When More Data Hurts: Optimizing Data Coverage While Mitigating Diversity Induced Underfitting in an Ultra-Fast Machine-Learned Potential

0

Sign in to get full access
Overview
- This research paper explores the challenges of using large datasets to train ultra-fast machine-learned potentials for materials modeling.
- The authors investigate how increasing data coverage can lead to "diversity-induced underfitting," where the model struggles to capture the full complexity of the materials' behavior.
- The paper proposes strategies to optimize data coverage while mitigating this issue, aiming to improve the accuracy and efficiency of these machine-learned potentials.
Plain English Explanation
When it comes to developing machine-learned potentials for modeling the properties of materials, the researchers found that having more data doesn't always lead to better results. In fact, they discovered a phenomenon called "diversity-induced underfitting," where increasing the data coverage actually caused the model to struggle to capture the full complexity of the materials' behavior.
To understand this better, imagine you're trying to teach a computer how to play a game like chess. If you only show it a few example games, the computer might not learn all the possible moves and strategies. But if you show it too many different games, the computer might get confused and have trouble figuring out the core rules and patterns of the game.
Similarly, in materials modeling, the researchers found that as they added more diverse data to train their machine-learned potentials, the models had a harder time learning the underlying physics and chemistry that govern how materials behave. This led to less accurate predictions, even though they had more data to work with.
To address this challenge, the researchers developed strategies to optimize the data coverage while still mitigating the diversity-induced underfitting. This involved carefully selecting and curating the training data to ensure it captured the most important aspects of the materials' behavior, without overwhelming the model with too much complexity.
By finding this balance, the researchers were able to create ultra-fast machine-learned potentials that were both accurate and efficient, with the potential to dramatically improve the speed and accuracy of materials modeling and design.
Technical Explanation
The paper explores the challenge of "diversity-induced underfitting" in the context of training ultra-fast machine-learned potentials for materials modeling. The authors hypothesize that increasing data coverage can lead to this phenomenon, where the model struggles to capture the full complexity of the materials' behavior due to the diversity of the training data.
To investigate this, the researchers trained their machine-learned potential on a range of datasets with varying levels of data coverage. They found that as they added more diverse data, the model's ability to accurately predict materials properties actually decreased, even though the overall amount of training data had increased.
The authors attribute this to the model's inability to effectively learn the underlying physics-based relationships within the materials when presented with too much diverse information. This "diversity-induced underfitting" phenomenon is in contrast to the more commonly observed issue of overfitting, where a model becomes too specialized on the training data and fails to generalize well.
To address this challenge, the researchers propose strategies to optimize the data coverage while mitigating the diversity-induced underfitting. This includes techniques such as:
- Carefully curating the training data to ensure it captures the most important aspects of the materials' behavior
- Employing physics-informed machine learning approaches to help the model learn the underlying physical principles
- Leveraging weakly supervised learning methods to supplement the training data with additional information about the materials' properties
By finding the right balance between data coverage and model complexity, the researchers were able to develop ultra-fast machine-learned potentials that maintained high accuracy and efficiency, demonstrating the potential of this approach for accelerating materials discovery and design.
Critical Analysis
The researchers in this paper have identified an important and often overlooked challenge in the development of machine-learned potentials for materials modeling: the risk of "diversity-induced underfitting." This phenomenon, where increasing the diversity of the training data can actually degrade the model's performance, is an important consideration that is not always appreciated in the field.
The authors' proposed strategies for optimizing data coverage and mitigating this issue are well-reasoned and potentially quite impactful. By carefully curating the training data and employing physics-informed and weakly supervised learning techniques, they were able to create ultra-fast machine-learned potentials that maintained high accuracy and efficiency.
However, it is worth noting that the specific implementation and effectiveness of these strategies may vary depending on the materials system and the available data. The paper does not provide a comprehensive evaluation of the generalizability of their approach, and further research may be needed to fully understand the boundaries and limitations of this technique.
Additionally, the authors do not delve deeply into the potential implications of this work for the broader field of materials science and engineering. While the development of accurate and efficient machine-learned potentials is undoubtedly valuable, the paper could have explored the broader impact of this research on areas like materials discovery, design, and simulation.
Overall, this paper makes an important contribution to the understanding of the challenges and potential solutions in training high-performing machine-learned potentials for materials modeling. The insights provided here could help inform the development of more robust and reliable models, ultimately accelerating the pace of materials innovation.
Conclusion
This research paper investigates the challenge of "diversity-induced underfitting" in the context of training ultra-fast machine-learned potentials for materials modeling. The authors found that increasing the data coverage for these models can actually degrade their performance, as the models struggle to capture the full complexity of the materials' behavior when presented with too much diverse information.
To address this issue, the researchers developed strategies to optimize the data coverage while mitigating the diversity-induced underfitting. By carefully curating the training data and employing physics-informed and weakly supervised learning techniques, they were able to create machine-learned potentials that maintained high accuracy and efficiency.
This work represents an important contribution to the field of materials modeling, as it highlights a crucial challenge that is often overlooked in the pursuit of ever-larger datasets. By finding the right balance between data coverage and model complexity, the authors have demonstrated a path forward for developing more robust and reliable machine-learned potentials, with the potential to accelerate materials discovery and design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
When More Data Hurts: Optimizing Data Coverage While Mitigating Diversity Induced Underfitting in an Ultra-Fast Machine-Learned Potential
Jason B. Gibson, Tesia D. Janicki, Ajinkya C. Hire, Chris Bishop, J. Matthew D. Lane, Richard G. Hennig
Machine-learned interatomic potentials (MLIPs) are becoming an essential tool in materials modeling. However, optimizing the generation of training data used to parameterize the MLIPs remains a significant challenge. This is because MLIPs can fail when encountering local enviroments too different from those present in the training data. The difficulty of determining textit{a priori} the environments that will be encountered during molecular dynamics (MD) simulation necessitates diverse, high-quality training data. This study investigates how training data diversity affects the performance of MLIPs using the Ultra-Fast Force Field (UF$^3$) to model amorphous silicon nitride. We employ expert and autonomously generated data to create the training data and fit four force-field variants to subsets of the data. Our findings reveal a critical balance in training data diversity: insufficient diversity hinders generalization, while excessive diversity can exceed the MLIP's learning capacity, reducing simulation accuracy. Specifically, we found that the UF$^3$ variant trained on a subset of the training data, in which nitrogen-rich structures were removed, offered vastly better prediction and simulation accuracy than any other variant. By comparing these UF$^3$ variants, we highlight the nuanced requirements for creating accurate MLIPs, emphasizing the importance of application-specific training data to achieve optimal performance in modeling complex material behaviors.
Read more9/14/2024

0
Overcoming systematic softening in universal machine learning interatomic potentials by fine-tuning
Bowen Deng, Yunyeong Choi, Peichen Zhong, Janosh Riebesell, Shashwat Anand, Zhuohan Li, KyuJung Jun, Kristin A. Persson, Gerbrand Ceder
Machine learning interatomic potentials (MLIPs) have introduced a new paradigm for atomic simulations. Recent advancements have seen the emergence of universal MLIPs (uMLIPs) that are pre-trained on diverse materials datasets, providing opportunities for both ready-to-use universal force fields and robust foundations for downstream machine learning refinements. However, their performance in extrapolating to out-of-distribution complex atomic environments remains unclear. In this study, we highlight a consistent potential energy surface (PES) softening effect in three uMLIPs: M3GNet, CHGNet, and MACE-MP-0, which is characterized by energy and force under-prediction in a series of atomic-modeling benchmarks including surfaces, defects, solid-solution energetics, phonon vibration modes, ion migration barriers, and general high-energy states. We find that the PES softening behavior originates from a systematic underprediction error of the PES curvature, which derives from the biased sampling of near-equilibrium atomic arrangements in uMLIP pre-training datasets. We demonstrate that the PES softening issue can be effectively rectified by fine-tuning with a single additional data point. Our findings suggest that a considerable fraction of uMLIP errors are highly systematic, and can therefore be efficiently corrected. This result rationalizes the data-efficient fine-tuning performance boost commonly observed with foundational MLIPs. We argue for the importance of a comprehensive materials dataset with improved PES sampling for next-generation foundational MLIPs.
Read more5/14/2024
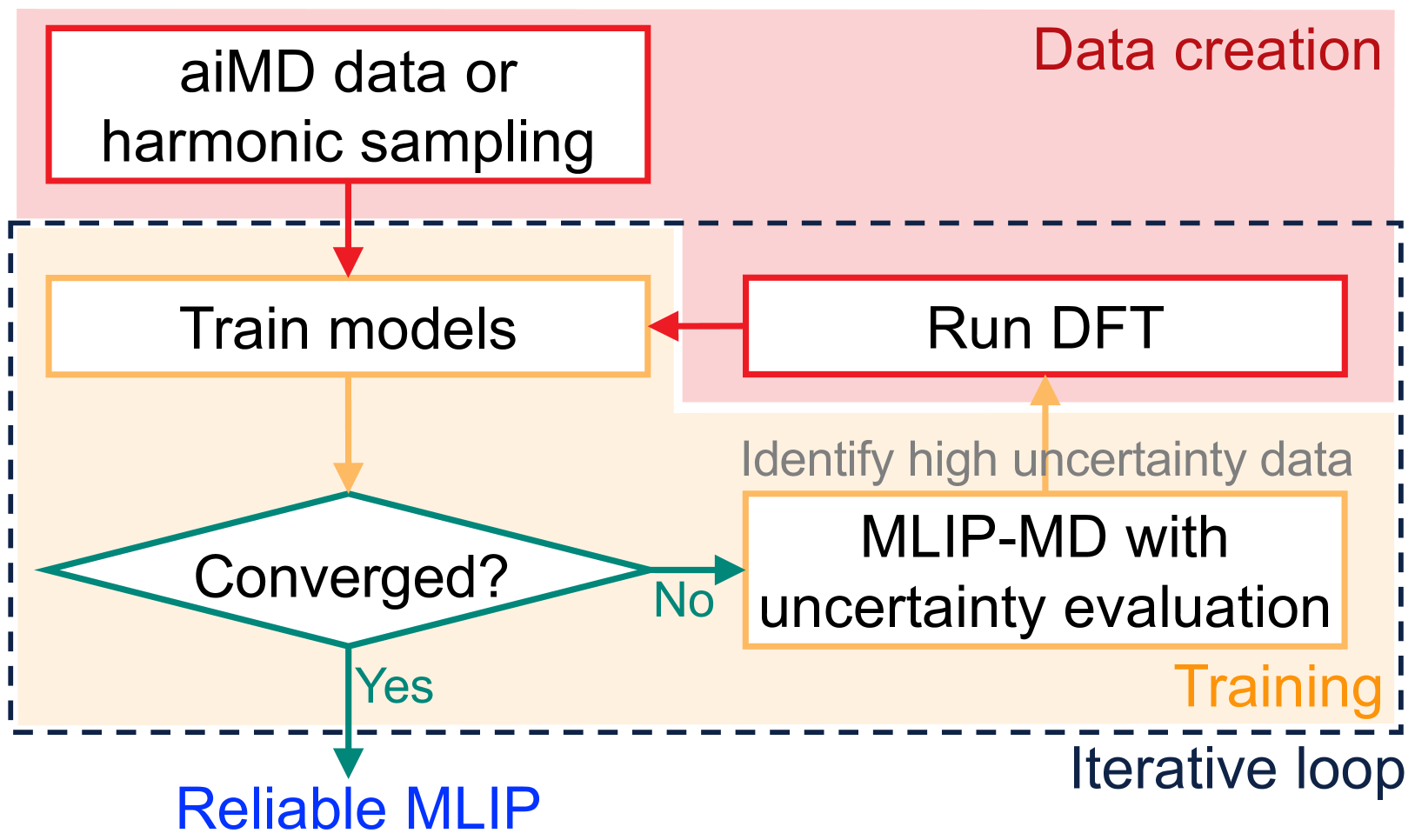
0
New!Accelerating the Training and Improving the Reliability of Machine-Learned Interatomic Potentials for Strongly Anharmonic Materials through Active Learning
Kisung Kang, Thomas A. R. Purcell, Christian Carbogno, Matthias Scheffler
Molecular dynamics (MD) employing machine-learned interatomic potentials (MLIPs) serve as an efficient, urgently needed complement to ab initio molecular dynamics (aiMD). By training these potentials on data generated from ab initio methods, their averaged predictions can exhibit comparable performance to ab initio methods at a fraction of the cost. However, insufficient training sets might lead to an improper description of the dynamics in strongly anharmonic materials, because critical effects might be overlooked in relevant cases, or only incorrectly captured, or hallucinated by the MLIP when they are not actually present. In this work, we show that an active learning scheme that combines MD with MLIPs (MLIP-MD) and uncertainty estimates can avoid such problematic predictions. In short, efficient MLIP-MD is used to explore configuration space quickly, whereby an acquisition function based on uncertainty estimates and on energetic viability is employed to maximize the value of the newly generated data and to focus on the most unfamiliar but reasonably accessible regions of phase space. To verify our methodology, we screen over 112 materials and identify 10 examples experiencing the aforementioned problems. Using CuI and AgGaSe$_2$ as archetypes for these problematic materials, we discuss the physical implications for strongly anharmonic effects and demonstrate how the developed active learning scheme can address these issues.
Read more9/19/2024

0
Physics-Informed Weakly Supervised Learning for Interatomic Potentials
Makoto Takamoto, Viktor Zaverkin, Mathias Niepert
Machine learning plays an increasingly important role in computational chemistry and materials science, complementing computationally intensive ab initio and first-principles methods. Despite their utility, machine-learning models often lack generalization capability and robustness during atomistic simulations, yielding unphysical energy and force predictions that hinder their real-world applications. We address this challenge by introducing a physics-informed, weakly supervised approach for training machine-learned interatomic potentials (MLIPs). We introduce two novel loss functions, extrapolating the potential energy via a Taylor expansion and using the concept of conservative forces. Our approach improves the accuracy of MLIPs applied to training tasks with sparse training data sets and reduces the need for pre-training computationally demanding models with large data sets. Particularly, we perform extensive experiments demonstrating reduced energy and force errors -- often lower by a factor of two -- for various baseline models and benchmark data sets. Finally, we show that our approach facilitates MLIPs' training in a setting where the computation of forces is infeasible at the reference level, such as those employing complete-basis-set extrapolation.
Read more8/13/2024