Will My Robot Achieve My Goals? Predicting the Probability that an MDP Policy Reaches a User-Specified Behavior Target
2211.16462
0
0
🎲
Abstract
As an autonomous system performs a task, it should maintain a calibrated estimate of the probability that it will achieve the user's goal. If that probability falls below some desired level, it should alert the user so that appropriate interventions can be made. This paper considers settings where the user's goal is specified as a target interval for a real-valued performance summary, such as the cumulative reward, measured at a fixed horizon $H$. At each time $t in {0, ldots, H-1}$, our method produces a calibrated estimate of the probability that the final cumulative reward will fall within a user-specified target interval $[y^-,y^+].$ Using this estimate, the autonomous system can raise an alarm if the probability drops below a specified threshold. We compute the probability estimates by inverting conformal prediction. Our starting point is the Conformalized Quantile Regression (CQR) method of Romano et al., which applies split-conformal prediction to the results of quantile regression. CQR is not invertible, but by using the conditional cumulative distribution function (CDF) as the non-conformity measure, we show how to obtain an invertible modification that we call Probability-space Conformalized Quantile Regression (PCQR). Like CQR, PCQR produces well-calibrated conditional prediction intervals with finite-sample marginal guarantees. By inverting PCQR, we obtain guarantees for the probability that the cumulative reward of an autonomous system will fall below a threshold sampled from the marginal distribution of the response variable (i.e., a calibrated CDF estimate) that we employ to predict coverage probabilities for user-specified target intervals. Experiments on two domains confirm that these probabilities are well-calibrated.
Create account to get full access
Overview
- As an autonomous system performs a task, it should be able to estimate the probability that it will successfully achieve the user's goal.
- If the probability falls below a desired level, the system should alert the user so they can intervene.
- This paper focuses on settings where the user's goal is defined as a target interval for a real-valued performance summary, such as cumulative reward, at a fixed time horizon.
- The paper presents a method to produce a calibrated estimate of the probability that the final cumulative reward will fall within the user-specified target interval.
Plain English Explanation
Imagine you have a robot that's trying to complete a task for you. As the robot works, it should be able to estimate how likely it is to successfully finish the task and achieve your desired goal. This goal might be something like earning a certain amount of points or rewards by the end of the task.
If the robot starts to think it's unlikely to reach your goal, it should let you know so you can step in and help. That way, you can make adjustments or provide guidance to get the robot back on track.
The researchers in this paper looked at a specific type of goal, where you define a target range of values that you want the robot to reach. For example, you might want the robot to earn between 50 and 75 points by the end of the task.
The paper presents a method that allows the robot to continuously calculate the probability that it will end up within your target range. If that probability drops too low, the robot can give you a warning. This helps ensure the robot is on the right path to achieving your objective.
Technical Explanation
The key idea is to use a technique called "Probability-space Conformalized Quantile Regression" (PCQR) to estimate the probability that the autonomous system's cumulative performance will fall within the user's target interval.
PCQR builds on an existing method called "Conformalized Quantile Regression" (CQR), which applies "conformal prediction" to the results of quantile regression. Quantile regression allows you to model different percentiles of a response variable (like cumulative reward) based on input features.
However, CQR is not directly invertible to obtain probability estimates. The researchers show how to modify CQR by using the conditional cumulative distribution function (CDF) as the "non-conformity measure." This yields the PCQR method, which can produce well-calibrated probability estimates with finite-sample guarantees.
By inverting the PCQR model, the autonomous system can obtain a calibrated CDF estimate for the cumulative reward. This allows the system to directly calculate the probability that the reward will fall within the user's target interval.
The paper demonstrates the effectiveness of this approach through experiments in two different domains, confirming that the probability estimates are properly calibrated.
Critical Analysis
The paper provides a robust theoretical framework and empirical validation for the PCQR method. However, a few potential limitations or areas for further research are worth noting:
- The paper focuses on a fixed time horizon, but in many real-world scenarios, the user's goal may be more open-ended or have a variable time frame. Extending the approach to handle more flexible goal definitions could increase its practical applicability.
- The experiments were conducted on relatively simple domains. Evaluating the method's performance on more complex, real-world autonomous systems would help assess its scalability and practical usefulness.
- The paper does not explore how the probability estimates could be used to guide the autonomous system's decision-making or inform the user's interventions. Investigating these aspects could further enhance the usefulness of the approach.
Overall, the research presents a promising technique for enabling autonomous systems to maintain calibrated goal-achievement probability estimates, which can support more reliable and transparent human-machine collaboration.
Conclusion
This paper introduces a novel method called Probability-space Conformalized Quantile Regression (PCQR) that allows autonomous systems to continuously monitor the probability of achieving a user-specified performance goal. By providing well-calibrated probability estimates, the system can alert the user when the likelihood of success drops below a desired threshold, enabling timely interventions.
The technical approach builds upon existing conformal prediction techniques, offering a principled way to invert quantile regression models and obtain reliable probability estimates. The experimental validation demonstrates the effectiveness of the method, suggesting its potential to enhance the transparency and reliability of autonomous decision-making systems.
As autonomous technologies become more prevalent, tools like PCQR can play a crucial role in fostering trust and enabling seamless human-machine collaboration, where the autonomous system's goals and progress are clearly communicated to the user. Further research to expand the method's capabilities and explore its real-world applications could yield valuable insights for the field of autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Conformalized Teleoperation: Confidently Mapping Human Inputs to High-Dimensional Robot Actions
Michelle Zhao, Reid Simmons, Henny Admoni, Andrea Bajcsy
0
0
Assistive robotic arms often have more degrees-of-freedom than a human teleoperator can control with a low-dimensional input, like a joystick. To overcome this challenge, existing approaches use data-driven methods to learn a mapping from low-dimensional human inputs to high-dimensional robot actions. However, determining if such a black-box mapping can confidently infer a user's intended high-dimensional action from low-dimensional inputs remains an open problem. Our key idea is to adapt the assistive map at training time to additionally estimate high-dimensional action quantiles, and then calibrate these quantiles via rigorous uncertainty quantification methods. Specifically, we leverage adaptive conformal prediction which adjusts the intervals over time, reducing the uncertainty bounds when the mapping is performant and increasing the bounds when the mapping consistently mis-predicts. Furthermore, we propose an uncertainty-interval-based mechanism for detecting high-uncertainty user inputs and robot states. We evaluate the efficacy of our proposed approach in a 2D assistive navigation task and two 7DOF Kinova Jaco tasks involving assistive cup grasping and goal reaching. Our findings demonstrate that conformalized assistive teleoperation manages to detect (but not differentiate between) high uncertainty induced by diverse preferences and induced by low-precision trajectories in the mapping's training dataset. On the whole, we see this work as a key step towards enabling robots to quantify their own uncertainty and proactively seek intervention when needed.
6/13/2024
Adaptive Uncertainty Quantification for Trajectory Prediction Under Distributional Shift
Huiqun Huang, Sihong He, Fei Miao
0
0
Trajectory prediction models that can infer both finite future trajectories and their associated uncertainties of the target vehicles in an online setting (e.g., real-world application scenarios) is crucial for ensuring the safe and robust navigation and path planning of autonomous vehicle motion. However, the majority of existing trajectory prediction models have neither considered reducing the uncertainty as one objective during the training stage nor provided reliable uncertainty quantification during inference stage under potential distribution shift. Therefore, in this paper, we propose the Conformal Uncertainty Quantification under Distribution Shift framework, CUQDS, to quantify the uncertainty of the predicted trajectories of existing trajectory prediction models under potential data distribution shift, while considering improving the prediction accuracy of the models and reducing the estimated uncertainty during the training stage. Specifically, CUQDS includes 1) a learning-based Gaussian process regression module that models the output distribution of the base model (any existing trajectory prediction or time series forecasting neural networks) and reduces the estimated uncertainty by additional loss term, and 2) a statistical-based Conformal P control module to calibrate the estimated uncertainty from the Gaussian process regression module in an online setting under potential distribution shift between training and testing data.
6/19/2024

Guarantees on Robot System Performance Using Stochastic Simulation Rollouts
Joseph A. Vincent, Aaron O. Feldman, Mac Schwager
0
0
We provide finite-sample performance guarantees for control policies executed on stochastic robotic systems. Given an open- or closed-loop policy and a finite set of trajectory rollouts under the policy, we bound the expected value, value-at-risk, and conditional-value-at-risk of the trajectory cost, and the probability of failure in a sparse cost setting. The bounds hold, with user-specified probability, for any policy synthesis technique and can be seen as a post-design safety certification. Generating the bounds only requires sampling simulation rollouts, without assumptions on the distribution or complexity of the underlying stochastic system. We adapt these bounds to also give a constraint satisfaction test to verify safety of the robot system. We provide a thorough analysis of the bound sensitivity to sim-to-real distribution shifts and provide results for constructing robust bounds that can tolerate some specified amount of distribution shift. Furthermore, we extend our method to apply when selecting the best policy from a set of candidates, requiring a multi-hypothesis correction. We show the statistical validity of our bounds in the Ant, Half-cheetah, and Swimmer MuJoCo environments and demonstrate our constraint satisfaction test with the Ant. Finally, using the 20 degree-of-freedom MuJoCo Shadow Hand, we show the necessity of the multi-hypothesis correction.
6/17/2024
ConstrainedZero: Chance-Constrained POMDP Planning using Learned Probabilistic Failure Surrogates and Adaptive Safety Constraints
Robert J. Moss, Arec Jamgochian, Johannes Fischer, Anthony Corso, Mykel J. Kochenderfer
0
0
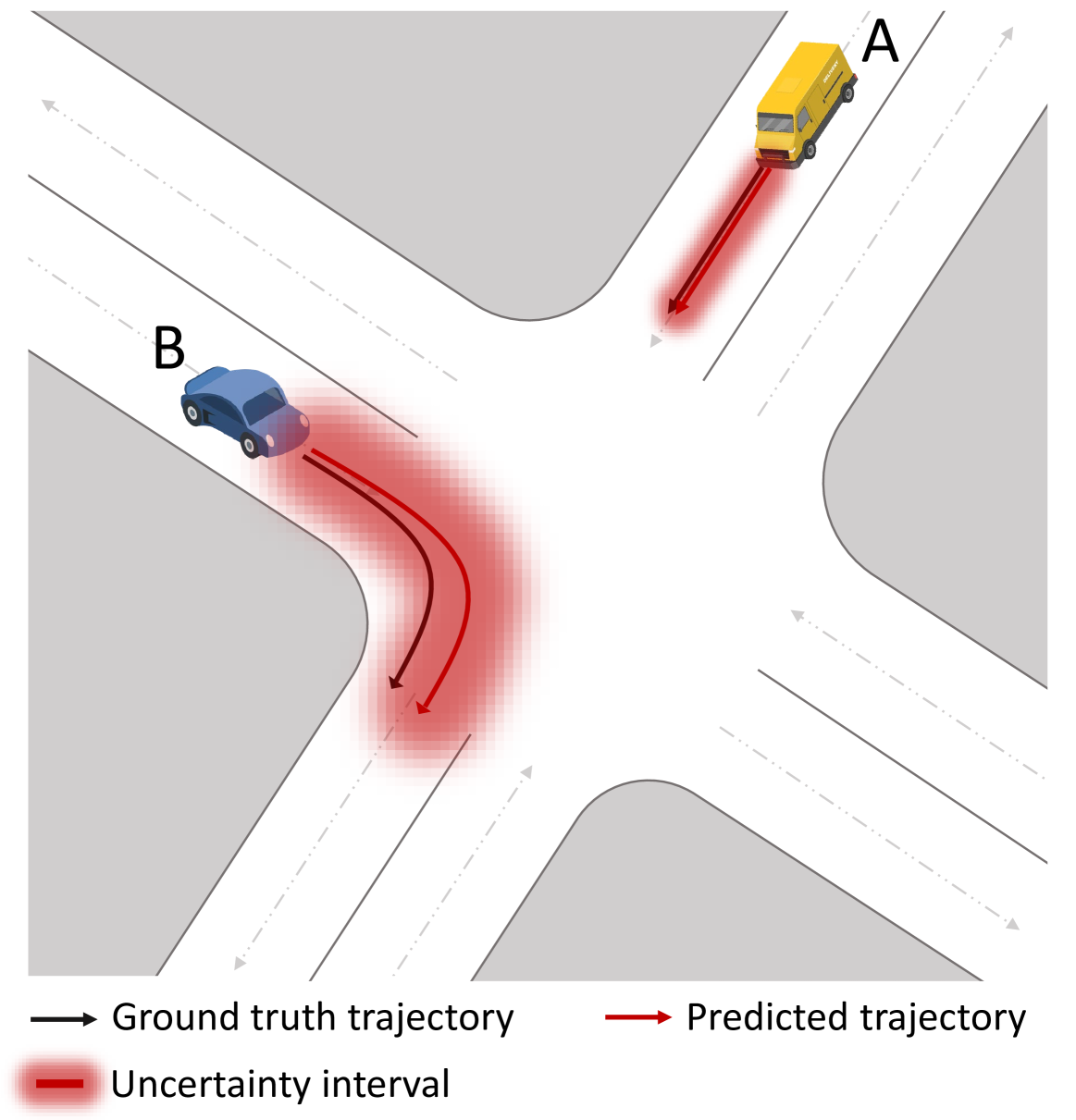
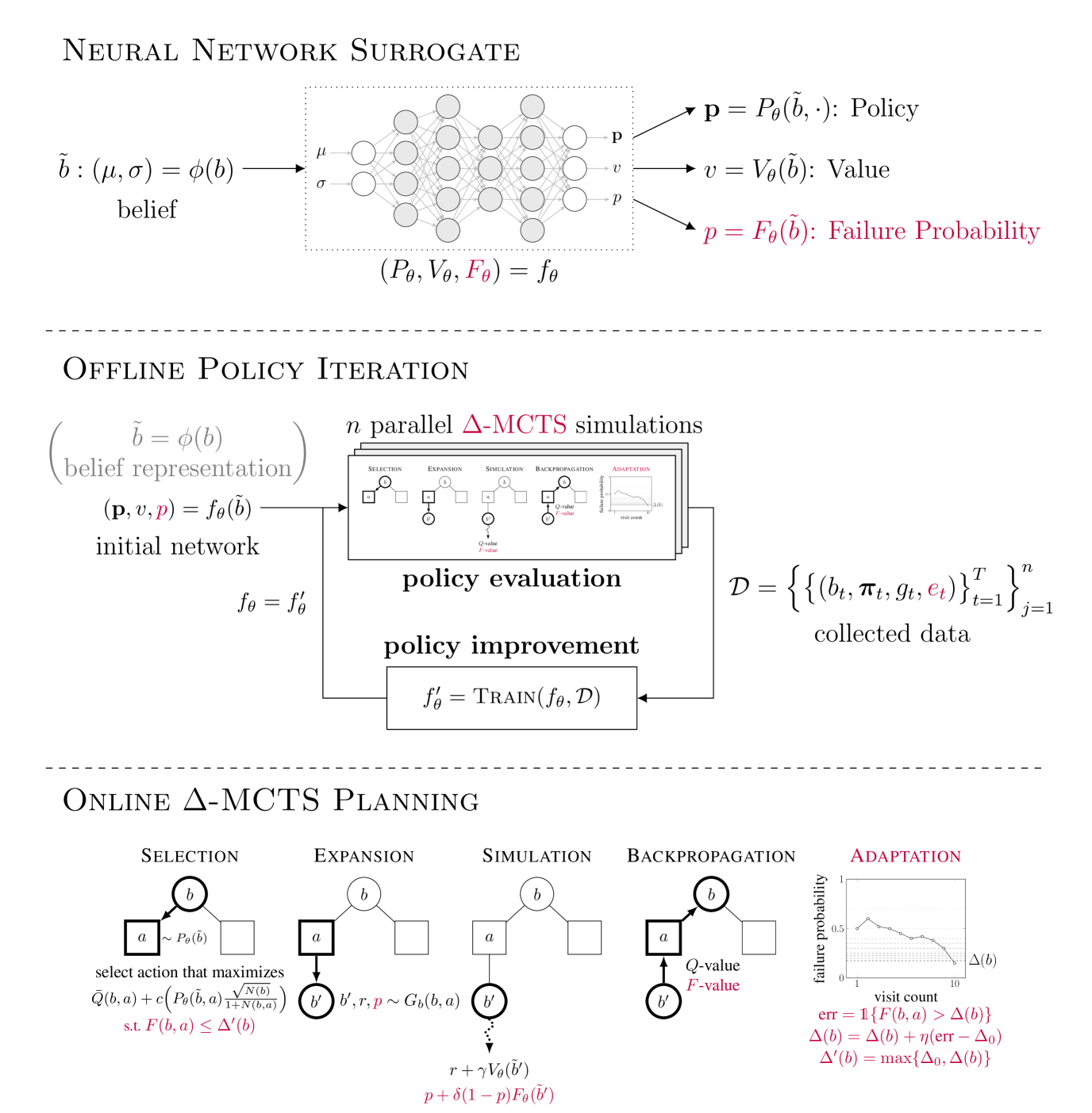
To plan safely in uncertain environments, agents must balance utility with safety constraints. Safe planning problems can be modeled as a chance-constrained partially observable Markov decision process (CC-POMDP) and solutions often use expensive rollouts or heuristics to estimate the optimal value and action-selection policy. This work introduces the ConstrainedZero policy iteration algorithm that solves CC-POMDPs in belief space by learning neural network approximations of the optimal value and policy with an additional network head that estimates the failure probability given a belief. This failure probability guides safe action selection during online Monte Carlo tree search (MCTS). To avoid overemphasizing search based on the failure estimates, we introduce $Delta$-MCTS, which uses adaptive conformal inference to update the failure threshold during planning. The approach is tested on a safety-critical POMDP benchmark, an aircraft collision avoidance system, and the sustainability problem of safe CO$_2$ storage. Results show that by separating safety constraints from the objective we can achieve a target level of safety without optimizing the balance between rewards and costs.
5/2/2024