WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback

0

Sign in to get full access
Overview
- This paper presents WildFeedback, a system for aligning large language models (LLMs) with user interactions and feedback in real-world settings.
- The key idea is to leverage in-situ user feedback to fine-tune LLMs and keep them aligned with user preferences and needs.
- The system is designed to work seamlessly with existing applications, capturing user interactions and feedback to continuously update the LLM.
Plain English Explanation
The paper describes a system called WildFeedback that helps keep large language models (LLMs) aligned with what users actually want and need. LLMs are powerful AI systems that can generate human-like text, but they can sometimes produce outputs that don't match what users are looking for.
The key insight behind WildFeedback is to use the feedback and interactions that users provide within the applications they're using. For example, if a user gives thumbs-down feedback on an LLM-generated response, that feedback can be used to fine-tune the LLM and improve its future outputs. This happens automatically and continuously, without disrupting the user experience.
The goal is to ensure the LLM stays closely aligned with real-world user needs and preferences, rather than drifting off in unintended directions. This could be especially important as LLMs become more widely used in a variety of applications that impact people's lives.
Technical Explanation
The WildFeedback system is designed to seamlessly integrate with existing applications and capture user interactions and feedback to continuously update and fine-tune the underlying LLM. This continuous, in-situ learning approach aims to keep the LLM aligned with user preferences and needs.
The system architecture includes several key components:
- User Interaction Capture: This module monitors user actions and captures relevant feedback signals, such as explicit ratings or implicit signals like dwell time.
- Feedback Processing: The captured feedback is processed and transformed into a format suitable for fine-tuning the LLM.
- LLM Fine-tuning: The processed feedback is used to fine-tune the LLM, updating its parameters to better match user preferences.
- Inference: The fine-tuned LLM is then used to generate responses for users, completing the feedback loop.
The continuous fine-tuning approach is designed to keep the LLM aligned with evolving user needs, rather than relying on a one-time fine-tuning process.
Critical Analysis
The paper presents a promising approach to aligning LLMs with user preferences, but it also acknowledges several potential limitations and areas for further research:
- Scalability: The authors note that the system's ability to scale to large numbers of users and applications may require further investigation and optimization.
- Feedback Bias: The paper recognizes that the user feedback captured by the system may be subject to various biases, which could introduce issues in the fine-tuning process. Addressing these biases is an important area for future work.
- Privacy and Security: The extensive data collection and processing involved in the WildFeedback system raises concerns about user privacy and potential security vulnerabilities that would need to be carefully addressed.
Conclusion
The WildFeedback system presents a novel approach to keeping large language models aligned with user preferences and needs in real-world applications. By continuously capturing and incorporating user feedback, the system aims to ensure that LLMs evolve to better match user expectations and requirements.
While the paper highlights several promising aspects of the approach, it also identifies important challenges and areas for further research. Addressing these concerns will be crucial as LLMs become more widely deployed and integrated into everyday applications that have a direct impact on people's lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Taiwei Shi, Zhuoer Wang, Longqi Yang, Ying-Chun Lin, Zexue He, Mengting Wan, Pei Zhou, Sujay Jauhar, Xiaofeng Xu, Xia Song, Jennifer Neville
As large language models (LLMs) continue to advance, aligning these models with human preferences has emerged as a critical challenge. Traditional alignment methods, relying on human or LLM annotated datasets, are limited by their resource-intensive nature, inherent subjectivity, and the risk of feedback loops that amplify model biases. To overcome these limitations, we introduce WildFeedback, a novel framework that leverages real-time, in-situ user interactions to create preference datasets that more accurately reflect authentic human values. WildFeedback operates through a three-step process: feedback signal identification, preference data construction, and user-guided evaluation. We applied this framework to a large corpus of user-LLM conversations, resulting in a rich preference dataset that reflects genuine user preferences. This dataset captures the nuances of user preferences by identifying and classifying feedback signals within natural conversations, thereby enabling the construction of more representative and context-sensitive alignment data. Our extensive experiments demonstrate that LLMs fine-tuned on WildFeedback exhibit significantly improved alignment with user preferences, as evidenced by both traditional benchmarks and our proposed user-guided evaluation. By incorporating real-time feedback from actual users, WildFeedback addresses the scalability, subjectivity, and bias challenges that plague existing approaches, marking a significant step toward developing LLMs that are more responsive to the diverse and evolving needs of their users. In summary, WildFeedback offers a robust, scalable solution for aligning LLMs with true human values, setting a new standard for the development and evaluation of user-centric language models.
Read more8/29/2024

0
Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
Read more8/9/2024
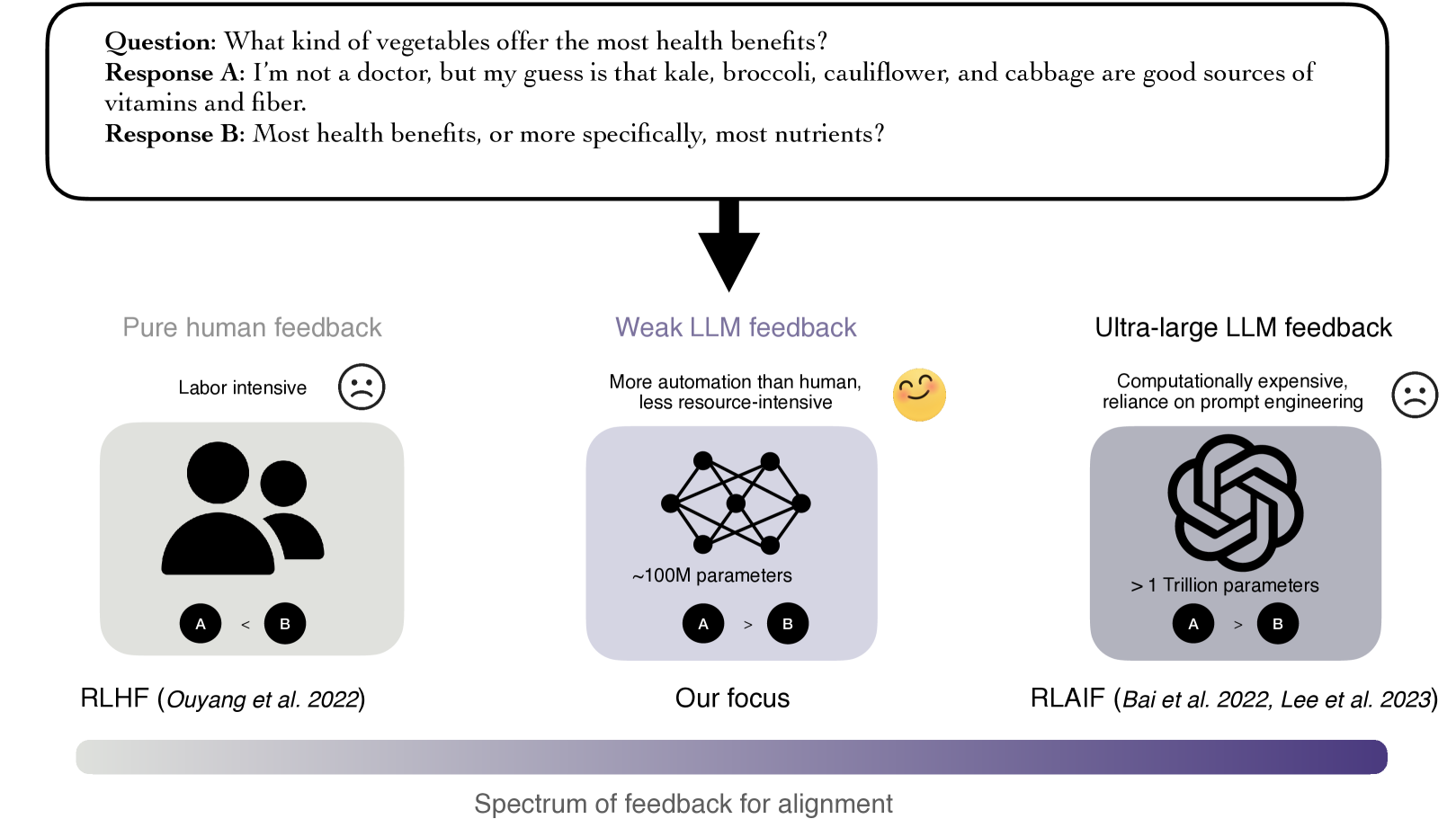
0
Your Weak LLM is Secretly a Strong Teacher for Alignment
Leitian Tao, Yixuan Li
The burgeoning capabilities of large language models (LLMs) have underscored the need for alignment to ensure these models act in accordance with human values and intentions. Existing alignment frameworks present constraints either in the form of expensive human effort or high computational costs. This paper explores a promising middle ground, where we employ a weak LLM that is significantly less resource-intensive than top-tier models, yet offers more automation than purely human feedback. We present a systematic study to evaluate and understand weak LLM's ability to generate feedback for alignment. Our empirical findings demonstrate that weak LLMs can provide feedback that rivals or even exceeds that of fully human-annotated data. Our study indicates a minimized impact of model size on feedback efficacy, shedding light on a scalable and sustainable alignment strategy. To deepen our understanding of alignment under weak LLM feedback, we conduct a series of qualitative and quantitative analyses, offering novel insights into the quality discrepancies between human feedback vs. weak LLM feedback.
Read more9/16/2024

0
CodeUltraFeedback: An LLM-as-a-Judge Dataset for Aligning Large Language Models to Coding Preferences
Martin Weyssow, Aton Kamanda, Houari Sahraoui
Evaluating the alignment of large language models (LLMs) with user-defined coding preferences is a challenging endeavour that requires a deep assessment of LLMs' outputs. Existing methods and benchmarks rely primarily on automated metrics and static analysis tools, which often fail to capture the nuances of user instructions and LLM outputs. To address this gap, we propose using the LLM-as-a-Judge methodology to evaluate the alignment of LLMs with coding preferences. Based on this approach, we present CodeUltraFeedback, a comprehensive dataset designed to facilitate the evaluation and improvement of LLM alignment. CodeUltraFeedback consists of 10,000 coding instructions, each annotated with four responses generated from a diverse pool of 14 LLMs. These responses are ranked based on five distinct coding preferences using GPT-3.5 as a judge, providing both numerical scores and detailed textual feedback. Our analysis of CodeUltraFeedback reveals that responses from GPT-3.5 and GPT-4 are generally preferred over those from open-weight LLMs, highlighting significant differences in alignment between closed and open-weight models. In turn, we explore the usage of CodeUltraFeedback as feedback data to fine-tune and align CodeLlama-7B-Instruct using supervised fine-tuning (SFT) and reinforcement learning from AI feedback (RLAIF) with direct preference optimization (DPO). The resulting aligned CodeLlama-7B-Instruct model outperforms larger LLMs in terms of alignment with coding preferences and shows improved functional correctness on the HumanEval+ benchmark compared to the original instruct model. Therefore, our contributions bridge the gap in preference tuning of LLMs for code and set the stage for further advancements in model alignment and RLAIF in automated software engineering.
Read more8/9/2024