ConstrainedZero: Chance-Constrained POMDP Planning using Learned Probabilistic Failure Surrogates and Adaptive Safety Constraints
2405.00644
0
0
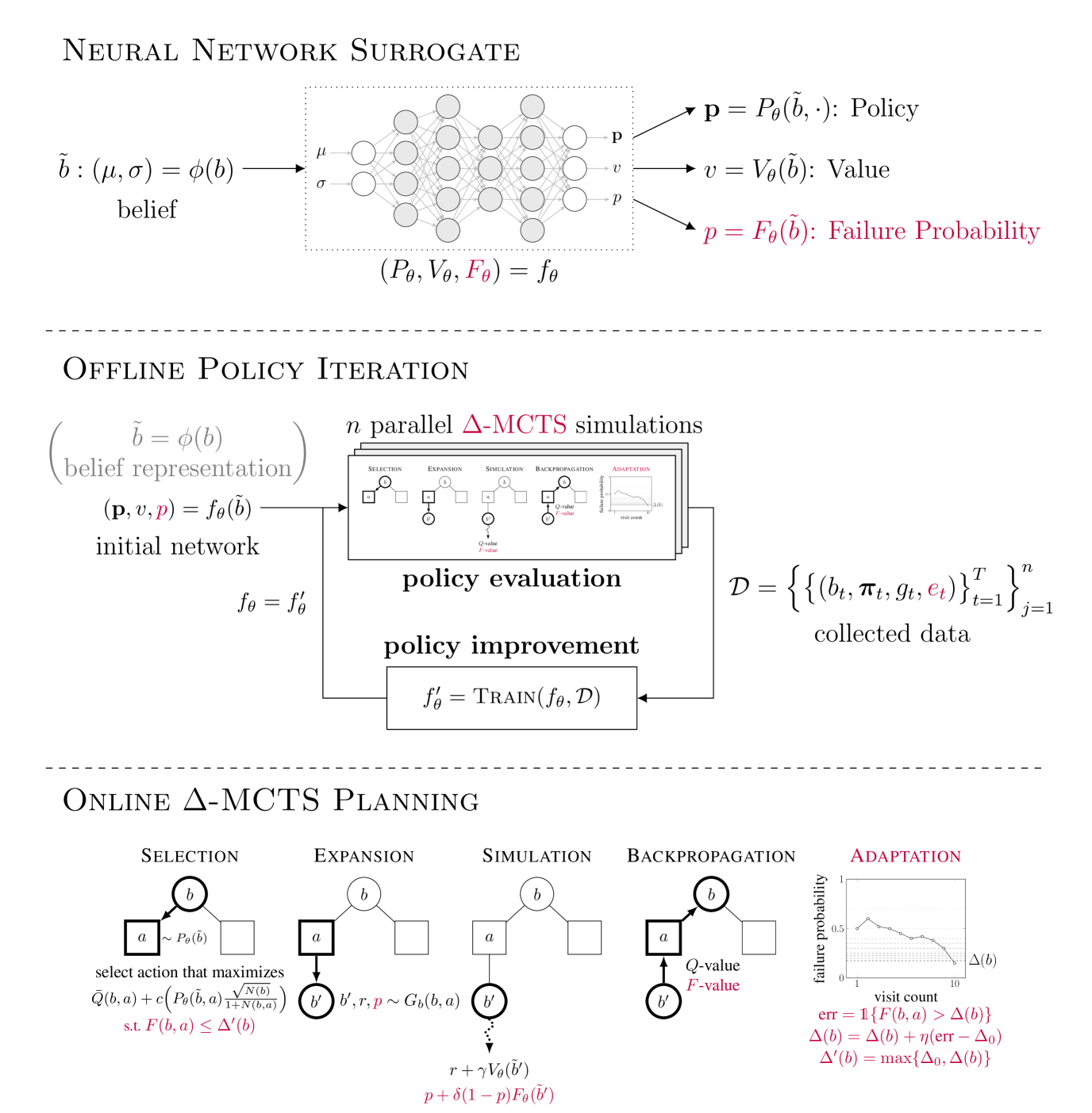
Abstract
To plan safely in uncertain environments, agents must balance utility with safety constraints. Safe planning problems can be modeled as a chance-constrained partially observable Markov decision process (CC-POMDP) and solutions often use expensive rollouts or heuristics to estimate the optimal value and action-selection policy. This work introduces the ConstrainedZero policy iteration algorithm that solves CC-POMDPs in belief space by learning neural network approximations of the optimal value and policy with an additional network head that estimates the failure probability given a belief. This failure probability guides safe action selection during online Monte Carlo tree search (MCTS). To avoid overemphasizing search based on the failure estimates, we introduce $Delta$-MCTS, which uses adaptive conformal inference to update the failure threshold during planning. The approach is tested on a safety-critical POMDP benchmark, an aircraft collision avoidance system, and the sustainability problem of safe CO$_2$ storage. Results show that by separating safety constraints from the objective we can achieve a target level of safety without optimizing the balance between rewards and costs.
Create account to get full access
Overview
- This paper introduces ConstrainedZero, a novel approach for chance-constrained Partially Observable Markov Decision Process (POMDP) planning.
- ConstrainedZero uses learned probabilistic failure surrogates and adaptive safety constraints to enable safe exploration and planning under uncertainty.
- The method is demonstrated on several challenging robotic navigation tasks, showing improved safety and performance compared to existing POMDP planning techniques.
Plain English Explanation
ConstrainedZero is a new way to plan the actions of an agent (like a robot) in an uncertain environment, where the agent needs to avoid risky or dangerous situations. Traditional planning methods can struggle with this kind of uncertainty, but ConstrainedZero uses a few key ideas to help the agent make safer and more effective decisions.
First, ConstrainedZero learns a "surrogate" model that can predict how likely the agent is to fail or encounter a hazard, even when the full details of the environment aren't known. This allows the agent to reason about risk and safety without having perfect information.
Second, ConstrainedZero uses "adaptive safety constraints" to adjust how cautious the agent needs to be based on the current situation. When the environment seems more dangerous, the agent will be more cautious; when it seems safer, the agent can be more aggressive in pursuing its goals.
By combining these two elements - the learned failure model and the adaptive safety constraints - ConstrainedZero is able to help agents plan their actions in a way that balances the need for safety with the desire to accomplish their objectives, even in highly uncertain environments. This could be useful for applications like autonomous navigation, spacecraft control, or other domains where safety is paramount.
Technical Explanation
ConstrainedZero addresses the challenge of planning under uncertainty in Partially Observable Markov Decision Processes (POMDPs). It does this by learning probabilistic "failure surrogates" - models that can predict the likelihood of dangerous or undesirable outcomes - and using these surrogates to adaptively adjust safety constraints during planning.
The key innovation is the use of these learned failure surrogates, which allow the planner to reason about risk and safety even when the full state of the environment is not observed. ConstrainedZero trains these surrogates using a combination of simulation data and real-world experience, enabling them to capture complex, nonlinear relationships between the agent's state/observations and the probability of failure.
These failure surrogates are then integrated into a chance-constrained POMDP planning framework, where the objective is to find a policy that maximizes rewards while ensuring the probability of constraint violation remains below a specified threshold. ConstrainedZero adaptively adjusts these safety constraints based on the current belief state, becoming more cautious when the risk of failure appears higher.
The authors demonstrate ConstrainedZero on several challenging robotic navigation tasks, including scenarios with dynamic obstacles and partial observability. Compared to standard POMDP planning approaches, ConstrainedZero is shown to achieve higher task completion rates while maintaining much lower probabilities of constraint violation, highlighting the benefits of its learned failure surrogates and adaptive safety constraints.
Critical Analysis
The ConstrainedZero approach presents a promising step towards safe and effective planning under uncertainty, but there are a few aspects that warrant further consideration:
-
Generalization: The paper primarily evaluates ConstrainedZero on relatively simple navigation tasks. It would be valuable to see how the method scales and generalizes to more complex, high-dimensional environments, such as those encountered in multi-constraint safe RL or versatile safe RL problems.
-
Safety Guarantees: While ConstrainedZero provides probabilistic safety constraints, it does not offer the same strong guarantees as some chance-constrained control approaches. Exploring ways to provide tighter safety bounds or formal verification could further strengthen the safety properties of the method.
-
Sample Efficiency: The paper does not provide a detailed analysis of the sample complexity or training time required for ConstrainedZero. Understanding the sample efficiency of the approach, especially the learning of the failure surrogates, would be valuable for assessing its practicality in real-world applications.
-
Explainability: The use of learned failure surrogates introduces some opacity into the planning process. Investigating ways to improve the interpretability and explainability of ConstrainedZero's decision-making could enhance user trust and acceptance.
Overall, ConstrainedZero represents an interesting and promising approach to safe POMDP planning, but further research and evaluation will be needed to fully understand its capabilities and limitations.
Conclusion
The ConstrainedZero method introduces a novel framework for chance-constrained POMDP planning that leverages learned probabilistic failure surrogates and adaptive safety constraints. By incorporating these elements, ConstrainedZero is able to achieve improved safety and performance compared to standard POMDP planning techniques, as demonstrated on several challenging robotic navigation tasks.
The use of learned failure surrogates is a key innovation, as it allows the planner to reason about risk and safety even when the full state of the environment is not observed. Combined with the adaptive safety constraints, this enables ConstrainedZero to balance the need for safety with the desire to accomplish the agent's objectives, even in highly uncertain settings.
While further research is needed to fully assess the scalability, safety guarantees, and explainability of ConstrainedZero, this work represents an important step towards safe and effective planning under uncertainty. As autonomous systems become more prevalent in a wide range of applications, methods like ConstrainedZero will be increasingly valuable for ensuring these systems can operate reliably and safely, even in complex and unpredictable environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
C-MCTS: Safe Planning with Monte Carlo Tree Search
Dinesh Parthasarathy, Georgios Kontes, Axel Plinge, Christopher Mutschler
0
0
The Constrained Markov Decision Process (CMDP) formulation allows to solve safety-critical decision making tasks that are subject to constraints. While CMDPs have been extensively studied in the Reinforcement Learning literature, little attention has been given to sampling-based planning algorithms such as MCTS for solving them. Previous approaches perform conservatively with respect to costs as they avoid constraint violations by using Monte Carlo cost estimates that suffer from high variance. We propose Constrained MCTS (C-MCTS), which estimates cost using a safety critic that is trained with Temporal Difference learning in an offline phase prior to agent deployment. The critic limits exploration by pruning unsafe trajectories within MCTS during deployment. C-MCTS satisfies cost constraints but operates closer to the constraint boundary, achieving higher rewards than previous work. As a nice byproduct, the planner is more efficient w.r.t. planning steps. Most importantly, under model mismatch between the planner and the real world, C-MCTS is less susceptible to cost violations than previous work.
6/7/2024
💬
A safe exploration approach to constrained Markov decision processes
Tingting Ni, Maryam Kamgarpour
0
0
We consider discounted infinite horizon constrained Markov decision processes (CMDPs) where the goal is to find an optimal policy that maximizes the expected cumulative reward subject to expected cumulative constraints. Motivated by the application of CMDPs in online learning of safety-critical systems, we focus on developing a model-free and simulator-free algorithm that ensures constraint satisfaction during learning. To this end, we develop an interior point approach based on the log barrier function of the CMDP. Under the commonly assumed conditions of Fisher non-degeneracy and bounded transfer error of the policy parameterization, we establish the theoretical properties of the algorithm. In particular, in contrast to existing CMDP approaches that ensure policy feasibility only upon convergence, our algorithm guarantees the feasibility of the policies during the learning process and converges to the $varepsilon$-optimal policy with a sample complexity of $tilde{mathcal{O}}(varepsilon^{-6})$. In comparison to the state-of-the-art policy gradient-based algorithm, C-NPG-PDA, our algorithm requires an additional $mathcal{O}(varepsilon^{-2})$ samples to ensure policy feasibility during learning with the same Fisher non-degenerate parameterization.
5/24/2024
👀
Recursively-Constrained Partially Observable Markov Decision Processes
Qi Heng Ho, Tyler Becker, Benjamin Kraske, Zakariya Laouar, Martin S. Feather, Federico Rossi, Morteza Lahijanian, Zachary N. Sunberg
0
0
Many sequential decision problems involve optimizing one objective function while imposing constraints on other objectives. Constrained Partially Observable Markov Decision Processes (C-POMDP) model this case with transition uncertainty and partial observability. In this work, we first show that C-POMDPs violate the optimal substructure property over successive decision steps and thus may exhibit behaviors that are undesirable for some (e.g., safety critical) applications. Additionally, online re-planning in C-POMDPs is often ineffective due to the inconsistency resulting from this violation. To address these drawbacks, we introduce the Recursively-Constrained POMDP (RC-POMDP), which imposes additional history-dependent cost constraints on the C-POMDP. We show that, unlike C-POMDPs, RC-POMDPs always have deterministic optimal policies and that optimal policies obey Bellman's principle of optimality. We also present a point-based dynamic programming algorithm for RC-POMDPs. Evaluations on benchmark problems demonstrate the efficacy of our algorithm and show that policies for RC-POMDPs produce more desirable behaviors than policies for C-POMDPs.
6/6/2024
CC-VPSTO: Chance-Constrained Via-Point-based Stochastic Trajectory Optimisation for Safe and Efficient Online Robot Motion Planning
Lara Brudermuller, Guillaume Berger, Julius Jankowski, Raunak Bhattacharyya, Raphael Jungers, Nick Hawes
0
0
Safety in the face of uncertainty is a key challenge in robotics. We introduce a real-time capable framework to generate safe and task-efficient robot motions for stochastic control problems. We frame this as a chance-constrained optimisation problem constraining the probability of the controlled system to violate a safety constraint to be below a set threshold. To estimate this probability we propose a Monte--Carlo approximation. We suggest several ways to construct the problem given a fixed number of uncertainty samples, such that it is a reliable over-approximation of the original problem, i.e. any solution to the sample-based problem adheres to the original chance-constraint with high confidence. To solve the resulting problem, we integrate it into our motion planner VP-STO and name the enhanced framework Chance-Constrained (CC)-VPSTO. The strengths of our approach lie in i) its generality, without assumptions on the underlying uncertainty distribution, system dynamics, cost function, or the form of inequality constraints; and ii) its applicability to MPC-settings. We demonstrate the validity and efficiency of our approach on both simulation and real-world robot experiments.
4/10/2024