When MOE Meets LLMs: Parameter Efficient Fine-tuning for Multi-task Medical Applications
2310.18339
0
0
🤯
Abstract
The recent surge in Large Language Models (LLMs) has garnered significant attention across numerous fields. Fine-tuning is often required to fit general LLMs for a specific domain, like the web-based healthcare system. However, two problems arise during fine-tuning LLMs for medical applications. One is the task variety problem, which involves distinct tasks in real-world medical scenarios. The variety often leads to sub-optimal fine-tuning for data imbalance and seesaw problems. Besides, the large amount of parameters in LLMs leads to huge time and computation consumption by fine-tuning. To address these two problems, we propose a novel parameter efficient fine-tuning framework for multi-task medical applications, dubbed as MOELoRA. The designed framework aims to absorb both the benefits of mixture-of-expert (MOE) for multi-task learning and low-rank adaptation (LoRA) for parameter efficient fine-tuning. For unifying MOE and LoRA, we devise multiple experts as the trainable parameters, where each expert consists of a pair of low-rank matrices to retain the small size of trainable parameters. Then, a task-motivated gate function for all MOELoRA layers is proposed, which can control the contributions of each expert and produce distinct parameters for various tasks. We conduct experiments on a multi-task medical dataset, indicating MOELoRA outperforms the existing parameter efficient fine-tuning methods. The code is available online.
Create account to get full access
Overview
- Recent surge in Large Language Models (LLMs) has led to their increased use in various fields, including healthcare
- Fine-tuning is often required to adapt general LLMs for specific domains, like web-based healthcare systems
- Two key challenges arise when fine-tuning LLMs for medical applications:
- Task variety problem - real-world medical scenarios involve diverse tasks, leading to sub-optimal fine-tuning due to data imbalance and seesaw problems
- Huge time and computation consumption due to the large number of parameters in LLMs
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. They have become widely used across many different fields, including healthcare. However, when using these general LLMs for specific medical applications, some problems can arise.
One issue is the "task variety problem." In the real world, medical scenarios often involve a wide range of different tasks, from diagnosing diseases to recommending treatments. When trying to fine-tune an LLM to handle this variety of tasks, the model can struggle due to imbalances in the training data and challenges in learning to do multiple tasks well.
Another problem is the sheer size of LLMs, which have millions or billions of parameters. Fine-tuning these massive models for medical applications can be extremely time-consuming and computationally intensive.
To address these challenges, the researchers propose a new approach called MOELoRA. It aims to combine the benefits of two existing techniques: Mixture-of-Experts (MOE) for handling multiple tasks, and Low-Rank Adaptation (LoRA) for making the fine-tuning more efficient. By using a set of "expert" sub-models that can be selectively activated for different tasks, along with a compact low-rank representation, MOELoRA aims to overcome the limitations of previous approaches.
Technical Explanation
The researchers propose a novel framework called MOELoRA to address the challenges of fine-tuning LLMs for multi-task medical applications. MOELoRA combines the benefits of Mixture-of-Experts (MOE) and Low-Rank Adaptation (LoRA) techniques.
The key idea is to use multiple "expert" sub-models within the LLM, where each expert consists of a pair of low-rank matrices. This allows the model to retain a small number of trainable parameters while still being able to handle a variety of medical tasks. A task-motivated gate function is then used to determine the contribution of each expert for a given task.
The researchers evaluate MOELoRA on a multi-task medical dataset and find that it outperforms existing parameter-efficient fine-tuning methods. This suggests that the combination of MOE and LoRA is an effective way to adapt large language models for diverse medical applications while keeping the computational costs manageable.
Critical Analysis
The paper presents a promising approach to fine-tuning LLMs for multi-task medical applications, but there are a few potential limitations and areas for further research:
- The evaluation is limited to a single multi-task medical dataset, so it would be valuable to test the MOELoRA framework on a wider range of medical tasks and datasets to better understand its generalizability.
- The paper does not provide much insight into the specific medical tasks and how the MOELoRA framework performs on them individually. Further analysis of the model's strengths and weaknesses for different medical sub-tasks could be informative.
- While the parameter-efficiency of MOELoRA is a key advantage, the paper does not compare its computational efficiency to other fine-tuning approaches in terms of training time or resource usage. This would be an important practical consideration.
- Intuition-Aware Mixture of Rank-1 Experts is another relevant technique for parameter-efficient multi-task learning that could be compared to MOELoRA.
Overall, the MOELoRA approach appears to be a valuable contribution to the challenge of adapting large language models for diverse medical applications in an efficient manner. Further research and real-world deployment could help validate its effectiveness and identify any additional refinements or limitations.
Conclusion
The recent surge in Large Language Models (LLMs) has led to increased interest in using these powerful AI systems for medical applications. However, two key challenges arise when fine-tuning LLMs for multi-task medical scenarios: the "task variety problem" and the high computational cost due to the large number of model parameters.
To address these issues, the researchers propose a novel framework called MOELoRA, which combines the benefits of Mixture-of-Experts (MOE) and Low-Rank Adaptation (LoRA) techniques. By using a set of specialized "expert" sub-models and a compact low-rank representation, MOELoRA aims to handle a variety of medical tasks efficiently.
Experimental results on a multi-task medical dataset show that MOELoRA outperforms existing parameter-efficient fine-tuning methods, suggesting it is a promising approach for adapting large language models to diverse real-world medical applications. Further research and real-world deployment could help validate the effectiveness of this framework and identify any additional refinements or limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MING-MOE: Enhancing Medical Multi-Task Learning in Large Language Models with Sparse Mixture of Low-Rank Adapter Experts
Yusheng Liao, Shuyang Jiang, Yu Wang, Yanfeng Wang
0
0
Large language models like ChatGPT have shown substantial progress in natural language understanding and generation, proving valuable across various disciplines, including the medical field. Despite advancements, challenges persist due to the complexity and diversity inherent in medical tasks which often require multi-task learning capabilities. Previous approaches, although beneficial, fall short in real-world applications because they necessitate task-specific annotations at inference time, limiting broader generalization. This paper introduces MING-MOE, a novel Mixture-of-Expert~(MOE)-based medical large language model designed to manage diverse and complex medical tasks without requiring task-specific annotations, thus enhancing its usability across extensive datasets. MING-MOE employs a Mixture of Low-Rank Adaptation (MoLoRA) technique, allowing for efficient parameter usage by maintaining base model parameters static while adapting through a minimal set of trainable parameters. We demonstrate that MING-MOE achieves state-of-the-art (SOTA) performance on over 20 medical tasks, illustrating a significant improvement over existing models. This approach not only extends the capabilities of medical language models but also improves inference efficiency.
4/16/2024
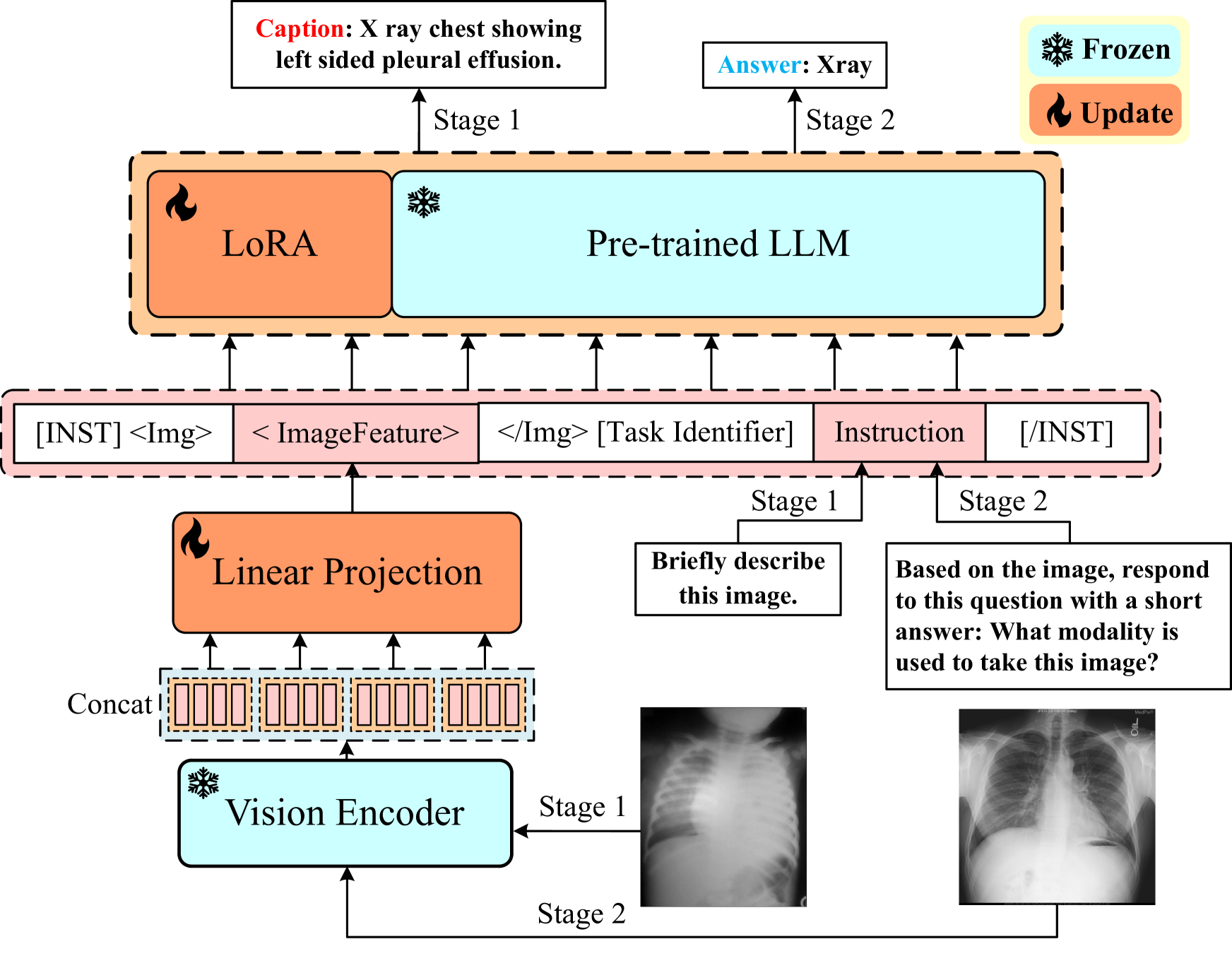
PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
Gang Liu, Jinlong He, Pengfei Li, Genrong He, Zhaolin Chen, Shenjun Zhong
0
0
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our fine-tuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
4/17/2024
🌐
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Cl'ement Christophe, Praveen K Kanithi, Prateek Munjal, Tathagata Raha, Nasir Hayat, Ronnie Rajan, Ahmed Al-Mahrooqi, Avani Gupta, Muhammad Umar Salman, Gurpreet Gosal, Bhargav Kanakiya, Charles Chen, Natalia Vassilieva, Boulbaba Ben Amor, Marco AF Pimentel, Shadab Khan
0
0
This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
4/24/2024

MoE-TinyMed: Mixture of Experts for Tiny Medical Large Vision-Language Models
Songtao Jiang, Tuo Zheng, Yan Zhang, Yeying Jin, Li Yuan, Zuozhu Liu
0
0
Recent advancements in general-purpose or domain-specific multimodal large language models (LLMs) have witnessed remarkable progress for medical decision-making. However, they are designated for specific classification or generative tasks, and require model training or finetuning on large-scale datasets with sizeable parameters and tremendous computing, hindering their clinical utility across diverse resource-constrained scenarios in practice. In this paper, we propose a novel and lightweight framework Med-MoE (Mixture-of-Experts) that tackles both discriminative and generative multimodal medical tasks. The learning of Med-MoE consists of three steps: multimodal medical alignment, instruction tuning and routing, and domain-specific MoE tuning. After aligning multimodal medical images with LLM tokens, we then enable the model for different multimodal medical tasks with instruction tuning, together with a trainable router tailored for expert selection across input modalities. Finally, the model is tuned by integrating the router with multiple domain-specific experts, which are selectively activated and further empowered by meta expert. Comprehensive experiments on both open- and close-end medical question answering (Med-VQA) and image classification tasks across datasets such as VQA-RAD, SLAKE and Path-VQA demonstrate that our model can achieve performance superior to or on par with state-of-the-art baselines, while only requiring approximately 30%-50% of activated model parameters. Extensive analysis and ablations corroborate the effectiveness and practical utility of our method.
6/27/2024