Data Alignment for Zero-Shot Concept Generation in Dermatology AI
2404.13043
0
0
Abstract
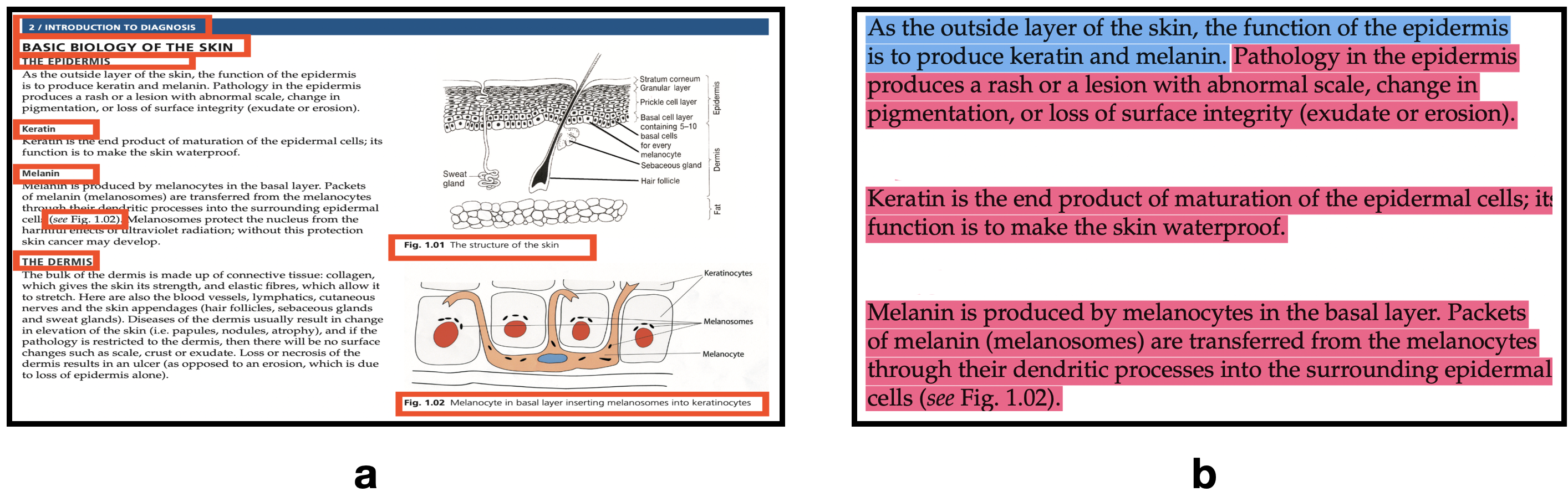
AI in dermatology is evolving at a rapid pace but the major limitation to training trustworthy classifiers is the scarcity of data with ground-truth concept level labels, which are meta-labels semantically meaningful to humans. Foundation models like CLIP providing zero-shot capabilities can help alleviate this challenge by leveraging vast amounts of image-caption pairs available on the internet. CLIP can be fine-tuned using domain specific image-caption pairs to improve classification performance. However, CLIP's pre-training data is not well-aligned with the medical jargon that clinicians use to perform diagnoses. The development of large language models (LLMs) in recent years has led to the possibility of leveraging the expressive nature of these models to generate rich text. Our goal is to use these models to generate caption text that aligns well with both the clinical lexicon and with the natural human language used in CLIP's pre-training data. Starting with captions used for images in PubMed articles, we extend them by passing the raw captions through an LLM fine-tuned on the field's several textbooks. We find that using captions generated by an expressive fine-tuned LLM like GPT-3.5 improves downstream zero-shot concept classification performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a technique called "data alignment" to enable zero-shot concept generation in dermatology AI systems.
- Zero-shot learning allows AI models to recognize and generate concepts they were not explicitly trained on, which is valuable for medical domains with diverse and evolving terminology.
- The researchers introduce a novel dataset curation approach that aligns textbook knowledge with clinical image data to facilitate zero-shot transfer.
Plain English Explanation
The researchers in this paper are working on making AI systems that can understand and generate information about skin conditions, even if they haven't been specifically trained on those topics before. This is called "zero-shot learning," and it's useful for medical AI because the language and concepts around health issues are always changing.
To make this work, the researchers developed a new way to gather and structure the data the AI system learns from. They took information from medical textbooks and matched it up with clinical images of skin conditions. This "data alignment" allows the AI to connect the textbook knowledge about skin diseases with actual visual examples.
By linking the textbook information and real-world images, the researchers can train the AI to recognize and describe skin conditions it hasn't seen before. This zero-shot capability is important because it means the AI can adapt to new medical terms and concepts over time, without requiring extensive retraining.
Overall, this research aims to create more flexible and adaptable AI systems for dermatology, which could help doctors and patients by improving diagnosis and treatment of skin diseases.
Technical Explanation
The key innovation in this paper is a novel data curation approach that aligns textbook knowledge with clinical image data to facilitate zero-shot concept generation in dermatology AI.
The researchers curated a dataset by extracting text and images from dermatology textbooks and matching them to a large corpus of clinical skin images. This "data alignment" allowed them to train an AI model to learn the associations between textual concepts and visual representations of skin conditions.
By leveraging this aligned dataset, the model can then be used for zero-shot concept generation, where it can recognize and describe skin conditions it was not explicitly trained on. This is valuable for medical domains like dermatology, where the terminology and concepts are constantly evolving.
The paper evaluates this approach through a series of experiments, demonstrating the model's ability to accurately generate relevant text descriptions for unseen skin conditions. The results show significant improvements over existing zero-shot approaches, highlighting the efficacy of the data alignment technique.
Critical Analysis
The researchers acknowledge several limitations in their work. First, the dataset curation process is labor-intensive and may not scale easily to larger domains. Additionally, the textbook knowledge may not fully capture the nuances and complexities of real-world clinical practice.
Another potential issue is the reliance on English-language textbooks, which could introduce biases and limit the model's performance on diverse patient populations. Further research is needed to extend this approach to multilingual and multicultural medical knowledge.
Finally, while the zero-shot capabilities are promising, the paper does not address the model's performance on rare or highly specialized skin conditions, which may require more targeted training data and techniques.
Overall, this research represents an important step towards more flexible and adaptable AI systems for dermatology. However, continued efforts are needed to address the challenges and limitations identified in the paper.
Conclusion
This paper presents a novel data alignment technique that enables zero-shot concept generation in dermatology AI systems. By linking textbook knowledge with clinical image data, the researchers have developed a model that can recognize and describe skin conditions it has not been explicitly trained on.
This zero-shot capability is valuable for medical domains, where the terminology and concepts are constantly evolving. The results demonstrate significant improvements over existing approaches, highlighting the potential of this data-driven technique to create more adaptable and versatile AI systems for dermatology.
While the research has limitations, it represents an important contribution to the field of medical AI. Continued efforts to address the identified challenges and expand the approach to broader medical domains could lead to transformative advancements in healthcare, benefiting both clinicians and patients.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Retrieval Enhanced Zero-Shot Video Captioning
Yunchuan Ma, Laiyun Qing, Guorong Li, Yuankai Qi, Quan Z. Sheng, Qingming Huang
0
0
Despite the significant progress of fully-supervised video captioning, zero-shot methods remain much less explored. In this paper, we propose to take advantage of existing pre-trained large-scale vision and language models to directly generate captions with test time adaptation. Specifically, we bridge video and text using three key models: a general video understanding model XCLIP, a general image understanding model CLIP, and a text generation model GPT-2, due to their source-code availability. The main challenge is how to enable the text generation model to be sufficiently aware of the content in a given video so as to generate corresponding captions. To address this problem, we propose using learnable tokens as a communication medium between frozen GPT-2 and frozen XCLIP as well as frozen CLIP. Differing from the conventional way to train these tokens with training data, we update these tokens with pseudo-targets of the inference data under several carefully crafted loss functions which enable the tokens to absorb video information catered for GPT-2. This procedure can be done in just a few iterations (we use 16 iterations in the experiments) and does not require ground truth data. Extensive experimental results on three widely used datasets, MSR-VTT, MSVD, and VATEX, show 4% to 20% improvements in terms of the main metric CIDEr compared to the existing state-of-the-art methods.
5/14/2024
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
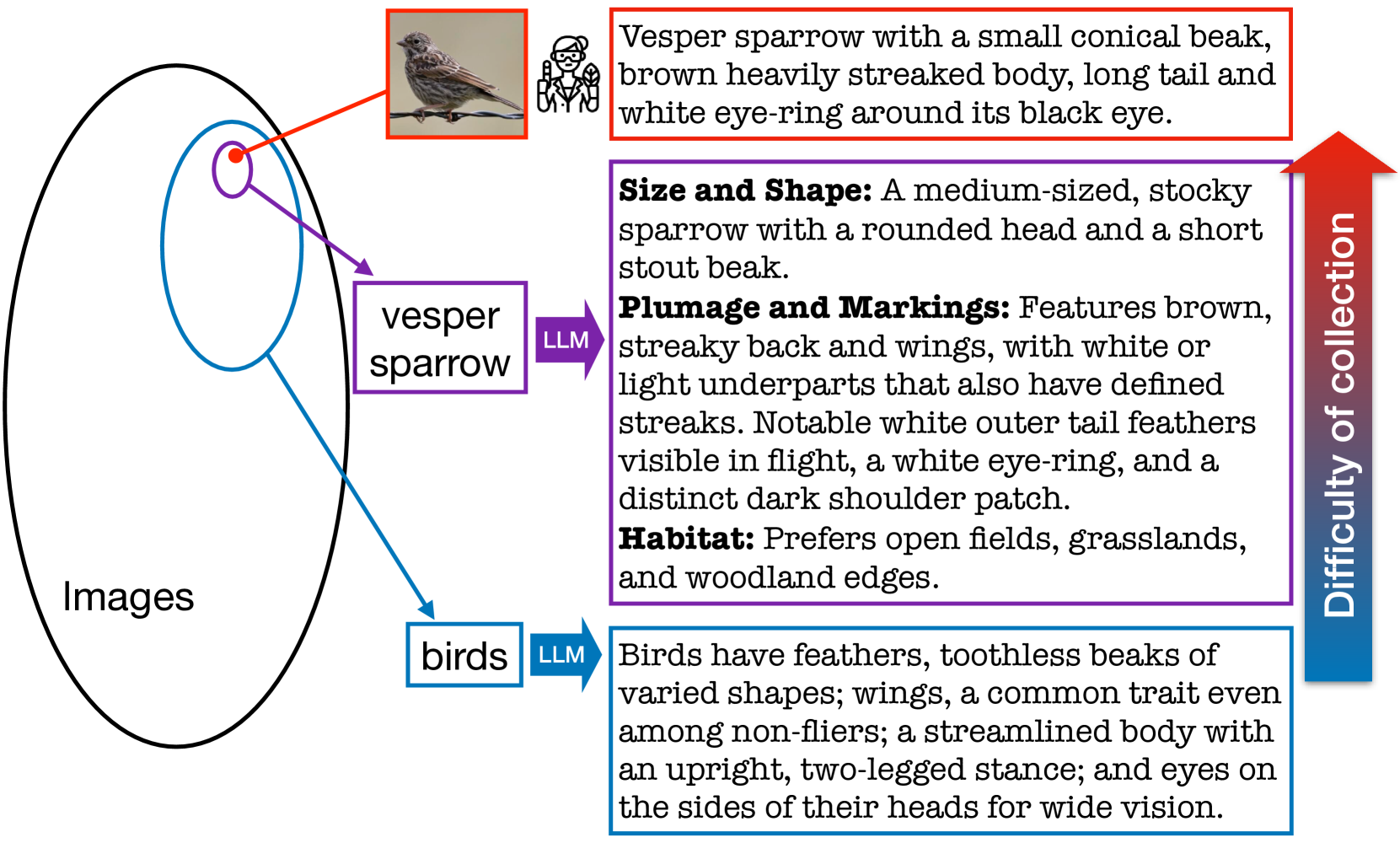
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024
Zero-Shot Medical Phrase Grounding with Off-the-shelf Diffusion Models
Konstantinos Vilouras, Pedro Sanchez, Alison Q. O'Neil, Sotirios A. Tsaftaris
0
0
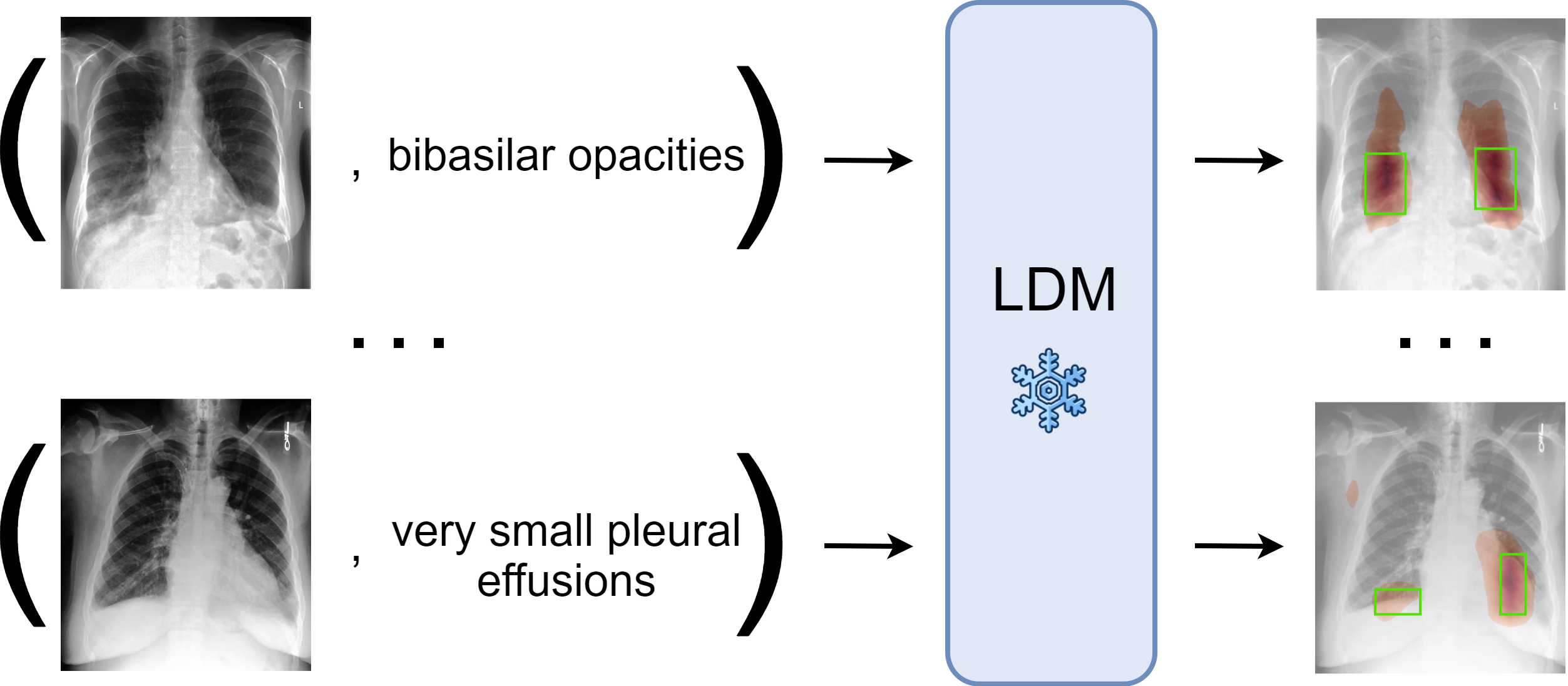
Localizing the exact pathological regions in a given medical scan is an important imaging problem that requires a large amount of bounding box ground truth annotations to be accurately solved. However, there exist alternative, potentially weaker, forms of supervision, such as accompanying free-text reports, which are readily available. The task of performing localization with textual guidance is commonly referred to as phrase grounding. In this work, we use a publicly available Foundation Model, namely the Latent Diffusion Model, to solve this challenging task. This choice is supported by the fact that the Latent Diffusion Model, despite being generative in nature, contains mechanisms (cross-attention) that implicitly align visual and textual features, thus leading to intermediate representations that are suitable for the task at hand. In addition, we aim to perform this task in a zero-shot manner, i.e., without any further training on target data, meaning that the model's weights remain frozen. To this end, we devise strategies to select features and also refine them via post-processing without extra learnable parameters. We compare our proposed method with state-of-the-art approaches which explicitly enforce image-text alignment in a joint embedding space via contrastive learning. Results on a popular chest X-ray benchmark indicate that our method is competitive wih SOTA on different types of pathology, and even outperforms them on average in terms of two metrics (mean IoU and AUC-ROC). Source code will be released upon acceptance.
4/22/2024
📊
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
0
0
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
4/9/2024