Model Merging by Uncertainty-Based Gradient Matching

0
📈
Sign in to get full access
Overview
- Merging models trained on different datasets can be done by weighted-averaging their parameters.
- This technique can fail due to mismatches in the gradients of the models.
- The paper proposes a new uncertainty-based scheme to improve performance by reducing gradient mismatch.
- The proposed method gives consistent improvements for large language models and vision transformers.
Plain English Explanation
When training machine learning models, it's often useful to combine models trained on different datasets. One way to do this is by weight-averaging the parameters of the models.
However, this weight-averaging approach can sometimes fail. The reason is that the gradients, or the directions the models are being trained to move in, may not match up between the different models. This gradient mismatch can cause issues when trying to combine the models.
To address this, the researchers propose a new method that uses uncertainty information to reduce the gradient mismatch. This helps the combined model perform better and be more robust to changes in the training hyperparameters.
The key idea is to use the uncertainty of each model's predictions to determine how much to weigh its parameters when combining the models. This helps ensure that the gradients of the combined model are well-aligned, leading to better performance.
Technical Explanation
The paper explores the problem of merging models trained on different datasets by weighted-averaging their parameters. The authors connect the inaccuracy of this weighted-averaging approach to mismatches in the gradients of the models.
To address this, the researchers propose a new uncertainty-based scheme that aims to improve performance by reducing the gradient mismatch. The connection they make also reveals implicit assumptions in other model merging techniques, such as averaging, task arithmetic, and Fisher-weighted averaging.
The proposed uncertainty-based method uses information about the models' predictive uncertainties to determine how to weigh their parameters when combining them. This helps ensure that the gradients of the combined model are well-aligned, leading to better performance and robustness to hyperparameter changes.
The researchers evaluate their method on large language models and vision transformers, and show that it consistently outperforms other model merging approaches in terms of both performance and robustness.
Critical Analysis
The paper provides a thoughtful analysis of the limitations of weighted-averaging for merging models and proposes a novel uncertainty-based approach to address this issue. The authors make a clear connection between gradient mismatch and the inaccuracy of weighted-averaging, which is a valuable insight.
One potential area for further research could be exploring the sensitivity of the uncertainty-based method to the quality of the uncertainty estimates. If the uncertainty estimates are not accurate, this could impact the effectiveness of the proposed approach.
Additionally, the paper focuses on large language models and vision transformers, but it would be interesting to see how the method performs on a wider range of model architectures and tasks. Expanding the evaluation to include more diverse datasets and use cases could help validate the generalizability of the findings.
Overall, the paper presents a well-designed study with a solid theoretical foundation and promising empirical results. The proposed uncertainty-based method appears to be a meaningful contribution to the model merging literature.
Conclusion
This paper tackles the challenge of merging models trained on different datasets by introducing a new uncertainty-based scheme. The key insight is that weighted-averaging of model parameters can fail due to mismatches in the gradients, and the proposed approach aims to reduce this mismatch.
The researchers show that their uncertainty-based method consistently improves performance and robustness compared to other model merging techniques, such as averaging and task arithmetic. This work has important implications for efficiently combining the knowledge encoded in multiple machine learning models, which is a common task in real-world applications.
By providing a deeper understanding of the limitations of existing approaches and offering a novel solution, this paper advances the state of the art in model merging and could have a significant impact on the development of more powerful and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Model Merging by Uncertainty-Based Gradient Matching
Nico Daheim, Thomas Mollenhoff, Edoardo Maria Ponti, Iryna Gurevych, Mohammad Emtiyaz Khan
Models trained on different datasets can be merged by a weighted-averaging of their parameters, but why does it work and when can it fail? Here, we connect the inaccuracy of weighted-averaging to mismatches in the gradients and propose a new uncertainty-based scheme to improve the performance by reducing the mismatch. The connection also reveals implicit assumptions in other schemes such as averaging, task arithmetic, and Fisher-weighted averaging. Our new method gives consistent improvements for large language models and vision transformers, both in terms of performance and robustness to hyperparameters. Code available here.
Read more8/26/2024
0
Weight Scope Alignment: A Frustratingly Easy Method for Model Merging
Yichu Xu, Xin-Chun Li, Le Gan, De-Chuan Zhan
Merging models becomes a fundamental procedure in some applications that consider model efficiency and robustness. The training randomness or Non-I.I.D. data poses a huge challenge for averaging-based model fusion. Previous research efforts focus on element-wise regularization or neural permutations to enhance model averaging while overlooking weight scope variations among models, which can significantly affect merging effectiveness. In this paper, we reveal variations in weight scope under different training conditions, shedding light on its influence on model merging. Fortunately, the parameters in each layer basically follow the Gaussian distribution, which inspires a novel and simple regularization approach named Weight Scope Alignment (WSA). It contains two key components: 1) leveraging a target weight scope to guide the model training process for ensuring weight scope matching in the subsequent model merging. 2) fusing the weight scope of two or more models into a unified one for multi-stage model fusion. We extend the WSA regularization to two different scenarios, including Mode Connectivity and Federated Learning. Abundant experimental studies validate the effectiveness of our approach.
Read more8/23/2024
0
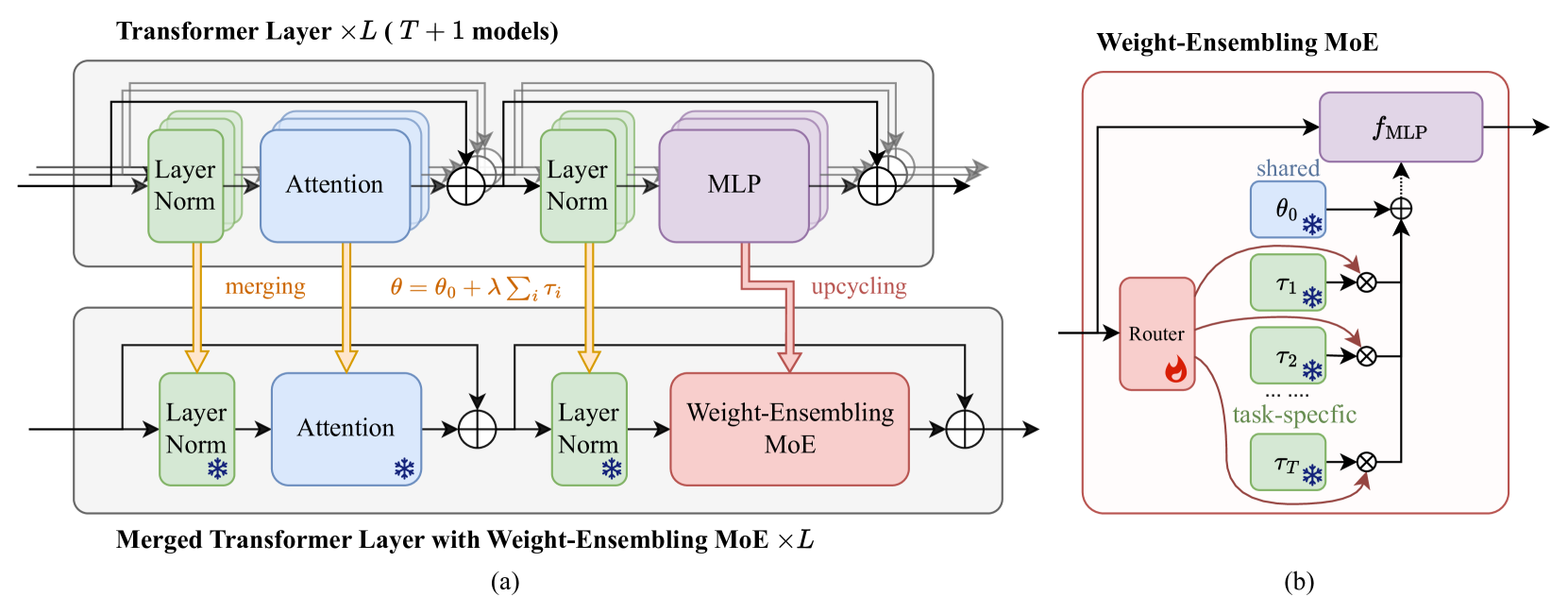
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
Read more6/10/2024
💬
0
Fisher Mask Nodes for Language Model Merging
Thennal D K, Ganesh Nathan, Suchithra M S
Fine-tuning pre-trained models provides significant advantages in downstream performance. The ubiquitous nature of pre-trained models such as BERT and its derivatives in natural language processing has also led to a proliferation of task-specific fine-tuned models. As these models typically only perform one task well, additional training or ensembling is required in multi-task scenarios. The growing field of model merging provides a solution, dealing with the challenge of combining multiple task-specific models into a single multi-task model. In this study, we introduce a novel model merging method for Transformers, combining insights from previous work in Fisher-weighted averaging and the use of Fisher information in model pruning. Utilizing the Fisher information of mask nodes within the Transformer architecture, we devise a computationally efficient weighted-averaging scheme. Our method exhibits a regular and significant performance increase across various models in the BERT family, outperforming full-scale Fisher-weighted averaging in a fraction of the computational cost, with baseline performance improvements of up to +6.5 and a speedup between 57.4x and 321.7x across models. Our results prove the potential of our method in current multi-task learning environments and suggest its scalability and adaptability to new model architectures and learning scenarios.
Read more5/6/2024