Wiener Chaos in Kernel Regression: Towards Untangling Aleatoric and Epistemic Uncertainty

0

Sign in to get full access
Overview
- Explores the use of Wiener chaos theory in kernel regression to untangle aleatoric (inherent randomness) and epistemic (model uncertainty) uncertainty
- Proposes a novel framework that leverages Wiener chaos expansion to quantify both types of uncertainty
- Demonstrates the effectiveness of the approach on several synthetic and real-world datasets
Plain English Explanation
The paper presents a new way to understand the different types of uncertainty that can arise in machine learning models. In particular, it focuses on kernel regression, a popular technique for making predictions based on data.
There are two main types of uncertainty that can affect the accuracy of these predictions:
- Aleatoric uncertainty - This is the inherent randomness or noise in the data itself, which can't be reduced no matter how the model is designed.
- Epistemic uncertainty - This is the uncertainty that comes from limitations in the model's ability to fully capture the underlying patterns in the data.
The researchers propose using a mathematical framework called Wiener chaos theory to quantify and disentangle these two types of uncertainty. By doing so, they can provide a more nuanced understanding of how much of the overall prediction uncertainty is due to each factor.
This information can be valuable for a variety of applications, such as helping researchers understand the fundamental limits of a given problem or enabling more robust decision-making in high-stakes scenarios.
Technical Explanation
The paper introduces a novel framework for kernel regression that leverages Wiener chaos expansion to quantify both aleatoric and epistemic uncertainty.
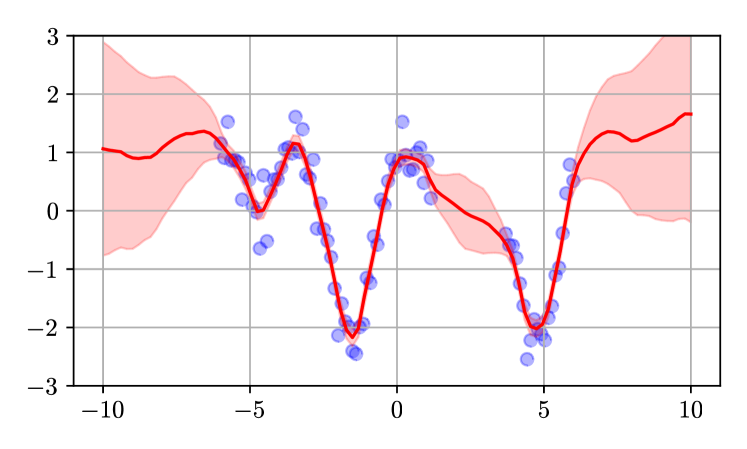
The key idea is to represent the kernel function in the regression model as a random variable, which allows the authors to decompose the total uncertainty into aleatoric and epistemic components. This is achieved by expressing the kernel function in terms of a Wiener chaos expansion, which is a way of representing random processes as a sum of orthogonal terms.
The researchers demonstrate the effectiveness of their approach on several synthetic and real-world datasets, including examples from computer vision and robotics. They show that the Wiener chaos framework can provide a more nuanced and informative characterization of the model's uncertainty compared to standard techniques.
Critical Analysis
The paper makes a valuable contribution by providing a principled way to disentangle aleatoric and epistemic uncertainty in kernel regression. This is an important problem, as understanding the different sources of uncertainty can inform model development, deployment, and decision-making.
One potential limitation is the computational complexity of the Wiener chaos expansion, which may limit its scalability to very high-dimensional problems. The authors acknowledge this and suggest exploring approximation techniques as an area for future work.
Additionally, the paper focuses on kernel regression, but the general approach could potentially be extended to other model classes, such as neural networks. Exploring these extensions could further broaden the impact of the proposed framework.
Overall, the paper presents a thoughtful and well-executed approach to a challenging problem in machine learning, and the results suggest promising avenues for further research and application.
Conclusion
This paper introduces a novel framework for kernel regression that leverages Wiener chaos theory to quantify and disentangle aleatoric and epistemic uncertainty. By providing a more nuanced characterization of the different sources of uncertainty, the proposed approach can offer valuable insights for a variety of machine learning applications.
The demonstrated effectiveness on synthetic and real-world datasets suggests that the Wiener chaos framework is a promising direction for further research and development in this area. As the field of machine learning continues to grapple with the challenges of uncertainty and robustness, tools like this can play an important role in advancing the state of the art.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Wiener Chaos in Kernel Regression: Towards Untangling Aleatoric and Epistemic Uncertainty
T. Faulwasser, O. Molodchyk
Gaussian Processes (GPs) are a versatile method that enables different approaches towards learning for dynamics and control. Gaussianity assumptions appear in two dimensions in GPs: The positive semi-definite kernel of the underlying reproducing kernel Hilbert space is used to construct the co-variance of a Gaussian distribution over functions, while measurement noise (i.e. data corruption) is usually modeled as i.i.d. additive Gaussians. In this note, we generalize the setting and consider kernel ridge regression with additive i.i.d. non-Gaussian measurement noise. To apply the usual kernel trick, we rely on the representation of the uncertainty via polynomial chaos expansions, which are series expansions for random variables of finite variance introduced by Norbert Wiener. We derive and discuss the analytic $mathcal{L}^2$ solution to the arising Wiener kernel regression. Considering a polynomial dynamic system as a numerical example, we show that our approach allows us to distinguish the uncertainty that stems from the noise in the data samples from the total uncertainty encoded in the GP posterior distribution.
Read more9/14/2024
↗️
0
Formal Verification of Unknown Dynamical Systems via Gaussian Process Regression
John Skovbekk, Luca Laurenti, Eric Frew, Morteza Lahijanian
Leveraging autonomous systems in safety-critical scenarios requires verifying their behaviors in the presence of uncertainties and black-box components that influence the system dynamics. In this work, we develop a framework for verifying discrete-time dynamical systems with unmodelled dynamics and noisy measurements against temporal logic specifications from an input-output dataset. The verification framework employs Gaussian process (GP) regression to learn the unknown dynamics from the dataset and abstracts the continuous-space system as a finite-state, uncertain Markov decision process (MDP). This abstraction relies on space discretization and transition probability intervals that capture the uncertainty due to the error in GP regression by using reproducible kernel Hilbert space analysis as well as the uncertainty induced by discretization. The framework utilizes existing model checking tools for verification of the uncertain MDP abstraction against a given temporal logic specification. We establish the correctness of extending the verification results on the abstraction created from noisy measurements to the underlying system. We show that the computational complexity of the framework is polynomial in the size of the dataset and discrete abstraction. The complexity analysis illustrates a trade-off between the quality of the verification results and the computational burden to handle larger datasets and finer abstractions. Finally, we demonstrate the efficacy of our learning and verification framework on several case studies with linear, nonlinear, and switched dynamical systems.
Read more7/17/2024
0
Epistemic Uncertainty and Observation Noise with the Neural Tangent Kernel
Sergio Calvo-Ordo~nez, Konstantina Palla, Kamil Ciosek
Recent work has shown that training wide neural networks with gradient descent is formally equivalent to computing the mean of the posterior distribution in a Gaussian Process (GP) with the Neural Tangent Kernel (NTK) as the prior covariance and zero aleatoric noise parencite{jacot2018neural}. In this paper, we extend this framework in two ways. First, we show how to deal with non-zero aleatoric noise. Second, we derive an estimator for the posterior covariance, giving us a handle on epistemic uncertainty. Our proposed approach integrates seamlessly with standard training pipelines, as it involves training a small number of additional predictors using gradient descent on a mean squared error loss. We demonstrate the proof-of-concept of our method through empirical evaluation on synthetic regression.
Read more9/11/2024
🌀
0
A New Reliable & Parsimonious Learning Strategy Comprising Two Layers of Gaussian Processes, to Address Inhomogeneous Empirical Correlation Structures
Gargi Roy, Dalia Chakrabarty
We present a new strategy for learning the functional relation between a pair of variables, while addressing inhomogeneities in the correlation structure of the available data, by modelling the sought function as a sample function of a non-stationary Gaussian Process (GP), that nests within itself multiple other GPs, each of which we prove can be stationary, thereby establishing sufficiency of two GP layers. In fact, a non-stationary kernel is envisaged, with each hyperparameter set as dependent on the sample function drawn from the outer non-stationary GP, such that a new sample function is drawn at every pair of input values at which the kernel is computed. However, such a model cannot be implemented, and we substitute this by recalling that the average effect of drawing different sample functions from a given GP is equivalent to that of drawing a sample function from each of a set of GPs that are rendered different, as updated during the equilibrium stage of the undertaken inference (via MCMC). The kernel is fully non-parametric, and it suffices to learn one hyperparameter per layer of GP, for each dimension of the input variable. We illustrate this new learning strategy on a real dataset.
Read more4/22/2024