What If We Recaption Billions of Web Images with LLaMA-3?
2406.08478
92
0

Abstract
Web-crawled image-text pairs are inherently noisy. Prior studies demonstrate that semantically aligning and enriching textual descriptions of these pairs can significantly enhance model training across various vision-language tasks, particularly text-to-image generation. However, large-scale investigations in this area remain predominantly closed-source. Our paper aims to bridge this community effort, leveraging the powerful and textit{open-sourced} LLaMA-3, a GPT-4 level LLM. Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption 1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. For discriminative models like CLIP, we observe enhanced zero-shot performance in cross-modal retrieval tasks. For generative models like text-to-image Diffusion Transformers, the generated images exhibit a significant improvement in alignment with users' text instructions, especially in following complex queries. Our project page is https://www.haqtu.me/Recap-Datacomp-1B/
Create account to get full access
Overview
- This paper explores the potential of using the large language model LLaMA-3 to automatically generate captions for billions of web images.
- The researchers investigate the feasibility and potential impact of such a large-scale image captioning effort.
- They examine the technical challenges, quality considerations, and societal implications of recaptioning the web at such a massive scale.
Plain English Explanation
The researchers in this paper are interested in what would happen if they used a powerful AI language model called LLaMA-3 to automatically generate captions for billions of images on the web. Currently, most images on the internet do not have detailed captions that describe what is in the image. The researchers want to explore whether it is possible and worthwhile to use an advanced AI system to add captions to all these images.
There are many potential benefits to this idea. Captions could make images much more accessible to people who are visually impaired or have other disabilities. They could also help search engines better understand the content of images and provide more relevant results. Additionally, the captions could be used to train other AI systems, furthering progress in computer vision and multimodal understanding.
However, the researchers also acknowledge that this would be an enormous and complex undertaking, with significant technical and ethical challenges. Generating high-quality captions at such a massive scale is difficult, and there are concerns about the accuracy, biases, and potential misuse of the captions. The researchers carefully examine these issues and discuss ways to mitigate the risks.
Overall, the paper provides a thoughtful examination of the potential benefits and drawbacks of using a powerful language model like LLaMA-3 to automatically caption billions of web images. It raises important questions about the role of AI in reshaping the internet and the need to carefully consider the societal implications of such large-scale technological interventions.
Technical Explanation
The paper begins by discussing the vast number of images on the internet that currently lack detailed captions or descriptions. The researchers propose using the recently developed LLaMA-3 language model to automatically generate captions for these images at a massive scale.
The researchers outline several potential benefits of this approach, including improving accessibility for visually impaired users, enhancing search engine capabilities, and providing valuable training data for other AI systems working on zero-shot concept generation or caption diversity.
However, the researchers also acknowledge significant technical and ethical challenges. Generating high-quality captions for billions of diverse images is an enormous undertaking, and the researchers discuss issues related to caption accuracy, bias, and potential misuse of the generated captions.
To address these concerns, the researchers propose several strategies, such as leveraging multi-modal pretraining, implementing rigorous quality control measures, and engaging in ongoing monitoring and adjustment of the captioning system.
Overall, the paper provides a comprehensive exploration of the potential benefits, risks, and implementation details of using a large language model like LLaMA-3 to automatically caption billions of web images. It raises important questions about the societal impact of such large-scale technological interventions and the need for careful consideration of both the advantages and potential drawbacks.
Critical Analysis
The researchers in this paper have identified an ambitious and potentially impactful application of large language models in the context of web-scale image captioning. However, the challenges they outline are significant and warrant careful consideration.
One key concern is the accuracy and reliability of the automatically generated captions. While language models like LLaMA-3 have made impressive advancements, they are still prone to errors, biases, and limitations in their understanding of the world. Incorrectly captioned images could have serious consequences, particularly for users with disabilities or in high-stakes applications.
The researchers acknowledge this issue and propose quality control measures, but the scalability and effectiveness of such approaches remain to be seen. Extensive testing, robust error detection, and continuous monitoring would be essential to maintain a high standard of caption quality.
Another significant concern is the potential for misuse or unintended consequences of such a large-scale captioning system. Captions could be used to spread misinformation, invade privacy, or reinforce harmful stereotypes. The researchers mention the need for ethical guidelines and ongoing monitoring, but the complexity of implementing such safeguards at a web-scale level is daunting.
Additionally, the researchers do not delve deeply into the societal implications of their proposed system. While they touch on the benefits of improved accessibility and search capabilities, they could have explored the broader impact on the information ecosystem, the potential to exacerbate existing power imbalances, and the implications for individual privacy and autonomy.
Overall, the researchers have presented a thought-provoking exploration of the potential and challenges of using a powerful language model to caption billions of web images. However, the implementation details and societal impact warrant further careful consideration and research to ensure that such a system serves the greater good and mitigates the risks.
Conclusion
This paper presents a bold proposal to leverage the capabilities of the LLaMA-3 language model to automatically caption billions of web images. The researchers outline several potential benefits, including improved accessibility, enhanced search capabilities, and valuable training data for other AI systems.
However, the researchers also identify significant technical and ethical challenges, such as ensuring caption accuracy, mitigating biases and misuse, and grappling with the societal implications of such a large-scale intervention. Careful consideration of these issues is essential to realize the full potential of this approach while minimizing the risks.
Overall, this paper provides a thought-provoking exploration of the possibilities and pitfalls of using advanced language models to transform the visual landscape of the internet. It raises important questions about the role of AI in shaping the information ecosystem and the need for a comprehensive, interdisciplinary approach to developing and deploying such powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
An Empirical Study and Analysis of Text-to-Image Generation Using Large Language Model-Powered Textual Representation
Zhiyu Tan, Mengping Yang, Luozheng Qin, Hao Yang, Ye Qian, Qiang Zhou, Cheng Zhang, Hao Li
0
0
One critical prerequisite for faithful text-to-image generation is the accurate understanding of text inputs. Existing methods leverage the text encoder of the CLIP model to represent input prompts. However, the pre-trained CLIP model can merely encode English with a maximum token length of 77. Moreover, the model capacity of the text encoder from CLIP is relatively limited compared to Large Language Models (LLMs), which offer multilingual input, accommodate longer context, and achieve superior text representation. In this paper, we investigate LLMs as the text encoder to improve the language understanding in text-to-image generation. Unfortunately, training text-to-image generative model with LLMs from scratch demands significant computational resources and data. To this end, we introduce a three-stage training pipeline that effectively and efficiently integrates the existing text-to-image model with LLMs. Specifically, we propose a lightweight adapter that enables fast training of the text-to-image model using the textual representations from LLMs. Extensive experiments demonstrate that our model supports not only multilingual but also longer input context with superior image generation quality.
5/22/2024
Data Alignment for Zero-Shot Concept Generation in Dermatology AI
Soham Gadgil, Mahtab Bigverdi
0
0
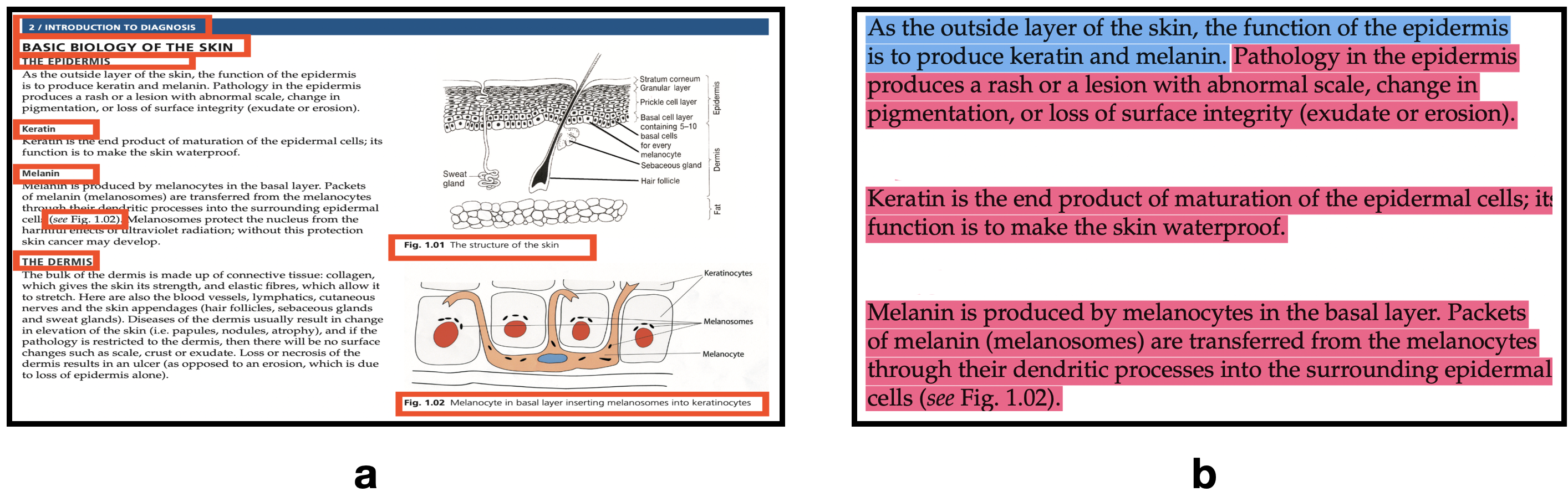
AI in dermatology is evolving at a rapid pace but the major limitation to training trustworthy classifiers is the scarcity of data with ground-truth concept level labels, which are meta-labels semantically meaningful to humans. Foundation models like CLIP providing zero-shot capabilities can help alleviate this challenge by leveraging vast amounts of image-caption pairs available on the internet. CLIP can be fine-tuned using domain specific image-caption pairs to improve classification performance. However, CLIP's pre-training data is not well-aligned with the medical jargon that clinicians use to perform diagnoses. The development of large language models (LLMs) in recent years has led to the possibility of leveraging the expressive nature of these models to generate rich text. Our goal is to use these models to generate caption text that aligns well with both the clinical lexicon and with the natural human language used in CLIP's pre-training data. Starting with captions used for images in PubMed articles, we extend them by passing the raw captions through an LLM fine-tuned on the field's several textbooks. We find that using captions generated by an expressive fine-tuned LLM like GPT-3.5 improves downstream zero-shot concept classification performance.
4/22/2024
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
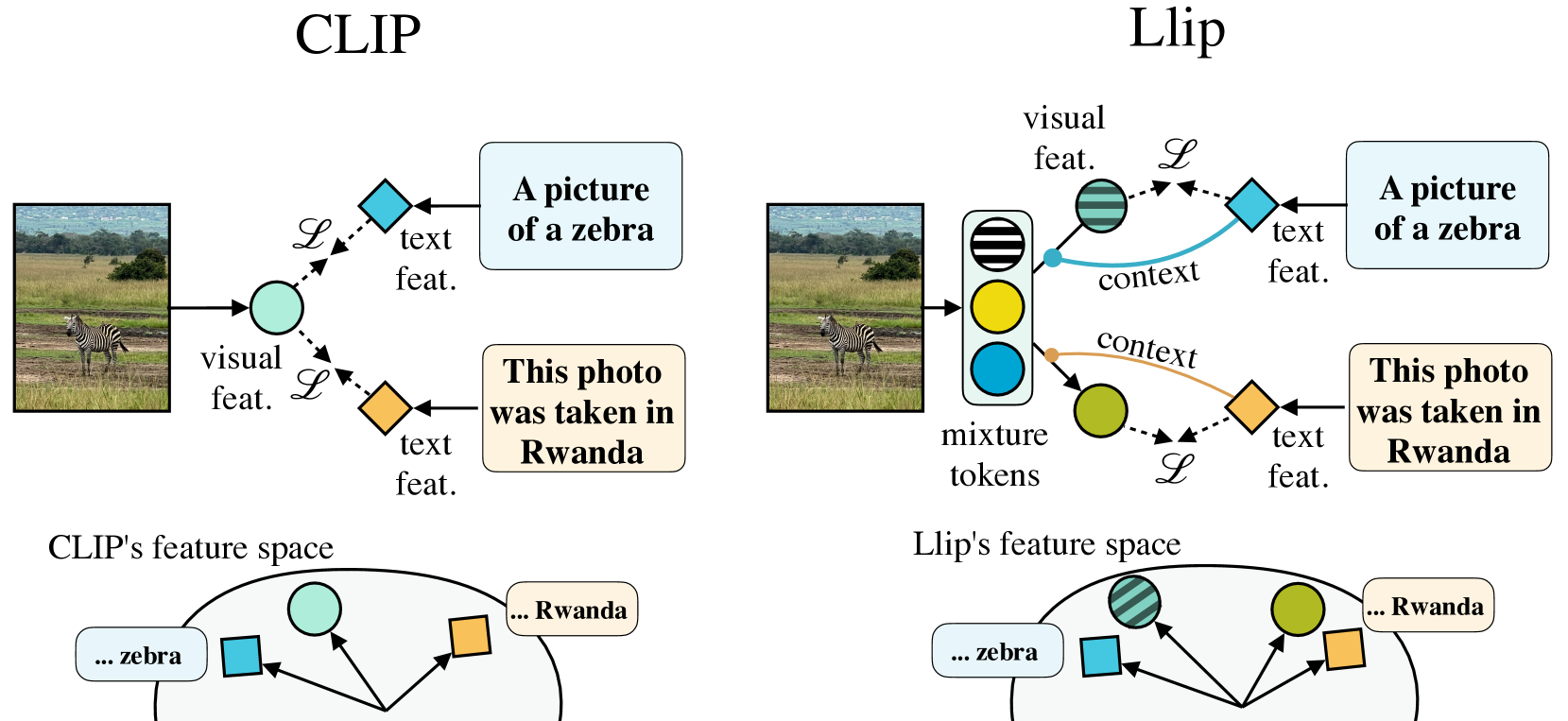
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024
Vision Model Pre-training on Interleaved Image-Text Data via Latent Compression Learning
Chenyu Yang, Xizhou Zhu, Jinguo Zhu, Weijie Su, Junjie Wang, Xuan Dong, Wenhai Wang, Lewei Lu, Bin Li, Jie Zhou, Yu Qiao, Jifeng Dai
0
0
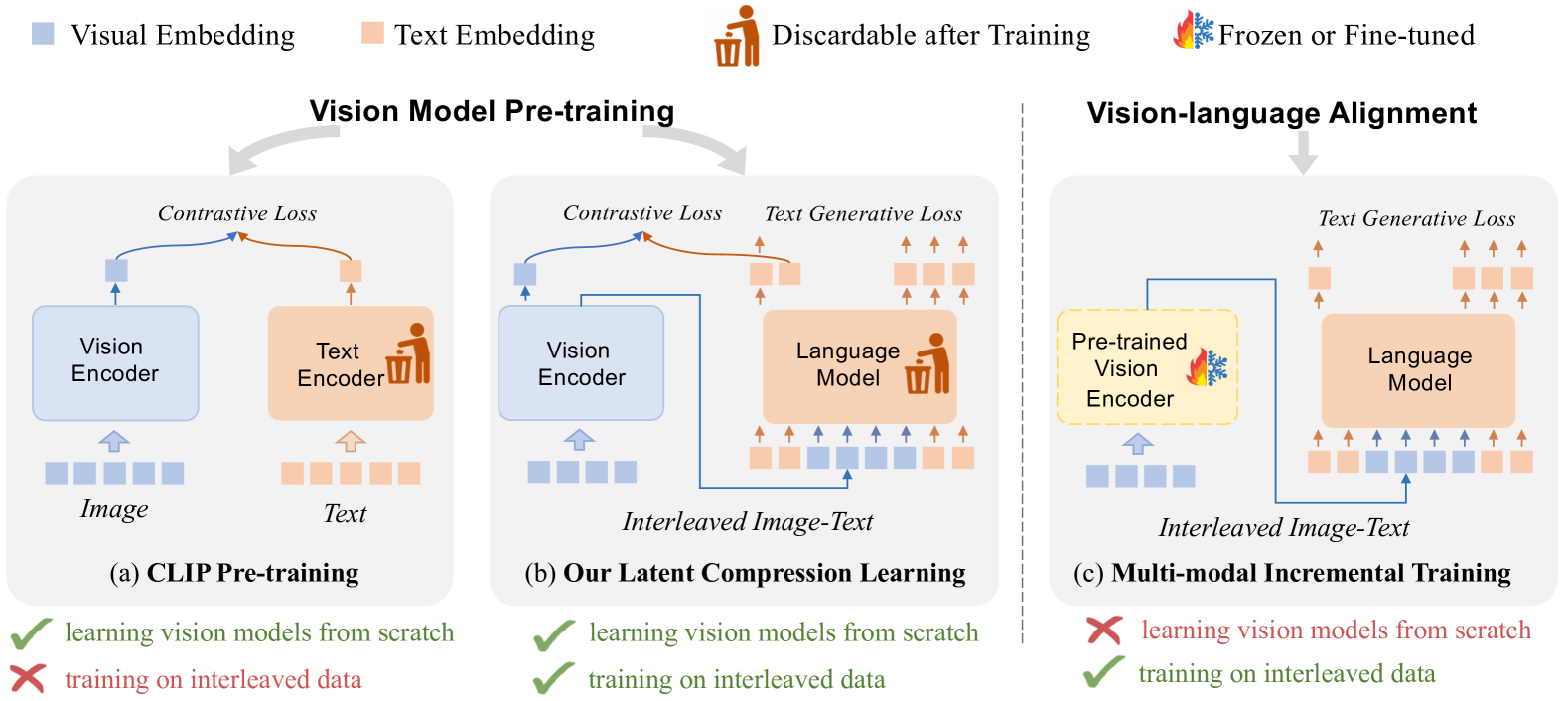
Recently, vision model pre-training has evolved from relying on manually annotated datasets to leveraging large-scale, web-crawled image-text data. Despite these advances, there is no pre-training method that effectively exploits the interleaved image-text data, which is very prevalent on the Internet. Inspired by the recent success of compression learning in natural language processing, we propose a novel vision model pre-training method called Latent Compression Learning (LCL) for interleaved image-text data. This method performs latent compression learning by maximizing the mutual information between the inputs and outputs of a causal attention model. The training objective can be decomposed into two basic tasks: 1) contrastive learning between visual representation and preceding context, and 2) generating subsequent text based on visual representation. Our experiments demonstrate that our method not only matches the performance of CLIP on paired pre-training datasets (e.g., LAION), but can also leverage interleaved pre-training data (e.g., MMC4) to learn robust visual representation from scratch, showcasing the potential of vision model pre-training with interleaved image-text data. Code is released at https://github.com/OpenGVLab/LCL.
6/12/2024