Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
2404.08985
0
0

Abstract
Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
Create account to get full access
Overview
- Proposes an "Intuition-aware Mixture-of-Rank-1-Experts" approach for parameter-efficient finetuning of large language models
- Aims to leverage task-specific intuitions to improve the performance and efficiency of finetuning
- Introduces a novel architecture that combines a shared backbone with a mixture of task-specific low-rank experts
Plain English Explanation
This research paper presents a new technique called "Intuition-aware Mixture-of-Rank-1-Experts" for efficiently finetuning large language models on specific tasks. The key idea is to leverage task-specific "intuitions" to improve the performance and efficiency of the finetuning process.
The approach works by combining a shared backbone model with a mixture of small, task-specific "expert" models. These experts are designed to be low-rank, meaning they have a compact representation that can be learned efficiently. The intuitions about each task are used to guide the training of these experts, helping them capture the important patterns in the data.
By using this mixture-of-experts architecture, the model can adapt to the specifics of each task while still benefiting from the knowledge encoded in the shared backbone. This can lead to better performance compared to finetuning the entire model, while also requiring fewer parameters to be updated during the finetuning process.
The authors demonstrate the effectiveness of their approach through experiments on various language tasks, showing improvements in both accuracy and parameter efficiency compared to standard finetuning techniques. This work contributes to the ongoing research on making large language models more flexible and adaptable to a wide range of applications.
Technical Explanation
The paper proposes an "Intuition-aware Mixture-of-Rank-1-Experts" (IA-MoRE) approach for parameter-efficient finetuning of large language models. The key idea is to leverage task-specific "intuitions" to guide the training of a mixture of low-rank expert models, which are then combined with a shared backbone model.
The IA-MoRE architecture consists of a shared backbone model and a collection of task-specific expert models. The experts are designed to be low-rank, meaning they have a compact representation that can be learned efficiently. The intuitions about each task are used to inform the training of these experts, helping them capture the important patterns in the data.
During finetuning, the input is processed by the shared backbone, and the resulting features are then combined with the task-specific expert models using a gating mechanism. This allows the model to adapt to the specifics of each task while still benefiting from the knowledge encoded in the shared backbone.
The authors evaluate their approach on a range of language tasks, including text classification, question answering, and natural language inference. They compare the performance and parameter efficiency of IA-MoRE to standard finetuning techniques, as well as other related methods, such as Toward Inference-Optimal Mixture of Experts for Large Language Models, OmniSMOLA: Boosting Generalist Multimodal Models with Soft Prompts, and Ming-MoE: Enhancing Medical Multi-Task Learning with Mixture-of-Experts. The results demonstrate the effectiveness of their approach in terms of both accuracy and parameter efficiency.
Critical Analysis
The paper introduces a novel and promising approach for parameter-efficient finetuning of large language models. The key strength of the IA-MoRE architecture is its ability to leverage task-specific intuitions to guide the training of the expert models, which can lead to better performance and efficiency compared to standard finetuning techniques.
However, the paper does not provide a detailed discussion of the potential limitations or caveats of the proposed approach. For example, it would be interesting to understand how the performance and efficiency of IA-MoRE scale as the number of tasks or the complexity of the tasks increases. Additionally, the authors do not address the potential challenges in defining and incorporating task-specific intuitions, which could be a subjective and non-trivial process.
Furthermore, the paper could benefit from a more thorough comparison to other related methods, such as Dense Training for Sparse Inference: Rethinking the Training-Inference Trade-off in Large-Scale Language Models and Prompt-Prompted Mixture-of-Experts for Efficient LLM Generation. A deeper analysis of the similarities, differences, and relative strengths of these approaches would provide a more comprehensive understanding of the current state of the art in parameter-efficient finetuning.
Conclusion
The "Intuition-aware Mixture-of-Rank-1-Experts" (IA-MoRE) approach proposed in this paper represents an interesting and promising step towards more efficient finetuning of large language models. By leveraging task-specific intuitions to guide the training of a mixture of low-rank expert models, the authors demonstrate improvements in both performance and parameter efficiency compared to standard finetuning techniques.
This research contributes to the ongoing efforts to make large language models more flexible and adaptable to a wide range of applications, while also addressing the challenge of parameter efficiency. As the field of natural language processing continues to evolve, techniques like IA-MoRE could play an important role in enabling the practical deployment of these powerful models in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
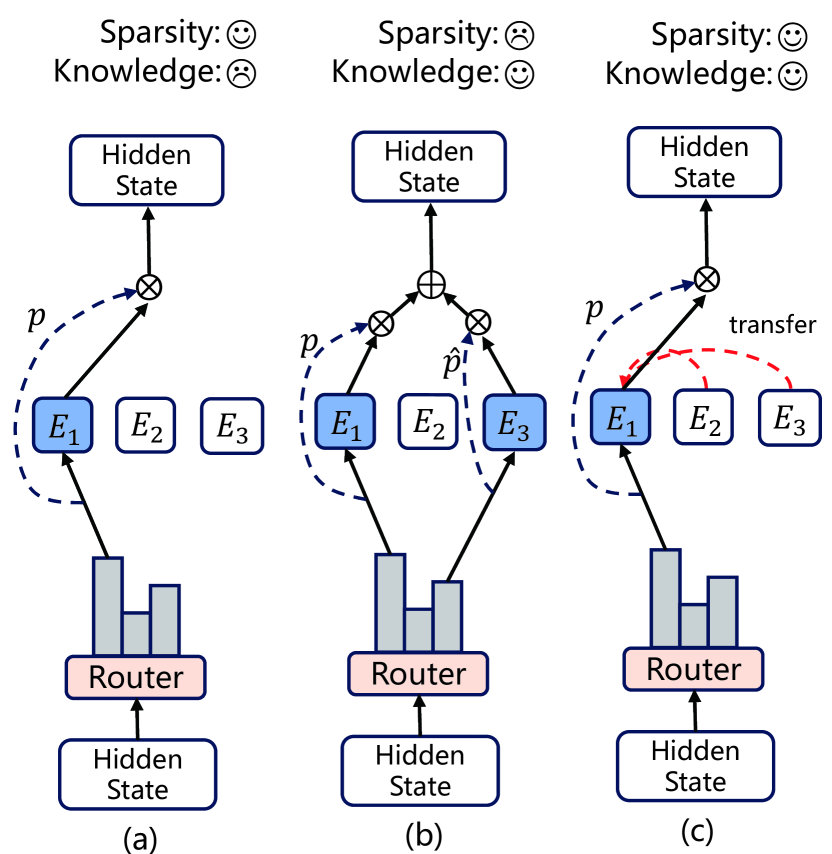
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024

Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li
0
0
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
5/31/2024
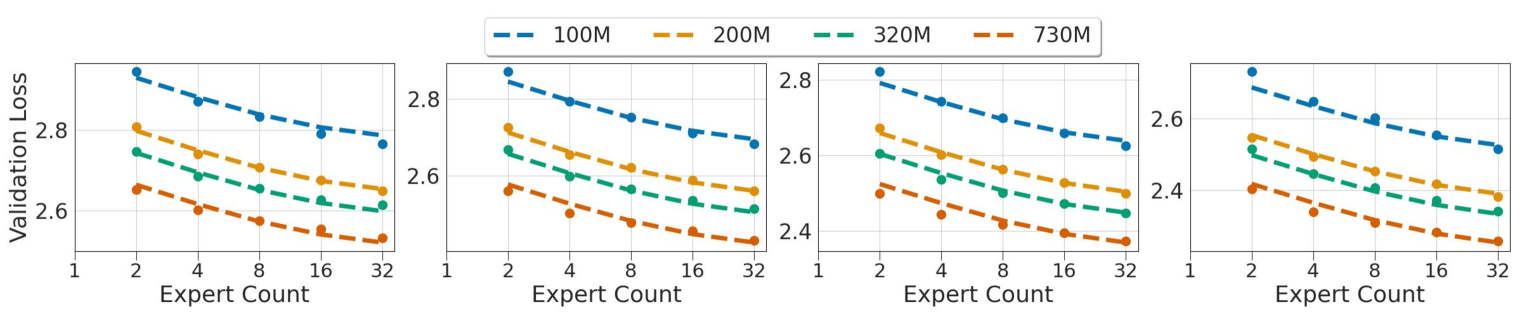
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024