Weight Scope Alignment: A Frustratingly Easy Method for Model Merging

0
Sign in to get full access
Overview
- The paper proposes a simple method called "Weight Scope Alignment" for merging multiple deep learning models.
- The method aligns the weights of the models by matching their scopes, without requiring any training or fine-tuning.
- The authors show that this simple technique can achieve comparable or better performance than complex model merging approaches.
Plain English Explanation
Weight Scope Alignment: A Frustratingly Easy Method for Model Merging is a study that looks at a straightforward way to combine multiple deep learning models into a single, more powerful model. The key idea is to align the weight parameters of the different models by matching their "scopes" - the range of values the weights can take on.
This alignment process doesn't require any additional training or fine-tuning of the models. The authors show that this simple technique can produce a merged model that performs as well as or better than more complex model merging approaches.
The main advantage of this method is its simplicity. Merging models is often a complex task, but Weight Scope Alignment provides a frustratingly easy way to do it effectively.
Technical Explanation
The paper first reviews previous work on model merging, which has often involved complex techniques like fine-tuning or knowledge distillation. In contrast, the authors propose the Weight Scope Alignment method, which involves aligning the weight ranges of the different models to be merged.
Specifically, the method works as follows:
- Identify the weight scopes: For each layer in the models, determine the minimum and maximum values of the weights.
- Align the weight scopes: Linearly rescale the weights in each layer to match a common weight scope across all models.
- Combine the aligned models: Merge the rescaled weights from the different models into a single model.
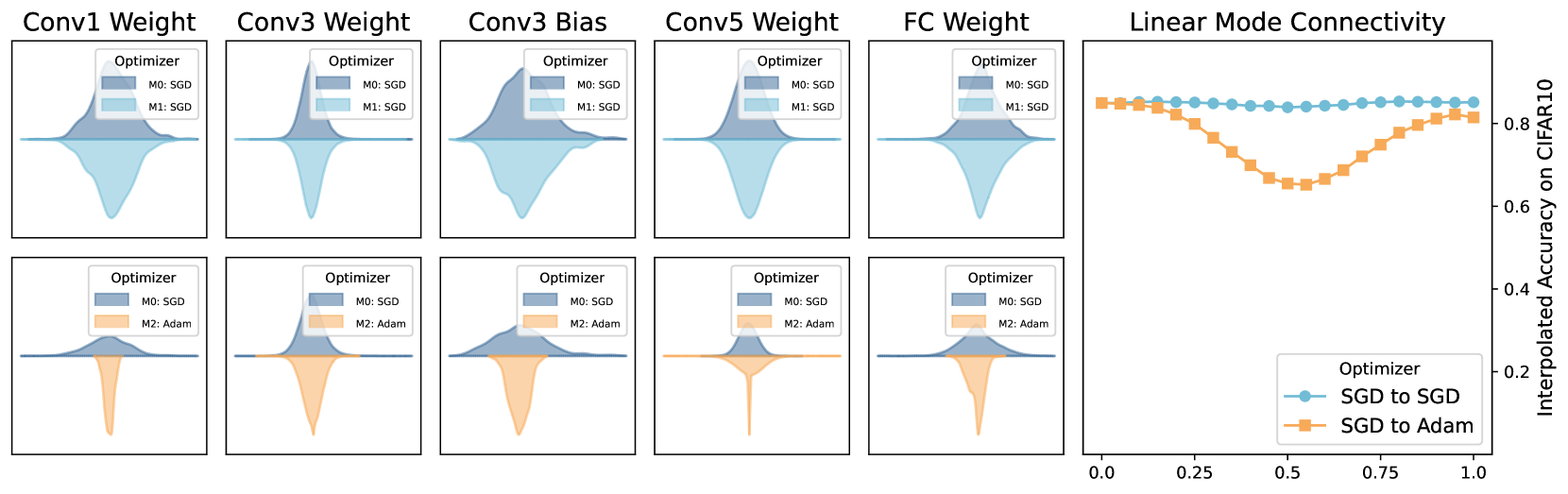
The authors evaluate this approach on a variety of computer vision and natural language processing tasks, and find that it can match or exceed the performance of more complex model merging techniques. They attribute this to the method's ability to preserve the learned representations from the original models.
Critical Analysis
The Weight Scope Alignment paper presents a simple yet effective approach to model merging. One potential limitation is that the method may not work as well for models with very different architectures or training procedures. The authors acknowledge this and suggest that their technique may be most suitable for merging similar models trained on related tasks.
Additionally, the paper does not extensively explore the theoretical underpinnings of why weight scope alignment works well. Further research could investigate the conditions and properties that make this method effective for model merging.
Overall, the Weight Scope Alignment approach provides a simple and practical way to combine multiple deep learning models, which could be valuable in scenarios where model reuse and collaboration are important.
Conclusion
The Weight Scope Alignment paper presents a simple yet effective method for merging deep learning models. By aligning the weight ranges of the models, the technique can produce a combined model that performs as well as or better than more complex merging approaches.
This straightforward technique could be useful in a variety of scenarios where model reuse and collaboration are important, such as in large-scale AI systems or federated learning environments. The paper's findings suggest that simplicity can sometimes be a virtue in model engineering, and that there may be more to learn about the underlying principles that make this approach effective.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Weight Scope Alignment: A Frustratingly Easy Method for Model Merging
Yichu Xu, Xin-Chun Li, Le Gan, De-Chuan Zhan
Merging models becomes a fundamental procedure in some applications that consider model efficiency and robustness. The training randomness or Non-I.I.D. data poses a huge challenge for averaging-based model fusion. Previous research efforts focus on element-wise regularization or neural permutations to enhance model averaging while overlooking weight scope variations among models, which can significantly affect merging effectiveness. In this paper, we reveal variations in weight scope under different training conditions, shedding light on its influence on model merging. Fortunately, the parameters in each layer basically follow the Gaussian distribution, which inspires a novel and simple regularization approach named Weight Scope Alignment (WSA). It contains two key components: 1) leveraging a target weight scope to guide the model training process for ensuring weight scope matching in the subsequent model merging. 2) fusing the weight scope of two or more models into a unified one for multi-stage model fusion. We extend the WSA regularization to two different scenarios, including Mode Connectivity and Federated Learning. Abundant experimental studies validate the effectiveness of our approach.
Read more8/23/2024
📈
0
Model Merging by Uncertainty-Based Gradient Matching
Nico Daheim, Thomas Mollenhoff, Edoardo Maria Ponti, Iryna Gurevych, Mohammad Emtiyaz Khan
Models trained on different datasets can be merged by a weighted-averaging of their parameters, but why does it work and when can it fail? Here, we connect the inaccuracy of weighted-averaging to mismatches in the gradients and propose a new uncertainty-based scheme to improve the performance by reducing the mismatch. The connection also reveals implicit assumptions in other schemes such as averaging, task arithmetic, and Fisher-weighted averaging. Our new method gives consistent improvements for large language models and vision transformers, both in terms of performance and robustness to hyperparameters. Code available here.
Read more8/26/2024
🧪
0
Exploring Learngene via Stage-wise Weight Sharing for Initializing Variable-sized Models
Shi-Yu Xia, Wenxuan Zhu, Xu Yang, Xin Geng
In practice, we usually need to build variable-sized models adapting for diverse resource constraints in different application scenarios, where weight initialization is an important step prior to training. The Learngene framework, introduced recently, firstly learns one compact part termed as learngene from a large well-trained model, after which learngene is expanded to initialize variable-sized models. In this paper, we start from analysing the importance of guidance for the expansion of well-trained learngene layers, inspiring the design of a simple but highly effective Learngene approach termed SWS (Stage-wise Weight Sharing), where both learngene layers and their learning process critically contribute to providing knowledge and guidance for initializing models at varying scales. Specifically, to learn learngene layers, we build an auxiliary model comprising multiple stages where the layer weights in each stage are shared, after which we train it through distillation. Subsequently, we expand these learngene layers containing stage information at their corresponding stage to initialize models of variable depths. Extensive experiments on ImageNet-1K demonstrate that SWS achieves consistent better performance compared to many models trained from scratch, while reducing around 6.6x total training costs. In some cases, SWS performs better only after 1 epoch tuning. When initializing variable-sized models adapting for different resource constraints, SWS achieves better results while reducing around 20x parameters stored to initialize these models and around 10x pre-training costs, in contrast to the pre-training and fine-tuning approach.
Read more4/29/2024

0
Weights Augmentation: it has never ever ever ever let her model down
Junbin Zhuang, Guiguang Din, Yunyi Yan
Weight play an essential role in deep learning network models. Unlike network structure design, this article proposes the concept of weight augmentation, focusing on weight exploration. The core of Weight Augmentation Strategy (WAS) is to adopt random transformed weight coefficients training and transformed coefficients, named Shadow Weight(SW), for networks that can be used to calculate loss function to affect parameter updates. However, stochastic gradient descent is applied to Plain Weight(PW), which is referred to as the original weight of the network before the random transformation. During training, numerous SW collectively form high-dimensional space, while PW is directly learned from the distribution of SW instead of the data. The weight of the accuracy-oriented mode(AOM) relies on PW, which guarantees the network is highly robust and accurate. The desire-oriented mode(DOM) weight uses SW, which is determined by the network model's unique functions based on WAT's performance desires, such as lower computational complexity, lower sensitivity to particular data, etc. The dual mode be switched at anytime if needed. WAT extends the augmentation technique from data augmentation to weight, and it is easy to understand and implement, but it can improve almost all networks amazingly. Our experimental results show that convolutional neural networks, such as VGG-16, ResNet-18, ResNet-34, GoogleNet, MobilementV2, and Efficientment-Lite, can benefit much at little or no cost. The accuracy of models is on the CIFAR100 and CIFAR10 datasets, which can be evaluated to increase by 7.32% and 9.28%, respectively, with the highest values being 13.42% and 18.93%, respectively. In addition, DOM can reduce floating point operations (FLOPs) by up to 36.33%. The code is available at https://github.com/zlearh/Weight-Augmentation-Technology.
Read more5/31/2024