Your Weak LLM is Secretly a Strong Teacher for Alignment

0
Sign in to get full access
Overview
- The paper explores how large language models (LLMs) can serve as strong supervisors for alignment, even when they appear weak.
- It proposes a framework for understanding how LLMs can transfer their knowledge to guide the training of more capable models.
- The key insight is that LLMs, despite their limitations, possess valuable knowledge about the world, language, and reasoning that can be leveraged to solve complex problems.
Plain English Explanation
The paper suggests that even LLMs that may seem "weak" or limited in certain capabilities can actually be valuable as strong supervisors for alignment. The core idea is that these LLMs have learned a significant amount about language, reasoning, and the world through their training, and this knowledge can be used to guide the development of more capable models.
The researchers propose a framework for understanding how this transfer of knowledge can occur. Even if an LLM has limitations or biases, it can still provide valuable signals and guidance that help steer the training of a more powerful model towards better alignment with human values and goals. This is analogous to how a human teacher, despite their own flaws and biases, can still impart important knowledge and insights to their students.
The key insight is that LLMs, through their broad exposure to information and their ability to generate coherent language and reason about complex topics, have acquired a wealth of knowledge and capabilities that can be leveraged, even if the models themselves are not perfect. By using these LLMs as "weak" supervisors, it may be possible to train much more capable and aligned AI systems.
Technical Explanation
The paper proposes a framework for understanding how LLMs can serve as strong supervisors for alignment, even when they appear "weak" or limited in certain capabilities. The key insight is that LLMs, through their training on vast amounts of data, have acquired a significant understanding of language, reasoning, and the world, which can be leveraged to guide the development of more capable and aligned AI systems.
The researchers argue that even if an LLM has biases or limitations, it can still provide valuable signals and guidance that help steer the training of a more powerful model towards better alignment with human values and goals. This is analogous to how a human teacher, despite their own flaws and biases, can still impart important knowledge and insights to their students.
The paper presents a framework for understanding how this transfer of knowledge can occur. The researchers suggest that LLMs, through their broad exposure to information and their ability to generate coherent language and reason about complex topics, have acquired a wealth of knowledge and capabilities that can be leveraged, even if the models themselves are not perfect. By using these LLMs as "weak" supervisors, it may be possible to train much more capable and aligned AI systems.
Critical Analysis
The paper raises some interesting points about the potential of LLMs to serve as effective supervisors for alignment, despite their apparent limitations. The researchers make a compelling case that even "weak" LLMs possess valuable knowledge and capabilities that can be harnessed to guide the development of more capable and aligned AI systems.
However, the paper does not delve into potential challenges or caveats associated with this approach. For example, it does not address how to mitigate the potential for LLM biases and limitations to be transferred to the more powerful models being trained. Additionally, the paper does not discuss the practical challenges of implementing this framework in real-world scenarios, such as the computational resources and data requirements needed to effectively leverage LLMs as supervisors.
Further research would be needed to better understand the boundaries and limitations of this approach, as well as to explore potential solutions to the challenges that may arise. It would also be valuable to see empirical evidence demonstrating the effectiveness of using LLMs as supervisors for alignment, as the paper primarily presents a conceptual framework without extensive experimental validation.
Conclusion
The paper presents a novel and thought-provoking perspective on the role of LLMs in the development of more capable and aligned AI systems. The key insight is that even "weak" LLMs possess valuable knowledge and capabilities that can be leveraged as strong supervisors for alignment, guiding the training of more powerful models. This framework offers a promising avenue for advancing the field of AI alignment and harnessing the potential of large language models, despite their limitations.
While the paper raises some important conceptual points, further research and empirical validation would be necessary to fully understand the practical implications and challenges of this approach. Nonetheless, the paper contributes a valuable perspective to the ongoing discussion on the role of LLMs in the development of safe and ethical AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Your Weak LLM is Secretly a Strong Teacher for Alignment
Leitian Tao, Yixuan Li
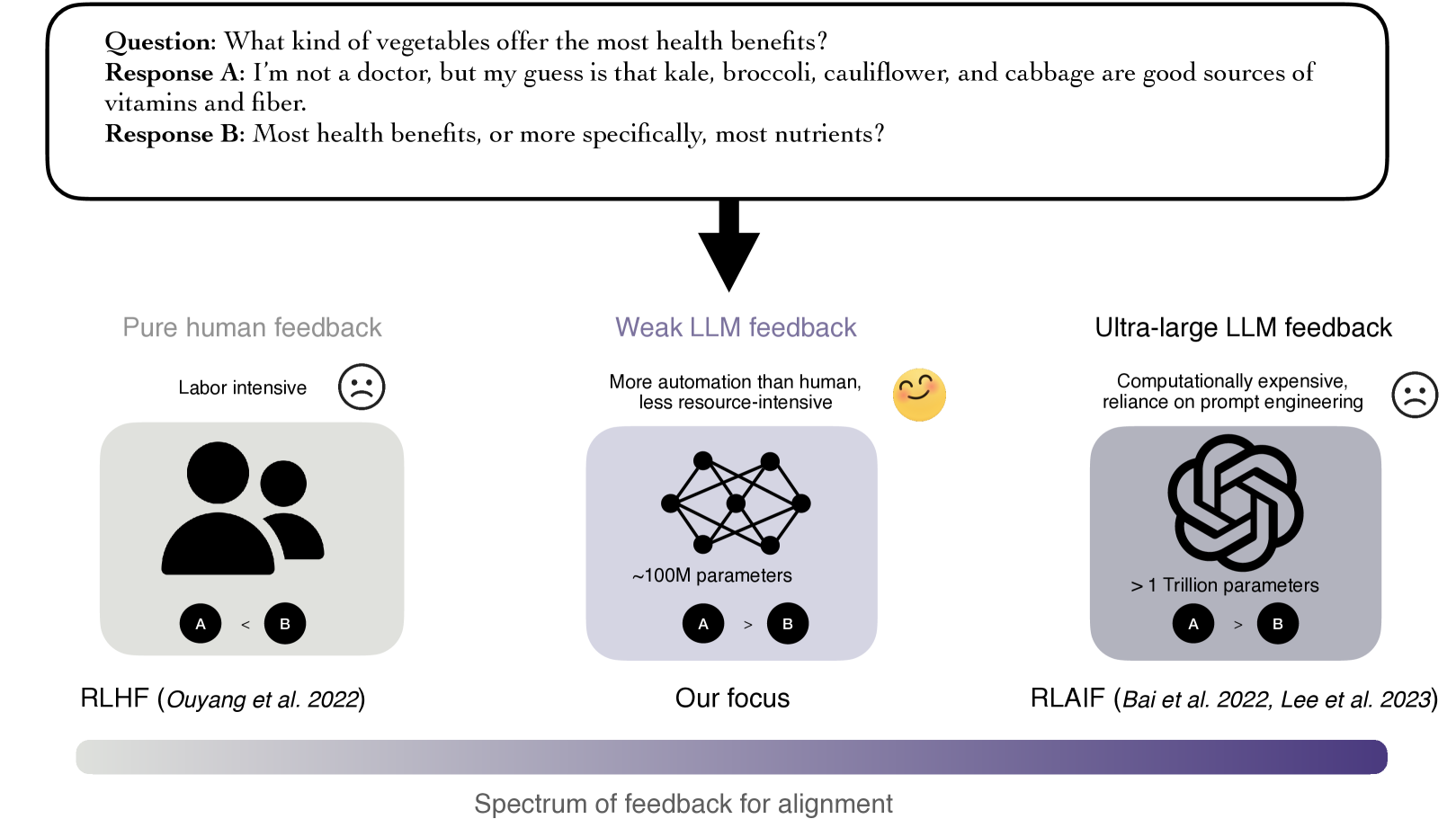
The burgeoning capabilities of large language models (LLMs) have underscored the need for alignment to ensure these models act in accordance with human values and intentions. Existing alignment frameworks present constraints either in the form of expensive human effort or high computational costs. This paper explores a promising middle ground, where we employ a weak LLM that is significantly less resource-intensive than top-tier models, yet offers more automation than purely human feedback. We present a systematic study to evaluate and understand weak LLM's ability to generate feedback for alignment. Our empirical findings demonstrate that weak LLMs can provide feedback that rivals or even exceeds that of fully human-annotated data. Our study indicates a minimized impact of model size on feedback efficacy, shedding light on a scalable and sustainable alignment strategy. To deepen our understanding of alignment under weak LLM feedback, we conduct a series of qualitative and quantitative analyses, offering novel insights into the quality discrepancies between human feedback vs. weak LLM feedback.
Read more9/16/2024
🤯
0
A statistical framework for weak-to-strong generalization
Seamus Somerstep, Felipe Maia Polo, Moulinath Banerjee, Ya'acov Ritov, Mikhail Yurochkin, Yuekai Sun
Modern large language model (LLM) alignment techniques rely on human feedback, but it is unclear whether the techniques fundamentally limit the capabilities of aligned LLMs. In particular, it is unclear whether it is possible to align (stronger) LLMs with superhuman capabilities with (weaker) human feedback without degrading their capabilities. This is an instance of the weak-to-strong generalization problem: using weaker (less capable) feedback to train a stronger (more capable) model. We prove that weak-to-strong generalization is possible by eliciting latent knowledge from pre-trained LLMs. In particular, we cast the weak-to-strong generalization problem as a transfer learning problem in which we wish to transfer a latent concept from a weak model to a strong pre-trained model. We prove that a naive fine-tuning approach suffers from fundamental limitations, but an alternative refinement-based approach suggested by the problem structure provably overcomes the limitations of fine-tuning. Finally, we demonstrate the practical applicability of the refinement approach with three LLM alignment tasks.
Read more5/28/2024

0
Improving Weak-to-Strong Generalization with Reliability-Aware Alignment
Yue Guo, Yi Yang
Large language models (LLMs) are now rapidly advancing and surpassing human abilities on many natural language tasks. However, aligning these super-human LLMs with human knowledge remains challenging because the supervision signals from human annotators may be wrong. This issue, known as the super-alignment problem, requires enhancing weak-to-strong generalization, where a strong LLM must generalize from imperfect supervision provided by a weaker source. To address this issue, we propose an approach to improve weak-to-strong generalization by involving the reliability of weak supervision signals in the alignment process. In our method, we query the weak supervisor for multiple answers, estimate the answer reliability, and enhance the alignment process by filtering out uncertain data or re-weighting reliable data. Experiments on four datasets demonstrate that our methods effectively identify the quality of weak labels and significantly enhance weak-to-strong generalization. Our work presents effective techniques for error-robust model alignment, reducing error propagation from noisy supervision and enhancing the accuracy and reliability of LLMs. Codes are publicly available at http://github.com/Irenehere/ReliableAlignment.
Read more6/28/2024

0
Strong and weak alignment of large language models with human values
Mehdi Khamassi, Marceau Nahon, Raja Chatila
Minimizing negative impacts of Artificial Intelligent (AI) systems on human societies without human supervision requires them to be able to align with human values. However, most current work only addresses this issue from a technical point of view, e.g., improving current methods relying on reinforcement learning from human feedback, neglecting what it means and is required for alignment to occur. Here, we propose to distinguish strong and weak value alignment. Strong alignment requires cognitive abilities (either human-like or different from humans) such as understanding and reasoning about agents' intentions and their ability to causally produce desired effects. We argue that this is required for AI systems like large language models (LLMs) to be able to recognize situations presenting a risk that human values may be flouted. To illustrate this distinction, we present a series of prompts showing ChatGPT's, Gemini's and Copilot's failures to recognize some of these situations. We moreover analyze word embeddings to show that the nearest neighbors of some human values in LLMs differ from humans' semantic representations. We then propose a new thought experiment that we call the Chinese room with a word transition dictionary, in extension of John Searle's famous proposal. We finally mention current promising research directions towards a weak alignment, which could produce statistically satisfying answers in a number of common situations, however so far without ensuring any truth value.
Read more8/13/2024