring ways to harness the capabilities of these models for various applications, including cybersecurity tasks like software vulnerability detection.
Software vulnerabilities are weaknesses in computer programs that can be exploited by attackers to gain unauthorized access, steal data, or disrupt systems. Detecting these vulnerabilities early in the software development process is crucial for improving the overall security of computer systems.
The researchers in this study set out to comprehensively evaluate how well LLMs can perform at the task of software vulnerability detection. They tested multiple LLM-based approaches on a diverse range of software vulnerability datasets, examining the models' strengths and limitations.
The findings from this study provide important insights for researchers and practitioners in the field of cybersecurity. By understanding the capabilities and limitations of LLMs for vulnerability detection, they can better design and deploy these models to enhance the security of software systems.
Technical Explanation
The paper presents a comprehensive benchmarking study to evaluate the performance of large language models (LLMs) for the task of software vulnerability detection. The researchers tested multiple LLM-based approaches, including fine-tuning and prompt-based learning, on a diverse set of software vulnerability datasets.
The experiment design involved training and evaluating the LLM-based models on various vulnerability datasets, such as CyberSecEval-2, to assess their performance in identifying different types of vulnerabilities. The researchers also compared the LLM-based approaches with traditional machine learning models to understand the relative strengths and limitations of each approach.
The key findings of the study include insights into the effectiveness of LLMs for software vulnerability detection, the impact of dataset characteristics on model performance, and the potential for LLM-based approaches to complement existing vulnerability detection techniques. The researchers also discuss the implications of their findings for the development of LLM-based vulnerability detection systems.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of LLM-based approaches for software vulnerability detection, which is a crucial task in the field of cybersecurity. The researchers have carefully designed their experiments and leveraged a diverse set of datasets to assess the performance of these models.
One potential limitation of the study is that it focuses primarily on evaluating the models' ability to detect vulnerabilities, without delving into the specific types of vulnerabilities identified or the nuances of how the models approach this task. Additionally, the paper does not provide a deep analysis of the factors that contribute to the performance of LLM-based approaches, such as the impact of model architecture, training data, or fine-tuning strategies.
Further research could explore the interpretability and explainability of LLM-based vulnerability detection models, as well as investigate ways to improve their performance and robustness. Additionally, the integration of LLM-based approaches with traditional vulnerability detection techniques, as mentioned in the paper, could be a promising area for future work.
Conclusion
The paper presents a comprehensive benchmarking study that evaluates the capabilities of large language models (LLMs) for software vulnerability detection. The researchers have systematically assessed the performance of multiple LLM-based approaches on a diverse range of software vulnerability datasets, providing valuable insights into the strengths and limitations of these models.
The findings from this study have important implications for the development of LLM-based vulnerability detection systems, which could potentially enhance the security of software applications and computer systems. The insights gained from this research can inform future work in this area and contribute to the ongoing efforts to leverage advanced AI technologies for improved cybersecurity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
Read more5/27/2024
0
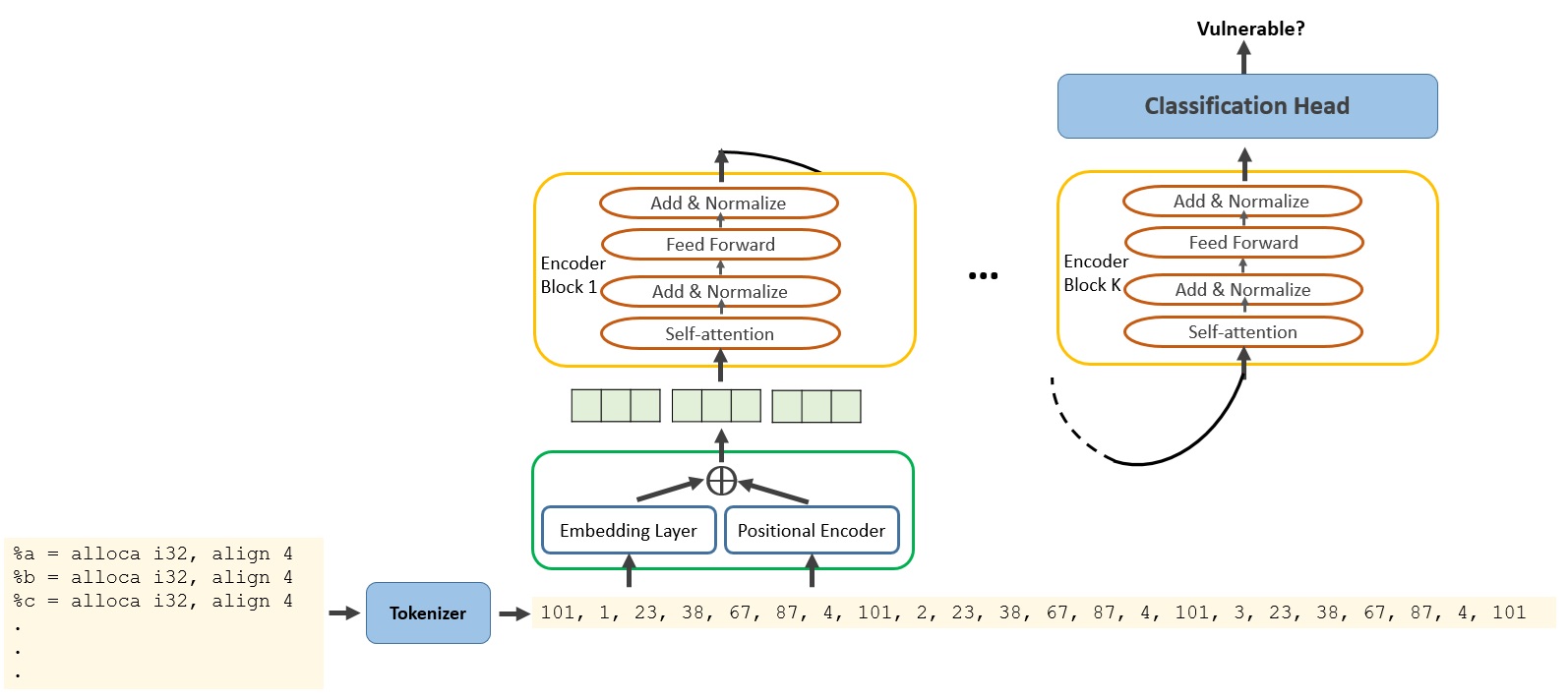
Harnessing the Power of LLMs in Source Code Vulnerability Detection
Andrew A Mahyari
Software vulnerabilities, caused by unintentional flaws in source code, are a primary root cause of cyberattacks. Static analysis of source code has been widely used to detect these unintentional defects introduced by software developers. Large Language Models (LLMs) have demonstrated human-like conversational abilities due to their capacity to capture complex patterns in sequential data, such as natural languages. In this paper, we harness LLMs' capabilities to analyze source code and detect known vulnerabilities. To ensure the proposed vulnerability detection method is universal across multiple programming languages, we convert source code to LLVM IR and train LLMs on these intermediate representations. We conduct extensive experiments on various LLM architectures and compare their accuracy. Our comprehensive experiments on real-world and synthetic codes from NVD and SARD demonstrate high accuracy in identifying source code vulnerabilities.
Read more8/9/2024
0
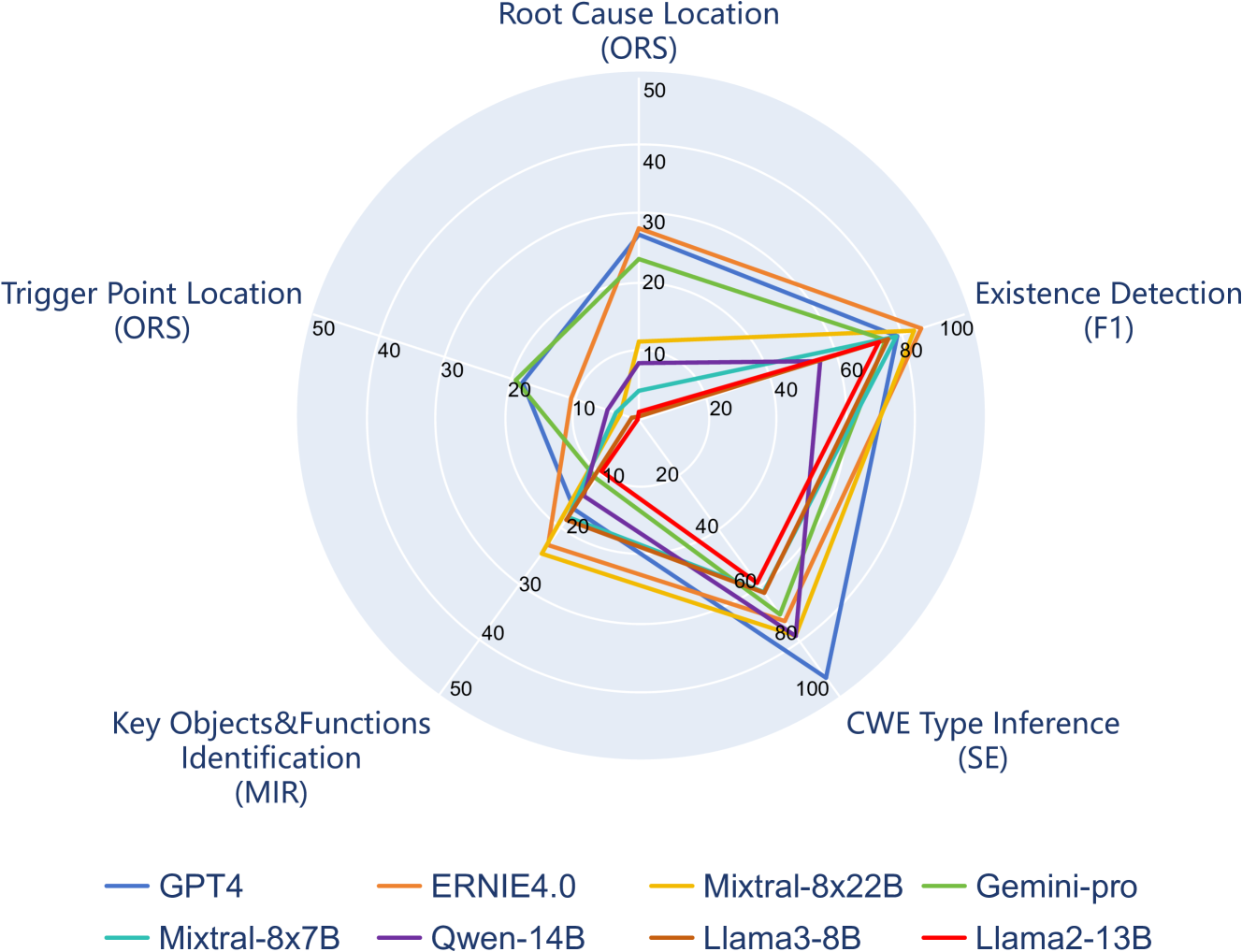
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
Yu Liu, Lang Gao, Mingxin Yang, Yu Xie, Ping Chen, Xiaojin Zhang, Wei Chen
Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
Read more8/22/2024
0
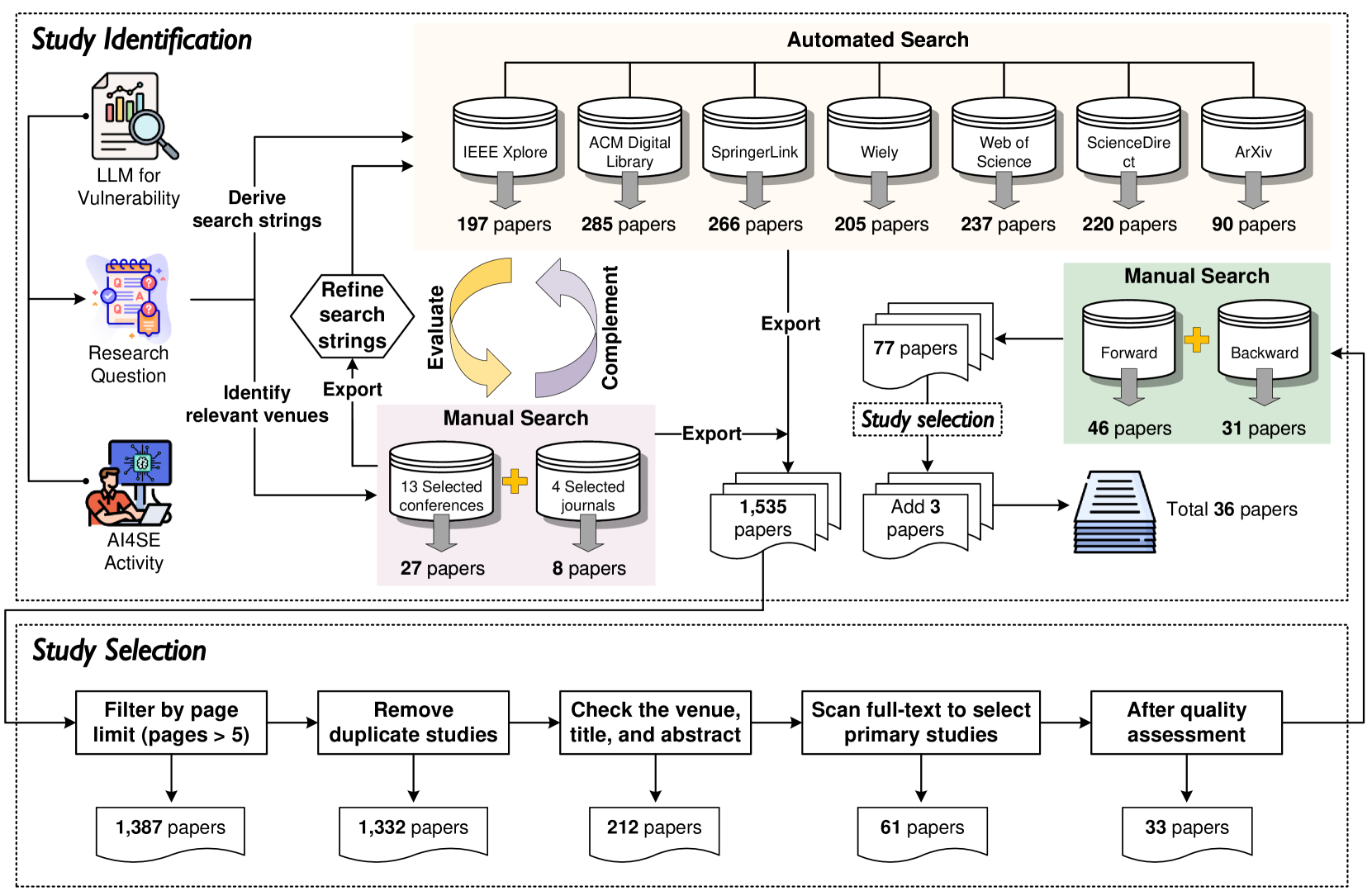
Large Language Model for Vulnerability Detection and Repair: Literature Review and Roadmap
Xin Zhou, Sicong Cao, Xiaobing Sun, David Lo
The significant advancements in Large Language Models (LLMs) have resulted in their widespread adoption across various tasks within Software Engineering (SE), including vulnerability detection and repair. Numerous recent studies have investigated the application of LLMs to enhance vulnerability detection and repair tasks. Despite the increasing research interest, there is currently no existing survey that focuses on the utilization of LLMs for vulnerability detection and repair. In this paper, we aim to bridge this gap by offering a systematic literature review of approaches aimed at improving vulnerability detection and repair through the utilization of LLMs. The review encompasses research work from leading SE, AI, and Security conferences and journals, covering 36 papers published at 21 distinct venues. By answering three key research questions, we aim to (1) summarize the LLMs employed in the relevant literature, (2) categorize various LLM adaptation techniques in vulnerability detection, and (3) classify various LLM adaptation techniques in vulnerability repair. Based on our findings, we have identified a series of challenges that still need to be tackled considering existing studies. Additionally, we have outlined a roadmap highlighting potential opportunities that we believe are pertinent and crucial for future research endeavors.
Read more4/4/2024