HaluEval-Wild: Evaluating Hallucinations of Language Models in the Wild
2403.04307
0
0
Abstract
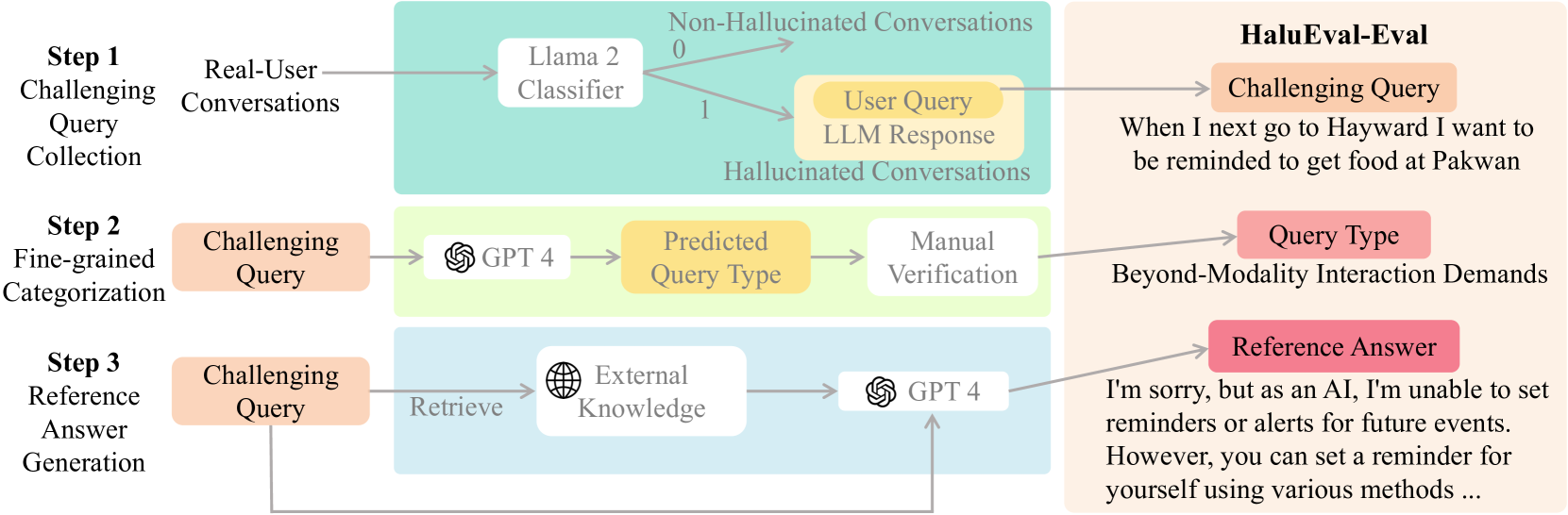
Hallucinations pose a significant challenge to the reliability of large language models (LLMs) in critical domains. Recent benchmarks designed to assess LLM hallucinations within conventional NLP tasks, such as knowledge-intensive question answering (QA) and summarization, are insufficient for capturing the complexities of user-LLM interactions in dynamic, real-world settings. To address this gap, we introduce HaluEval-Wild, the first benchmark specifically designed to evaluate LLM hallucinations in the wild. We meticulously collect challenging (adversarially filtered by Alpaca) user queries from existing real-world user-LLM interaction datasets, including ShareGPT, to evaluate the hallucination rates of various LLMs. Upon analyzing the collected queries, we categorize them into five distinct types, which enables a fine-grained analysis of the types of hallucinations LLMs exhibit, and synthesize the reference answers with the powerful GPT-4 model and retrieval-augmented generation (RAG). Our benchmark offers a novel approach towards enhancing our comprehension and improvement of LLM reliability in scenarios reflective of real-world interactions. Our benchmark is available at https://github.com/Dianezzy/HaluEval-Wild.
Create account to get full access
Overview
- This paper evaluates the ability of large language models (LLMs) to generate truthful and factual responses, also known as "hallucinations," in real-world scenarios.
- The researchers developed HaluEval-Wild, a new benchmark for measuring LLM hallucinations in the wild, which aims to provide a more realistic assessment compared to existing benchmarks.
- The paper presents the results of evaluating several prominent LLMs on the HaluEval-Wild benchmark, offering insights into the current state of hallucination generation in these models.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes produce "hallucinations" - information that appears truthful but is actually false or made up. This can be a significant issue, as LLMs are increasingly being used in real-world applications where accuracy and truthfulness are paramount.
The researchers behind this paper recognized the need for a more realistic way to assess LLM hallucinations. They developed a new benchmark called HaluEval-Wild, which aims to evaluate LLMs in real-world scenarios, rather than the more controlled environments used in previous benchmarks.
By testing several prominent LLMs on the HaluEval-Wild benchmark, the researchers were able to gain insights into the current state of hallucination generation in these models. This information can help researchers and developers improve the accuracy and trustworthiness of LLMs, ensuring they can be safely and effectively deployed in a wide range of applications.
Technical Explanation
The paper presents the development and application of the HaluEval-Wild benchmark, which aims to evaluate the hallucination generation capabilities of large language models (LLMs) in more realistic, open-domain scenarios.
The researchers first identified several limitations of existing hallucination benchmarks, which tend to focus on specific domains or use highly curated datasets. To address these limitations, they created HaluEval-Wild, which uses a diverse set of prompts and information sources from the real world, including web pages, news articles, and social media posts.
The researchers then evaluated several prominent LLMs, including GPT-3, InstructGPT, and Anthropic's Constitutional AI, on the HaluEval-Wild benchmark. The models were tasked with generating responses to the prompts, and their outputs were manually annotated by human raters to identify hallucinations.
The results of the evaluation revealed that even state-of-the-art LLMs struggle with hallucination generation in real-world scenarios, with all models exhibiting significant rates of hallucination on the HaluEval-Wild benchmark. The paper also provides insights into the types of hallucinations generated by the models and the factors that may contribute to their occurrence.
Critical Analysis
The HaluEval-Wild benchmark presented in this paper represents a significant step forward in the evaluation of LLM hallucinations. By using a more diverse and realistic set of prompts and information sources, the benchmark provides a more comprehensive assessment of hallucination generation in LLMs compared to previous approaches.
However, the paper acknowledges several limitations of the HaluEval-Wild benchmark, including the potential for bias in the manual annotation process and the difficulty of fully capturing the nuances of real-world communication. Additionally, the paper does not explore the potential root causes of the hallucinations observed in the LLMs, which could be a valuable area for future research.
Furthermore, while the paper provides a valuable snapshot of the current state of hallucination generation in LLMs, it remains to be seen how these models will continue to evolve and improve over time. Ongoing monitoring and evaluation, as well as further refinement of the HaluEval-Wild benchmark, will be essential to ensuring the reliable and trustworthy deployment of LLMs in real-world applications.
Conclusion
This paper introduces the HaluEval-Wild benchmark, a new approach to evaluating hallucination generation in large language models (LLMs) in more realistic, open-domain scenarios. The results of the evaluation reveal that even state-of-the-art LLMs struggle with hallucination generation in real-world settings, highlighting the need for continued research and development to improve the accuracy and trustworthiness of these powerful AI systems.
The insights gained from this study can inform the ongoing efforts to address hallucinations in multimodal LLMs and large vision-language models, as well as the development of techniques to enhance the summarization capabilities of LLMs while mitigating hallucinations. By continuing to push the boundaries of LLM evaluation and improvement, researchers can help ensure the safe and trustworthy deployment of these powerful AI systems in a wide range of real-world applications, including medical visual question answering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiaHalu: A Dialogue-level Hallucination Evaluation Benchmark for Large Language Models
Kedi Chen, Qin Chen, Jie Zhou, Yishen He, Liang He
0
0
Since large language models (LLMs) achieve significant success in recent years, the hallucination issue remains a challenge, numerous benchmarks are proposed to detect the hallucination. Nevertheless, some of these benchmarks are not naturally generated by LLMs but are intentionally induced. Also, many merely focus on the factuality hallucination while ignoring the faithfulness hallucination. Additionally, although dialogue pattern is more widely utilized in the era of LLMs, current benchmarks only concentrate on sentence-level and passage-level hallucination. In this study, we propose DiaHalu, the first dialogue-level hallucination evaluation benchmark to our knowledge. Initially, we integrate the collected topics into system prompts and facilitate a dialogue between two ChatGPT3.5. Subsequently, we manually modify the contents that do not adhere to human language conventions and then have LLMs re-generate, simulating authentic human-machine interaction scenarios. Finally, professional scholars annotate all the samples in the dataset. DiaHalu covers four common multi-turn dialogue domains and five hallucination subtypes, extended from factuality and faithfulness hallucination. Experiments through some well-known LLMs and detection methods on the dataset show that DiaHalu is a challenging benchmark, holding significant value for further research.
6/18/2024

UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Xun Liang, Shichao Song, Simin Niu, Zhiyu Li, Feiyu Xiong, Bo Tang, Yezhaohui Wang, Dawei He, Peng Cheng, Zhonghao Wang, Haiying Deng
0
0
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.
5/27/2024
The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Giwon Hong, Aryo Pradipta Gema, Rohit Saxena, Xiaotang Du, Ping Nie, Yu Zhao, Laura Perez-Beltrachini, Max Ryabinin, Xuanli He, Pasquale Minervini
0
0
Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
4/10/2024

HalluDial: A Large-Scale Benchmark for Automatic Dialogue-Level Hallucination Evaluation
Wen Luo, Tianshu Shen, Wei Li, Guangyue Peng, Richeng Xuan, Houfeng Wang, Xi Yang
0
0
Large Language Models (LLMs) have significantly advanced the field of Natural Language Processing (NLP), achieving remarkable performance across diverse tasks and enabling widespread real-world applications. However, LLMs are prone to hallucination, generating content that either conflicts with established knowledge or is unfaithful to the original sources. Existing hallucination benchmarks primarily focus on sentence- or passage-level hallucination detection, neglecting dialogue-level evaluation, hallucination localization, and rationale provision. They also predominantly target factuality hallucinations while underestimating faithfulness hallucinations, often relying on labor-intensive or non-specialized evaluators. To address these limitations, we propose HalluDial, the first comprehensive large-scale benchmark for automatic dialogue-level hallucination evaluation. HalluDial encompasses both spontaneous and induced hallucination scenarios, covering factuality and faithfulness hallucinations. The benchmark includes 4,094 dialogues with a total of 146,856 samples. Leveraging HalluDial, we conduct a comprehensive meta-evaluation of LLMs' hallucination evaluation capabilities in information-seeking dialogues and introduce a specialized judge language model, HalluJudge. The high data quality of HalluDial enables HalluJudge to achieve superior or competitive performance in hallucination evaluation, facilitating the automatic assessment of dialogue-level hallucinations in LLMs and providing valuable insights into this phenomenon. The dataset and the code are available at https://github.com/FlagOpen/HalluDial.
6/12/2024