When Good and Reproducible Results are a Giant with Feet of Clay: The Importance of Software Quality in NLP

0
🤿
Sign in to get full access
Overview
- The paper highlights the importance of ensuring code correctness in research experiments, beyond just focusing on the quality of results.
- It presents a case study where the authors identify and fix bugs in widely used implementations of the Conformer architecture.
- Through experiments on speech recognition and translation tasks, the authors demonstrate that the presence of bugs does not prevent the achievement of good and reproducible results, but can lead to incorrect conclusions that may mislead future research.
- To address this issue, the authors propose a Code-quality Checklist and release pangoliNN, a library for testing neural models.
Plain English Explanation
When researchers conduct experiments, they often assume that the code they use is correct based on the quality of the results. However, this assumption can be risky, as the code may contain hidden bugs that could lead to erroneous outcomes and potentially misleading findings.
In this study, the authors identify and fix three bugs in widely used implementations of the Conformer architecture, a state-of-the-art model for speech recognition and translation tasks. They demonstrate that even with the presence of these bugs, the models can still produce good and reproducible results. This suggests that the quality of the results alone is not a reliable indicator of the correctness of the underlying code.
The authors argue that the current focus on reproducibility in research should also include an emphasis on software quality. To address this issue, they propose a Code-quality Checklist and release pangoliNN, a library dedicated to testing neural models. These tools aim to promote coding best practices and improve the overall quality of research software within the natural language processing (NLP) community.
Technical Explanation
The paper presents a case study where the authors identify and fix three bugs in widely used implementations of the Conformer architecture, a state-of-the-art model for speech recognition and translation tasks. They conduct experiments on several speech recognition and translation datasets in various languages to evaluate the impact of these bugs on the model's performance.
The authors demonstrate that the presence of bugs does not prevent the achievement of good and reproducible results, which could lead to incorrect conclusions that potentially misguide future research. For example, they show that a buggy implementation of Conformer can still outperform a correct implementation on certain tasks, despite the underlying issues in the code.
To address this problem, the authors propose a Code-quality Checklist and release pangoliNN, a library dedicated to testing neural models. The checklist provides a set of guidelines to help researchers ensure the quality of their code, while the pangoliNN library offers tools for automatically testing neural models and identifying potential issues.
Critical Analysis
The paper raises an important issue in the field of machine learning research, where the focus on reproducibility often overshadows the need for code correctness. The authors provide a compelling case study that highlights the risks of relying solely on the quality of results to infer the correctness of the underlying code.
One potential limitation of the study is the scope of the bugs identified, as it is unclear whether the same patterns would hold for more complex or subtle bugs. Additionally, the effectiveness of the proposed Code-quality Checklist and pangoliNN library in improving research software quality remains to be extensively evaluated.
The paper could also benefit from a more in-depth discussion of the potential reasons why good and reproducible results can be achieved despite the presence of bugs, as this could provide valuable insights into the robustness of modern machine learning models and the limitations of current evaluation practices.
Conclusion
This paper highlights the importance of ensuring code correctness in research experiments, beyond just focusing on the quality of results. The authors present a case study where they identify and fix bugs in widely used implementations of the Conformer architecture, demonstrating that the presence of bugs does not prevent the achievement of good and reproducible results, but can lead to incorrect conclusions that may mislead future research.
To address this issue, the authors propose a Code-quality Checklist and release pangoliNN, a library dedicated to testing neural models. These tools aim to promote coding best practices and improve the overall quality of research software within the NLP community, with the ultimate goal of enhancing the reliability and trustworthiness of machine learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
When Good and Reproducible Results are a Giant with Feet of Clay: The Importance of Software Quality in NLP
Sara Papi, Marco Gaido, Andrea Pilzer, Matteo Negri
Despite its crucial role in research experiments, code correctness is often presumed only on the basis of the perceived quality of results. This assumption comes with the risk of erroneous outcomes and potentially misleading findings. To address this issue, we posit that the current focus on reproducibility should go hand in hand with the emphasis on software quality. We present a case study in which we identify and fix three bugs in widely used implementations of the state-of-the-art Conformer architecture. Through experiments on speech recognition and translation in various languages, we demonstrate that the presence of bugs does not prevent the achievement of good and reproducible results, which however can lead to incorrect conclusions that potentially misguide future research. As a countermeasure, we propose a Code-quality Checklist and release pangoliNN, a library dedicated to testing neural models, with the goal of promoting coding best practices and improving research software quality within the NLP community.
Read more7/8/2024
0
Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical Study
Mehil B. Shah, Mohammad Masudur Rahman, Foutse Khomh
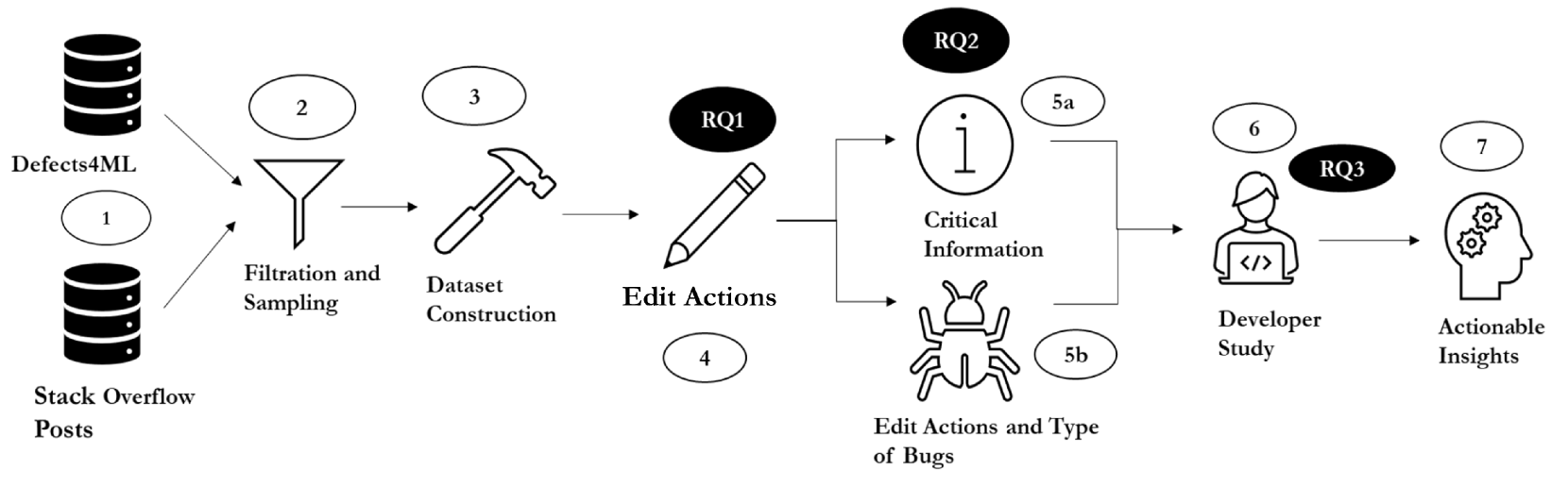
Context: Deep learning has achieved remarkable progress in various domains. However, like any software system, deep learning systems contain bugs, some of which can have severe impacts, as evidenced by crashes involving autonomous vehicles. Despite substantial advancements in deep learning techniques, little research has focused on reproducing deep learning bugs, which is an essential step for their resolution. Existing literature suggests that only 3% of deep learning bugs are reproducible, underscoring the need for further research. Objective: This paper examines the reproducibility of deep learning bugs. We identify edit actions and useful information that could improve the reproducibility of deep learning bugs. Method: First, we construct a dataset of 668 deep-learning bugs from Stack Overflow and GitHub across three frameworks and 22 architectures. Second, out of the 668 bugs, we select 165 bugs using stratified sampling and attempt to determine their reproducibility. While reproducing these bugs, we identify edit actions and useful information for their reproduction. Third, we used the Apriori algorithm to identify useful information and edit actions required to reproduce specific types of bugs. Finally, we conducted a user study involving 22 developers to assess the effectiveness of our findings in real-life settings. Results: We successfully reproduced 148 out of 165 bugs attempted. We identified ten edit actions and five useful types of component information that can help us reproduce the deep learning bugs. With the help of our findings, the developers were able to reproduce 22.92% more bugs and reduce their reproduction time by 24.35%. Conclusions: Our research addresses the critical issue of deep learning bug reproducibility. Practitioners and researchers can leverage our findings to improve deep learning bug reproducibility.
Read more8/26/2024

0
Predicting Software Reliability in Softwarized Networks
Hasan Yagiz Ozkan, Madeleine Kaufmann, Wolfgang Kellerer, Carmen Mas-Machuca
Providing high quality software and evaluating the software reliability in softwarized networks are crucial for vendors and customers. These networks rely on open source code, which are sensitive to contain high number of bugs. Both, the knowledge about the code of previous releases as well as the bug history of the particular project can be used to evaluate the software reliability of a new software release based on SRGM. In this work a framework to predict the number of the bugs of a new release, as well as other reliability parameters, is proposed. An exemplary implementation of this framework to two particular open source projects, is described in detail. The difference between the prediction accuracy of the two projects is presented. Different alternatives to increase the prediction accuracy are proposed and compared in this paper.
Read more8/1/2024

0
Can citations tell us about a paper's reproducibility? A case study of machine learning papers
Rochana R. Obadage, Sarah M. Rajtmajer, Jian Wu
The iterative character of work in machine learning (ML) and artificial intelligence (AI) and reliance on comparisons against benchmark datasets emphasize the importance of reproducibility in that literature. Yet, resource constraints and inadequate documentation can make running replications particularly challenging. Our work explores the potential of using downstream citation contexts as a signal of reproducibility. We introduce a sentiment analysis framework applied to citation contexts from papers involved in Machine Learning Reproducibility Challenges in order to interpret the positive or negative outcomes of reproduction attempts. Our contributions include training classifiers for reproducibility-related contexts and sentiment analysis, and exploring correlations between citation context sentiment and reproducibility scores. Study data, software, and an artifact appendix are publicly available at https://github.com/lamps-lab/ccair-ai-reproducibility .
Read more5/8/2024