Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical Study

0
Sign in to get full access
Overview
- This paper examines the reproducibility of deep learning bugs, which are errors or issues that arise in the development and deployment of deep learning models.
- The researchers conducted an empirical study to understand the factors that contribute to the reproducibility of deep learning bugs and identify ways to enhance it.
- The study aimed to provide insights that can help improve the reliability and trustworthiness of deep learning systems.
Plain English Explanation
Deep learning is a powerful technique used in many AI applications, but like any complex system, it can sometimes have bugs or errors that can be difficult to reproduce and fix. This paper explores the challenges around reproducing deep learning bugs, which is important for improving the reliability and trustworthiness of these systems.
The researchers looked at a variety of factors that can affect the reproducibility of deep learning bugs, such as the specific libraries and frameworks used, the hardware and software configurations, and the way the training data is preprocessed and fed into the model. They also considered how the complexity of deep learning models and the stochastic nature of the training process can make it harder to reproduce issues.
By studying real-world examples of deep learning bugs, the researchers were able to identify patterns and common pitfalls that can lead to reproducibility challenges. They then used this information to suggest ways to enhance the reproducibility of deep learning bugs, which could help developers more effectively diagnose and fix these issues.
Overall, this research is important for improving the reliability and trustworthiness of deep learning systems, which are increasingly being used in high-stakes applications like healthcare, finance, and autonomous vehicles. By making it easier to reproduce and fix deep learning bugs, the work can also help developers more efficiently optimize and improve their models.
Technical Explanation
The researchers conducted an empirical study to investigate the factors that affect the reproducibility of deep learning bugs. They collected a dataset of 200 GitHub issues related to deep learning bugs and analyzed them to identify patterns and common characteristics.
The study examined factors such as the specific deep learning libraries and frameworks used (e.g., TensorFlow, PyTorch), the hardware and software configurations, and the preprocessing and data feeding techniques employed. The researchers also considered how the inherent stochasticity and complexity of deep learning models can contribute to reproducibility challenges.
Through their analysis, the researchers were able to identify several key factors that influence the reproducibility of deep learning bugs, including:
- Inconsistencies in the software and hardware environment
- Sensitivity to hyperparameter settings and random initializations
- Challenges in replicating the exact data preprocessing and feeding pipeline
Based on these insights, the researchers proposed several strategies to enhance the reproducibility of deep learning bugs, such as:
- Providing detailed environment and configuration information
- Incorporating deterministic initialization and training procedures
- Implementing comprehensive testing and validation frameworks
The paper also discusses the implications of their findings for the broader deep learning research community and highlights areas for future work, such as developing automated tools to assist in reproducing and diagnosing deep learning bugs.
Critical Analysis
The researchers' approach of analyzing real-world deep learning bugs from GitHub issues is a valuable contribution to the field, as it provides empirical evidence of the challenges faced by practitioners in the wild. The identified factors that affect reproducibility, such as software and hardware environment, hyperparameter sensitivity, and data preprocessing, are well-aligned with the known challenges in the deep learning community.
However, the paper could have benefited from a more detailed discussion of the limitations and potential biases inherent in the GitHub issue dataset. It is possible that the issues reported on GitHub may not be representative of all deep learning bugs, as developers may be more likely to report certain types of issues or bugs that are easier to describe and reproduce. Additionally, the paper could have explored the role of documentation and communication practices in enhancing reproducibility, as clear and comprehensive reporting of experimental details is crucial for enabling others to replicate the work.
While the proposed strategies for improving reproducibility, such as providing detailed environment information and implementing deterministic training procedures, are well-justified, the paper could have delved deeper into the practical challenges and trade-offs involved in implementing these approaches. For example, the impact on model performance or the additional complexity introduced by deterministic training procedures could have been discussed.
Overall, the paper provides valuable insights into the reproducibility challenges faced in deep learning and lays the groundwork for further research and tooling development in this important area. Continued efforts to address the reproducibility crisis in machine learning can help build more reliable and trustworthy AI systems.
Conclusion
This paper presents an empirical study on the factors that affect the reproducibility of deep learning bugs. By analyzing a dataset of real-world GitHub issues, the researchers identified key contributors to reproducibility challenges, such as software and hardware environment inconsistencies, hyperparameter sensitivity, and data preprocessing difficulties.
The findings of this study can help deep learning practitioners and researchers better understand the challenges associated with reproducing and diagnosing issues in their models. The proposed strategies for enhancing reproducibility, such as providing detailed environment information and implementing deterministic training procedures, offer practical guidance for improving the reliability and trustworthiness of deep learning systems.
Overall, this work contributes to the ongoing efforts to address the reproducibility crisis in machine learning and highlights the importance of developing robust testing and validation frameworks to ensure the quality and reliability of deep learning-based applications. By enhancing the reproducibility of deep learning bugs, researchers and developers can more effectively diagnose and fix issues, leading to more reliable and impactful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Enhancing the Reproducibility of Deep Learning Bugs: An Empirical Study
Mehil B. Shah, Mohammad Masudur Rahman, Foutse Khomh
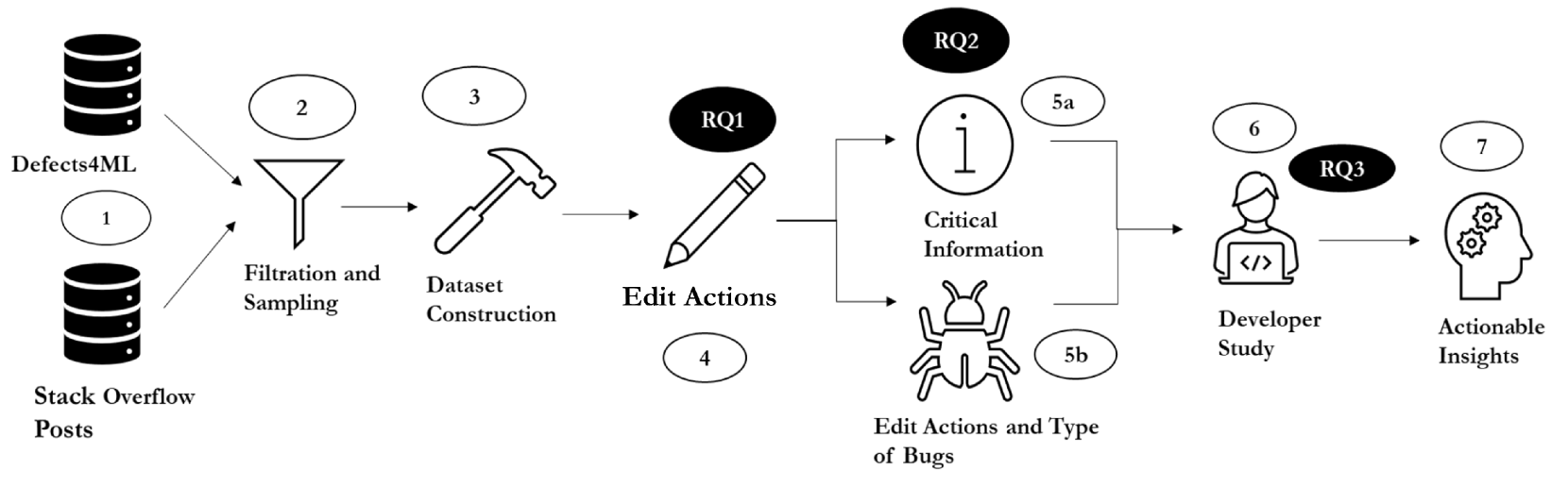
Context: Deep learning has achieved remarkable progress in various domains. However, like any software system, deep learning systems contain bugs, some of which can have severe impacts, as evidenced by crashes involving autonomous vehicles. Despite substantial advancements in deep learning techniques, little research has focused on reproducing deep learning bugs, which is an essential step for their resolution. Existing literature suggests that only 3% of deep learning bugs are reproducible, underscoring the need for further research. Objective: This paper examines the reproducibility of deep learning bugs. We identify edit actions and useful information that could improve the reproducibility of deep learning bugs. Method: First, we construct a dataset of 668 deep-learning bugs from Stack Overflow and GitHub across three frameworks and 22 architectures. Second, out of the 668 bugs, we select 165 bugs using stratified sampling and attempt to determine their reproducibility. While reproducing these bugs, we identify edit actions and useful information for their reproduction. Third, we used the Apriori algorithm to identify useful information and edit actions required to reproduce specific types of bugs. Finally, we conducted a user study involving 22 developers to assess the effectiveness of our findings in real-life settings. Results: We successfully reproduced 148 out of 165 bugs attempted. We identified ten edit actions and five useful types of component information that can help us reproduce the deep learning bugs. With the help of our findings, the developers were able to reproduce 22.92% more bugs and reduce their reproduction time by 24.35%. Conclusions: Our research addresses the critical issue of deep learning bug reproducibility. Practitioners and researchers can leverage our findings to improve deep learning bug reproducibility.
Read more8/26/2024
0
Evaluating the method reproducibility of deep learning models in the biodiversity domain
Waqas Ahmed, Vamsi Krishna Kommineni, Birgitta Konig-Ries, Jitendra Gaikwad, Luiz Gadelha, Sheeba Samuel
Artificial Intelligence (AI) is revolutionizing biodiversity research by enabling advanced data analysis, species identification, and habitats monitoring, thereby enhancing conservation efforts. Ensuring reproducibility in AI-driven biodiversity research is crucial for fostering transparency, verifying results, and promoting the credibility of ecological findings.This study investigates the reproducibility of deep learning (DL) methods within the biodiversity domain. We design a methodology for evaluating the reproducibility of biodiversity-related publications that employ DL techniques across three stages. We define ten variables essential for method reproducibility, divided into four categories: resource requirements, methodological information, uncontrolled randomness, and statistical considerations. These categories subsequently serve as the basis for defining different levels of reproducibility. We manually extract the availability of these variables from a curated dataset comprising 61 publications identified using the keywords provided by biodiversity experts. Our study shows that the dataset is shared in 47% of the publications; however, a significant number of the publications lack comprehensive information on deep learning methods, including details regarding randomness.
Read more7/11/2024
0
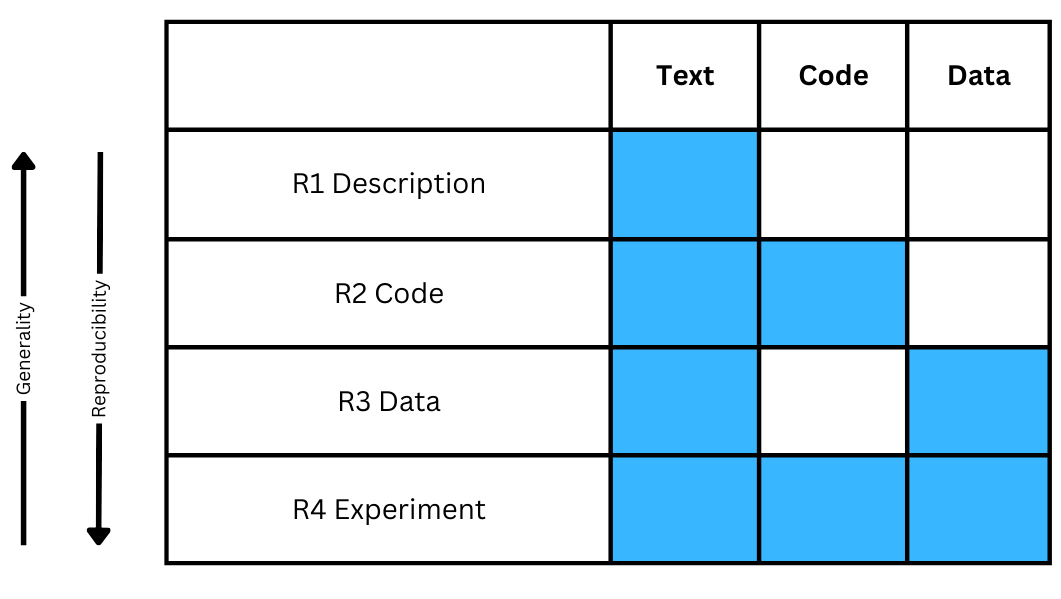
Reproducibility in Machine Learning-based Research: Overview, Barriers and Drivers
Harald Semmelrock, Tony Ross-Hellauer, Simone Kopeinik, Dieter Theiler, Armin Haberl, Stefan Thalmann, Dominik Kowald
Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises primarily due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the level of reproducibility in ML-driven research remains unsatisfactory. Therefore, in this article, we discuss the reproducibility of ML-driven research with three main aims: (i) identify the barriers to reproducibility when applying ML in research as well as categorize the barriers to different types of reproducibility (description, code, data, and experiment reproducibility), (ii) identify potential drivers such as tools, practices, and interventions that support ML reproducibility as well as distinguish between technology-driven drivers, procedural drivers, and drivers related to awareness and education, and (iii) map the drivers to the barriers. With this work, we hope to provide insights and contribute to the decision-making process regarding the adoption of different solutions to support ML reproducibility.
Read more6/21/2024
0
Revisiting Static Feature-Based Android Malware Detection
Md Tanvirul Alam, Dipkamal Bhusal, Nidhi Rastogi
The increasing reliance on machine learning (ML) in computer security, particularly for malware classification, has driven significant advancements. However, the replicability and reproducibility of these results are often overlooked, leading to challenges in verifying research findings. This paper highlights critical pitfalls that undermine the validity of ML research in Android malware detection, focusing on dataset and methodological issues. We comprehensively analyze Android malware detection using two datasets and assess offline and continual learning settings with six widely used ML models. Our study reveals that when properly tuned, simpler baseline methods can often outperform more complex models. To address reproducibility challenges, we propose solutions for improving datasets and methodological practices, enabling fairer model comparisons. Additionally, we open-source our code to facilitate malware analysis, making it extensible for new models and datasets. Our paper aims to support future research in Android malware detection and other security domains, enhancing the reliability and reproducibility of published results.
Read more9/12/2024