When Learning Meets Dynamics: Distributed User Connectivity Maximization in UAV-Based Communication Networks

0

Sign in to get full access
Overview
- Unmanned aerial vehicles (UAVs) are being used to improve communication network coverage and connectivity.
- This paper proposes a distributed user connectivity maximization approach for UAV-based communication networks.
- The approach combines multi-agent reinforcement learning with dynamic UAV positioning to optimize user connectivity.
- Experiments show the proposed approach can effectively maximize user connectivity in UAV-based networks.
Plain English Explanation
In this paper, the researchers explore how to use unmanned aerial vehicles (UAVs) to improve communication networks. UAVs can be positioned in the air to extend the coverage and connectivity of these networks, helping more users access reliable internet and communication services.
The key challenge is figuring out the best way to coordinate the movement and positioning of multiple UAVs to maximize the number of users that can connect to the network. The researchers tackle this by combining multi-agent reinforcement learning techniques with dynamic UAV positioning strategies.
The reinforcement learning approach allows the UAVs to learn the optimal movements and locations to serve the most users, adapting to changing conditions on the ground. By working together as a coordinated team, the UAVs can efficiently cover an area and ensure as many users as possible can access the communication network.
Through experiments, the researchers demonstrate that their approach is effective at maximizing user connectivity in UAV-based communication networks. This has important implications for improving internet access and communication capabilities, especially in remote or underserved areas.
Technical Explanation
The paper proposes a distributed user connectivity maximization approach for UAV-based communication networks. It combines multi-agent reinforcement learning with dynamic UAV positioning to optimize the coverage and connectivity of the network.
The key components of the approach are:
-
Dynamic UAV Set: The UAVs are modeled as a dynamic set that can change position over time to adapt to user locations and needs.
-
Multi-Agent Reinforcement Learning: The researchers use a multi-agent reinforcement learning framework to enable the UAVs to learn the optimal movements and positioning to serve the most users. Each UAV acts as an independent agent that learns from its own experiences.
-
Reward Function: The agents are trained using a reward function that incentivizes maximizing the number of users connected to the communication network. This drives the UAVs to coordinate and position themselves to provide the best overall coverage.
Through simulations and experiments, the paper demonstrates that this approach can effectively maximize user connectivity in UAV-based communication networks. The distributed, adaptive nature of the solution allows it to adapt to dynamic user distributions and network conditions.
Critical Analysis
The paper presents a promising approach for improving communication network coverage and connectivity using UAVs. The combination of multi-agent reinforcement learning and dynamic UAV positioning seems well-suited to handle the complexity of coordinating multiple aerial vehicles.
However, the paper does not extensively discuss potential limitations or challenges. For example, it does not address how the approach would scale to very large numbers of UAVs or users, or how it would handle unpredictable events like UAV failures or unexpected user mobility.
Additionally, the paper focuses solely on maximizing the number of connected users, without considering other important metrics like quality of service, energy efficiency, or cost. Real-world deployments would likely need to balance multiple objectives, which could add further complexity to the optimization problem.
Further research could explore these areas and investigate how the proposed techniques could be extended or combined with other approaches to create more robust and versatile UAV-based communication systems.
Conclusion
This paper presents a novel distributed approach for maximizing user connectivity in UAV-based communication networks. By integrating multi-agent reinforcement learning with dynamic UAV positioning, the solution can adaptively coordinate a team of aerial vehicles to provide the best overall coverage and access to users.
The experimental results demonstrate the effectiveness of this approach, suggesting it could be a valuable tool for improving internet access and communication capabilities, especially in challenging or underserved areas. As UAV technology continues to advance, techniques like those explored in this paper will become increasingly important for leveraging these aerial platforms to enhance digital infrastructure and connectivity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
When Learning Meets Dynamics: Distributed User Connectivity Maximization in UAV-Based Communication Networks
Bowei Li (Linda), Saugat Tripathi (Linda), Salman Hosain (Linda), Ran Zhang (Linda), Jiang (Linda), Xie, Miao Wang
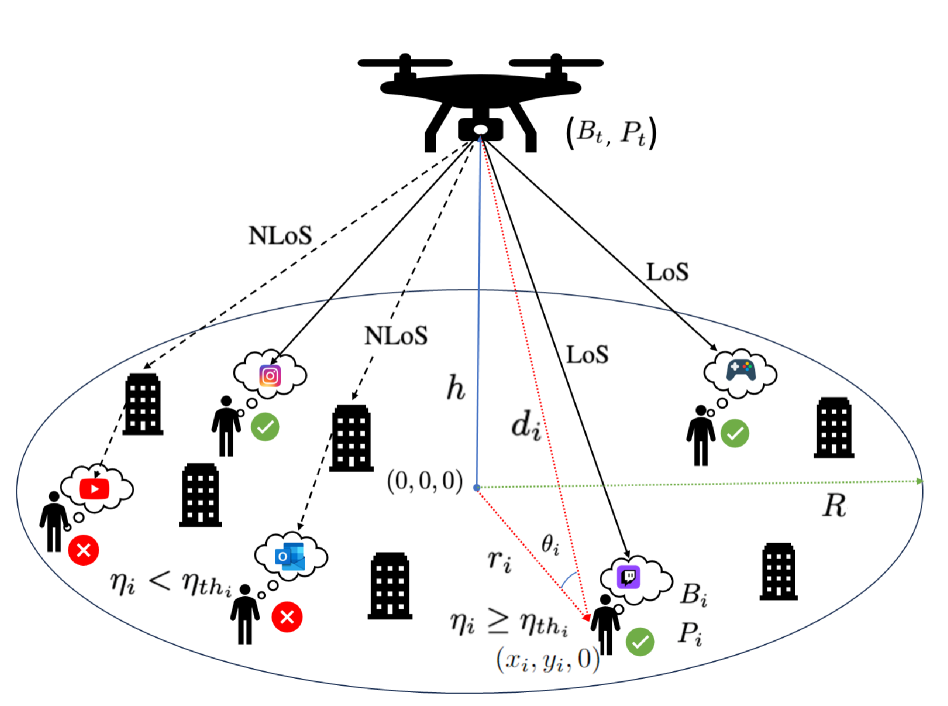
Distributed management over Unmanned Aerial Vehicle (UAV) based communication networks (UCNs) has attracted increasing research attention. In this work, we study a distributed user connectivity maximization problem in a UCN. The work features a horizontal study over different levels of information exchange during the distributed iteration and a consideration of dynamics in UAV set and user distribution, which are not well addressed in the existing works. Specifically, the studied problem is first formulated into a time-coupled mixed-integer non-convex optimization problem. A heuristic two-stage UAV-user association policy is proposed to faster determine the user connectivity. To tackle the NP-hard problem in scalable manner, the distributed user connectivity maximization algorithm 1 (DUCM-1) is proposed under the multi-agent deep Q learning (MA-DQL) framework. DUCM-1 emphasizes on designing different information exchange levels and evaluating how they impact the learning convergence with stationary and dynamic user distribution. To comply with the UAV dynamics, DUCM-2 algorithm is developed which is devoted to autonomously handling arbitrary quit's and join-in's of UAVs in a considered time horizon. Extensive simulations are conducted i) to conclude that exchanging state information with a deliberated task-specific reward function design yields the best convergence performance, and ii) to show the efficacy and robustness of DUCM-2 against the dynamics.
Read more9/11/2024
0
A Novel Joint DRL-Based Utility Optimization for UAV Data Services
Xuli Cai, Poonam Lohan, Burak Kantarci
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
Read more6/18/2024

0
Multi-objective Aerial Collaborative Secure Communication Optimization via Generative Diffusion Model-enabled Deep Reinforcement Learning
Chuang Zhang, Geng Sun, Jiahui Li, Qingqing Wu, Jiacheng Wang, Dusit Niyato, Yuanwei Liu
Due to flexibility and low-cost, unmanned aerial vehicles (UAVs) are increasingly crucial for enhancing coverage and functionality of wireless networks. However, incorporating UAVs into next-generation wireless communication systems poses significant challenges, particularly in sustaining high-rate and long-range secure communications against eavesdropping attacks. In this work, we consider a UAV swarm-enabled secure surveillance network system, where a UAV swarm forms a virtual antenna array to transmit sensitive surveillance data to a remote base station (RBS) via collaborative beamforming (CB) so as to resist mobile eavesdroppers. Specifically, we formulate an aerial secure communication and energy efficiency multi-objective optimization problem (ASCEE-MOP) to maximize the secrecy rate of the system and to minimize the flight energy consumption of the UAV swarm. To address the non-convex, NP-hard and dynamic ASCEE-MOP, we propose a generative diffusion model-enabled twin delayed deep deterministic policy gradient (GDMTD3) method. Specifically, GDMTD3 leverages an innovative application of diffusion models to determine optimal excitation current weights and position decisions of UAVs. The diffusion models can better capture the complex dynamics and the trade-off of the ASCEE-MOP, thereby yielding promising solutions. Simulation results highlight the superior performance of the proposed approach compared with traditional deployment strategies and some other deep reinforcement learning (DRL) benchmarks. Moreover, performance analysis under various parameter settings of GDMTD3 and different numbers of UAVs verifies the robustness of the proposed approach.
Read more7/15/2024
0
On Designing Multi-UAV aided Wireless Powered Dynamic Communication via Hierarchical Deep Reinforcement Learning
Ze Yu Zhao, Yue Ling Che, Sheng Luo, Gege Luo, Kaishun Wu, Victor C. M. Leung
This paper proposes a novel design on the wireless powered communication network (WPCN) in dynamic environments under the assistance of multiple unmanned aerial vehicles (UAVs). Unlike the existing studies, where the low-power wireless nodes (WNs) often conform to the coherent harvest-then-transmit protocol, under our newly proposed double-threshold based WN type updating rule, each WN can dynamically and repeatedly update its WN type as an E-node for non-linear energy harvesting over time slots or an I-node for transmitting data over sub-slots. To maximize the total transmission data size of all the WNs over T slots, each of the UAVs individually determines its trajectory and binary wireless energy transmission (WET) decisions over times slots and its binary wireless data collection (WDC) decisions over sub-slots, under the constraints of each UAV's limited on-board energy and each WN's node type updating rule. However, due to the UAVs' tightly-coupled trajectories with their WET and WDC decisions, as well as each WN's time-varying battery energy, this problem is difficult to solve optimally. We then propose a new multi-agent based hierarchical deep reinforcement learning (MAHDRL) framework with two tiers to solve the problem efficiently, where the soft actor critic (SAC) policy is designed in tier-1 to determine each UAV's continuous trajectory and binary WET decision over time slots, and the deep-Q learning (DQN) policy is designed in tier-2 to determine each UAV's binary WDC decisions over sub-slots under the given UAV trajectory from tier-1. Both of the SAC policy and the DQN policy are executed distributively at each UAV. Finally, extensive simulation results are provided to validate the outweighed performance of the proposed MAHDRL approach over various state-of-the-art benchmarks.
Read more6/10/2024