LASER: A Neuro-Symbolic Framework for Learning Spatial-Temporal Scene Graphs with Weak Supervision

0
🌀
Sign in to get full access
Overview
- Proposes a neuro-symbolic approach called LASER to learn semantic video representations
- Aligns raw videos with spatio-temporal logic specifications using a differentiable symbolic reasoner and various losses
- Learns fine-grained video representation in the form of a spatio-temporal scene graph
- Weakly supervises the learning process by deriving logic specifications from video captions
Plain English Explanation
LASER is a new method that aims to help computers better understand the spatial and temporal aspects of video data. It does this by aligning the raw video footage with high-level logic rules that describe the key events and relationships in the video.
The key idea is to train a machine learning model to extract a detailed, structured representation of the video content - a "spatio-temporal scene graph" - that matches the logic rules. This is achieved through a combination of techniques, including a differentiable symbolic reasoner and specialized loss functions that capture different aspects of the video semantics.
To make the training process more practical, the method also explores deriving the logic rules automatically from video captions, rather than requiring costly manual annotations. This allows the model to be trained using widely available video-caption data.
The researchers evaluate LASER on several video datasets and show that it learns better video understanding than existing approaches. This suggests the potential of neuro-symbolic methods like LASER to bridge the gap between low-level perception and high-level reasoning in video understanding.
Technical Explanation
The core of LASER is an alignment algorithm that maps raw video data to high-level spatio-temporal logic specifications. This is achieved through a combination of a differentiable symbolic reasoner and a set of specialized loss functions.
The symbolic reasoner takes as input a set of logic rules that describe the key events, objects, and relationships in the video. It then computes a differentiable score indicating how well the video aligns with these logic rules. This score is used as part of the training objective, along with contrastive, temporal, and semantic losses, to train the video representation model.
The end result is a fine-grained "spatio-temporal scene graph" representation of the video content that conforms to the desired logic specifications. To avoid the need for costly manual annotations, the method derives the logic rules automatically from video captions using a large language model.
The researchers evaluate LASER on several datasets, including 20BN-Something-Something, MUGEN, and OpenPVSG. They show that LASER learns better video understanding than existing baselines, as measured by the quality of the extracted spatio-temporal scene graphs.
Critical Analysis
The LASER paper presents a novel and promising approach to video understanding, but it also has some limitations and open questions:
- The method relies on having access to high-quality logic rules or captions to drive the learning process. In real-world scenarios, this information may not always be readily available.
- The effectiveness of deriving logic rules from captions is an open question and may depend heavily on the quality and coverage of the language model used.
- The paper does not explore the robustness of the method to noisy or incomplete logic specifications, which could be important for real-world deployment.
- While the experiments demonstrate the method's effectiveness on specific datasets, further research is needed to understand its broader applicability and generalization capabilities.
Overall, LASER represents an interesting step towards bridging the gap between low-level perception and high-level reasoning in video understanding. The neuro-symbolic approach shows promise, but there are still challenges to address before the method can be widely deployed in practice.
Conclusion
The LASER paper proposes a novel neuro-symbolic approach to learning semantic video representations. By aligning raw video data with high-level spatio-temporal logic specifications, the method is able to extract fine-grained, structured representations of video content in the form of scene graphs.
The key innovation is the use of a differentiable symbolic reasoner, which allows the model to be trained end-to-end using a combination of specialized loss functions. The method also explores deriving the logic specifications automatically from video captions, reducing the need for costly manual annotations.
Evaluated on several video understanding benchmarks, LASER demonstrates superior performance compared to existing baselines. This suggests the potential of neuro-symbolic approaches like LASER to enable more robust and interpretable video understanding capabilities, with implications for a wide range of applications, from autonomous systems to video analysis and retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
LASER: A Neuro-Symbolic Framework for Learning Spatial-Temporal Scene Graphs with Weak Supervision
Jiani Huang, Ziyang Li, Mayur Naik, Ser-Nam Lim
We propose LASER, a neuro-symbolic approach to learn semantic video representations that capture rich spatial and temporal properties in video data by leveraging high-level logic specifications. In particular, we formulate the problem in terms of alignment between raw videos and spatio-temporal logic specifications. The alignment algorithm leverages a differentiable symbolic reasoner and a combination of contrastive, temporal, and semantics losses. It effectively and efficiently trains low-level perception models to extract a fine-grained video representation in the form of a spatio-temporal scene graph that conforms to the desired high-level specification. To practically reduce the manual effort of obtaining ground truth labels, we derive logic specifications from captions by employing a large language model with a generic prompting template. In doing so, we explore a novel methodology that weakly supervises the learning of spatio-temporal scene graphs with widely accessible video-caption data. We evaluate our method on three datasets with rich spatial and temporal specifications: 20BN-Something-Something, MUGEN, and OpenPVSG. We demonstrate that our method learns better fine-grained video semantics than existing baselines.
Read more6/13/2024

0
Towards Neuro-Symbolic Video Understanding
Minkyu Choi, Harsh Goel, Mohammad Omama, Yunhao Yang, Sahil Shah, Sandeep Chinchali
The unprecedented surge in video data production in recent years necessitates efficient tools to extract meaningful frames from videos for downstream tasks. Long-term temporal reasoning is a key desideratum for frame retrieval systems. While state-of-the-art foundation models, like VideoLLaMA and ViCLIP, are proficient in short-term semantic understanding, they surprisingly fail at long-term reasoning across frames. A key reason for this failure is that they intertwine per-frame perception and temporal reasoning into a single deep network. Hence, decoupling but co-designing semantic understanding and temporal reasoning is essential for efficient scene identification. We propose a system that leverages vision-language models for semantic understanding of individual frames but effectively reasons about the long-term evolution of events using state machines and temporal logic (TL) formulae that inherently capture memory. Our TL-based reasoning improves the F1 score of complex event identification by 9-15% compared to benchmarks that use GPT4 for reasoning on state-of-the-art self-driving datasets such as Waymo and NuScenes.
Read more7/17/2024

0
LLaVA-SG: Leveraging Scene Graphs as Visual Semantic Expression in Vision-Language Models
Jingyi Wang, Jianzhong Ju, Jian Luan, Zhidong Deng
Recent advances in large vision-language models (VLMs) typically employ vision encoders based on the Vision Transformer (ViT) architecture. The division of the images into patches by ViT results in a fragmented perception, thereby hindering the visual understanding capabilities of VLMs. In this paper, we propose an innovative enhancement to address this limitation by introducing a Scene Graph Expression (SGE) module in VLMs. This module extracts and structurally expresses the complex semantic information within images, thereby improving the foundational perception and understanding abilities of VLMs. Extensive experiments demonstrate that integrating our SGE module significantly enhances the VLM's performance in vision-language tasks, indicating its effectiveness in preserving intricate semantic details and facilitating better visual understanding.
Read more9/2/2024
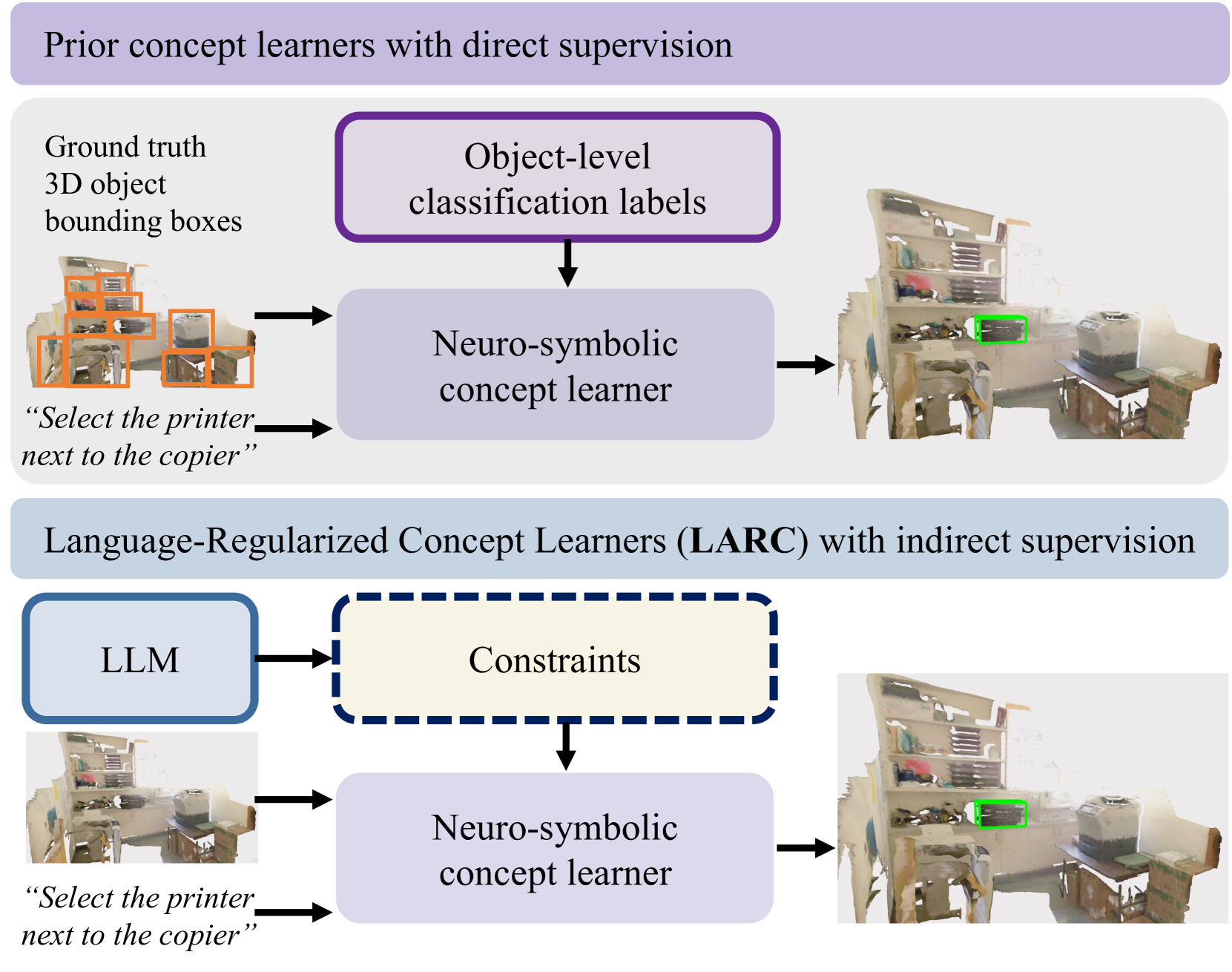
0
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Chun Feng, Joy Hsu, Weiyu Liu, Jiajun Wu
3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
Read more5/1/2024