W-Net: A Facial Feature-Guided Face Super-Resolution Network

0

Sign in to get full access
Overview
- Introduces a new facial feature-guided face super-resolution network called W-Net
- Aims to improve the quality of face super-resolution by leveraging facial landmarks and facial attributes
- Proposes a novel two-branch architecture that integrates facial feature guidance and image super-resolution
Plain English Explanation
The paper introduces a new deep learning model called W-Net that is designed to improve the quality of face super-resolution. Face super-resolution is the process of taking a low-resolution image of a person's face and generating a higher-resolution version of it.
The key innovation in W-Net is that it incorporates guidance from facial landmarks and facial attributes, such as the positions of the eyes, nose, and mouth, as well as information about the person's age, gender, and expression. The idea is that by explicitly modeling these facial features, the network can generate super-resolved faces that are more faithful to the original.
W-Net has a two-branch architecture, with one branch focused on extracting and encoding the facial feature information, and the other branch focused on the actual super-resolution task. The outputs of these two branches are then combined to produce the final high-resolution face image.
The authors demonstrate that W-Net outperforms existing state-of-the-art face super-resolution methods, both in terms of objective image quality metrics and subjective human evaluations. This suggests that leveraging facial feature guidance can be a valuable approach for improving face super-resolution.
Technical Explanation
The paper proposes a new facial feature-guided face super-resolution network called W-Net. The key elements of the model are:
-
Two-Branch Architecture: W-Net has a two-branch structure, with one branch focused on extracting and encoding facial features, and the other branch focused on the super-resolution task. The outputs of these two branches are then combined to produce the final high-resolution face image.
-
Facial Feature Guidance: The facial feature branch of W-Net takes in facial landmarks and facial attribute information, such as the positions of the eyes, nose, and mouth, as well as attributes like age, gender, and expression. This helps the network better model the specific facial characteristics of the input low-resolution face.
-
Multi-Scale Fusion: The authors use a multi-scale fusion approach, where features from different layers of the network are combined to capture information at multiple resolutions. This helps preserve important details during the super-resolution process.
-
Perceptual Losses: In addition to standard pixel-wise and adversarial losses, the authors also use perceptual losses that focus on matching high-level feature representations between the super-resolved output and the ground truth high-resolution image. This encourages the model to generate visually plausible and perceptually realistic face images.
The authors evaluate W-Net on several face super-resolution benchmarks and show that it outperforms existing state-of-the-art methods in terms of both quantitative metrics and subjective human evaluations. This demonstrates the value of incorporating facial feature guidance for improving face super-resolution performance.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed W-Net model, including comparisons to several state-of-the-art methods. The authors acknowledge some limitations, such as the potential for the facial feature guidance to be less effective for very low-resolution inputs, and suggest directions for future work, such as exploring more advanced facial feature extraction techniques.
One potential concern is that the reliance on facial landmarks and attributes may make the model more sensitive to errors in these inputs, which could impact the super-resolution quality. The authors do not extensively discuss the robustness of their approach to noisy or incomplete facial feature information.
Additionally, while the paper demonstrates the effectiveness of W-Net on standard face super-resolution benchmarks, it would be valuable to see how the model performs on more diverse and realistic face image datasets that better reflect the challenges of real-world applications.
Overall, the W-Net model presents a promising approach to leveraging facial feature guidance for improved face super-resolution, and the paper provides a solid technical contribution to the field. Further exploration of the robustness and generalization of the approach would be valuable for strengthening the impact of this work.
Conclusion
The W-Net paper introduces a novel facial feature-guided face super-resolution network that outperforms existing methods. By explicitly modeling facial landmarks and attributes, the model is able to generate higher-quality super-resolved face images that better capture the specific characteristics of the input.
The two-branch architecture and multi-scale fusion techniques used in W-Net demonstrate the value of integrating facial feature guidance into the super-resolution process. This work represents an important step forward in improving the quality and fidelity of face super-resolution, which has applications in areas such as surveillance, photography, and video conferencing.
While the paper has some limitations, such as the potential sensitivity to errors in facial feature inputs, the overall approach and results suggest that facial feature guidance is a promising direction for further research and development in the field of face super-resolution.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
W-Net: A Facial Feature-Guided Face Super-Resolution Network
Hao Liu, Yang Yang, Yunxia Liu
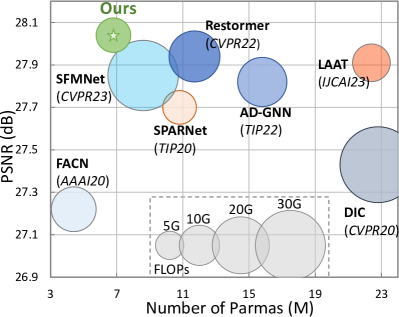
Face Super-Resolution (FSR) aims to recover high-resolution (HR) face images from low-resolution (LR) ones. Despite the progress made by convolutional neural networks in FSR, the results of existing approaches are not ideal due to their low reconstruction efficiency and insufficient utilization of prior information. Considering that faces are highly structured objects, effectively leveraging facial priors to improve FSR results is a worthwhile endeavor. This paper proposes a novel network architecture called W-Net to address this challenge. W-Net leverages meticulously designed Parsing Block to fully exploit the resolution potential of LR image. We use this parsing map as an attention prior, effectively integrating information from both the parsing map and LR images. Simultaneously, we perform multiple fusions in various dimensions through the W-shaped network structure combined with the LPF(LR-Parsing Map Fusion Module). Additionally, we utilize a facial parsing graph as a mask, assigning different weights and loss functions to key facial areas to balance the performance of our reconstructed facial images between perceptual quality and pixel accuracy. We conducted extensive comparative experiments, not only limited to conventional facial super-resolution metrics but also extending to downstream tasks such as facial recognition and facial keypoint detection. The experiments demonstrate that W-Net exhibits outstanding performance in quantitative metrics, visual quality, and downstream tasks.
Read more6/26/2024
0
Efficient Face Super-Resolution via Wavelet-based Feature Enhancement Network
Wenjie Li, Heng Guo, Xuannan Liu, Kongming Liang, Jiani Hu, Zhanyu Ma, Jun Guo
Face super-resolution aims to reconstruct a high-resolution face image from a low-resolution face image. Previous methods typically employ an encoder-decoder structure to extract facial structural features, where the direct downsampling inevitably introduces distortions, especially to high-frequency features such as edges. To address this issue, we propose a wavelet-based feature enhancement network, which mitigates feature distortion by losslessly decomposing the input feature into high and low-frequency components using the wavelet transform and processing them separately. To improve the efficiency of facial feature extraction, a full domain Transformer is further proposed to enhance local, regional, and global facial features. Such designs allow our method to perform better without stacking many modules as previous methods did. Experiments show that our method effectively balances performance, model size, and speed. Code link: https://github.com/PRIS-CV/WFEN.
Read more7/31/2024
🌐
0
Teacher-Student Network for Real-World Face Super-Resolution with Progressive Embedding of Edge Information
Zhilei Liu, Chenggong Zhang
Traditional face super-resolution (FSR) methods trained on synthetic datasets usually have poor generalization ability for real-world face images. Recent work has utilized complex degradation models or training networks to simulate the real degradation process, but this limits the performance of these methods due to the domain differences that still exist between the generated low-resolution images and the real low-resolution images. Moreover, because of the existence of a domain gap, the semantic feature information of the target domain may be affected when synthetic data and real data are utilized to train super-resolution models simultaneously. In this study, a real-world face super-resolution teacher-student model is proposed, which considers the domain gap between real and synthetic data and progressively includes diverse edge information by using the recurrent network's intermediate outputs. Extensive experiments demonstrate that our proposed approach surpasses state-of-the-art methods in obtaining high-quality face images for real-world FSR.
Read more5/9/2024

0
Attention-Guided Multi-scale Interaction Network for Face Super-Resolution
Xujie Wan, Wenjie Li, Guangwei Gao, Huimin Lu, Jian Yang, Chia-Wen Lin
Recently, CNN and Transformer hybrid networks demonstrated excellent performance in face super-resolution (FSR) tasks. Since numerous features at different scales in hybrid networks, how to fuse these multi-scale features and promote their complementarity is crucial for enhancing FSR. However, existing hybrid network-based FSR methods ignore this, only simply combining the Transformer and CNN. To address this issue, we propose an attention-guided Multi-scale interaction network (AMINet), which contains local and global feature interactions as well as encoder-decoder phases feature interactions. Specifically, we propose a Local and Global Feature Interaction Module (LGFI) to promote fusions of global features and different receptive fields' local features extracted by our Residual Depth Feature Extraction Module (RDFE). Additionally, we propose a Selective Kernel Attention Fusion Module (SKAF) to adaptively select fusions of different features within LGFI and encoder-decoder phases. Our above design allows the free flow of multi-scale features from within modules and between encoder and decoder, which can promote the complementarity of different scale features to enhance FSR. Comprehensive experiments confirm that our method consistently performs well with less computational consumption and faster inference.
Read more9/4/2024