Wisdom of Instruction-Tuned Language Model Crowds. Exploring Model Label Variation
2307.12973
0
0
💬
Abstract
Large Language Models (LLMs) exhibit remarkable text classification capabilities, excelling in zero- and few-shot learning (ZSL and FSL) scenarios. However, since they are trained on different datasets, performance varies widely across tasks between those models. Recent studies emphasize the importance of considering human label variation in data annotation. However, how this human label variation also applies to LLMs remains unexplored. Given this likely model specialization, we ask: Do aggregate LLM labels improve over individual models (as for human annotators)? We evaluate four recent instruction-tuned LLMs as annotators on five subjective tasks across four languages. We use ZSL and FSL setups and label aggregation from human annotation. Aggregations are indeed substantially better than any individual model, benefiting from specialization in diverse tasks or languages. Surprisingly, FSL does not surpass ZSL, as it depends on the quality of the selected examples. However, there seems to be no good information-theoretical strategy to select those. We find that no LLM method rivals even simple supervised models. We also discuss the tradeoffs in accuracy, cost, and moral/ethical considerations between LLM and human annotation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large Language Models (LLMs) excel at text classification, even in zero-shot and few-shot learning scenarios.
- However, their performance varies widely across tasks and datasets due to their specialized training.
- Recent studies highlight the importance of considering human label variation in data annotation.
- This paper explores whether aggregating LLM labels can improve performance compared to individual models, similar to how aggregating human annotations can improve results.
Plain English Explanation
Large Language Models (LLMs) are powerful AI systems that can perform remarkable text classification tasks, even when they don't have much training data to work with. This is known as zero-shot and few-shot learning. However, since these models are trained on different datasets, their performance can vary a lot depending on the specific task or language.
Recent research has shown that it's important to consider the natural variation in how humans label or annotate data. This got the authors of this paper wondering: could aggregating the labels from multiple LLMs also improve performance, just like aggregating labels from human annotators does?
To find out, the researchers evaluated four recent LLMs as "annotators" on several subjective tasks across four different languages. They used both zero-shot and few-shot learning setups, and compared the results to aggregating the LLM labels versus relying on individual models.
Technical Explanation
The researchers evaluated four recent instruction-tuned LLMs as annotators on five subjective tasks across four languages. They used both zero-shot and few-shot learning setups, and compared the results of aggregating the LLM labels to relying on individual models.
The results showed that the aggregated LLM labels were substantially better than any individual model. This suggests that the models can benefit from specialization in diverse tasks or languages, similar to how aggregating human annotations can improve performance.
Surprisingly, the few-shot learning did not outperform the zero-shot learning, as it depended on the quality of the selected examples. However, the researchers found no good information-theoretical strategy to reliably select those examples.
Overall, the LLM methods did not rival even simple supervised models. The paper also discusses the tradeoffs in accuracy, cost, and moral/ethical considerations between using LLMs versus human annotation for these tasks.
Critical Analysis
The paper acknowledges several caveats and limitations in its approach. For example, the few-shot learning performance depended heavily on the quality of the selected examples, but the researchers did not find a good way to reliably choose those examples.
Additionally, while the aggregated LLM labels outperformed individual models, they still did not reach the level of simple supervised models. This suggests that LLMs, even when aggregated, may not be a complete replacement for human annotation, at least for these types of subjective tasks.
The paper also raises important considerations around the moral and ethical implications of using LLMs for annotation tasks. As these models can exhibit biases and inconsistencies, blindly relying on them could lead to problematic outcomes.
Further research is needed to better understand the strengths, limitations, and appropriate use cases for LLMs in annotation tasks, especially as they relate to complex, subjective domains. Continued critical analysis of these models and their applications will be crucial as the technology continues to evolve.
Conclusion
This paper explored the potential for aggregating labels from multiple Large Language Models (LLMs) to improve performance on subjective text classification tasks, similar to how aggregating human annotations can boost results.
The key findings are that the aggregated LLM labels did substantially outperform individual models, suggesting that the models can benefit from specialization across diverse tasks and languages. However, the LLM methods still did not rival even simple supervised models, and the paper raises important considerations around the moral and ethical implications of using these models for annotation tasks.
Overall, this research highlights both the remarkable capabilities of LLMs as well as the need for continued critical analysis and responsible development of these powerful AI systems, especially when applying them to complex, subjective domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
0
0
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
5/3/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024
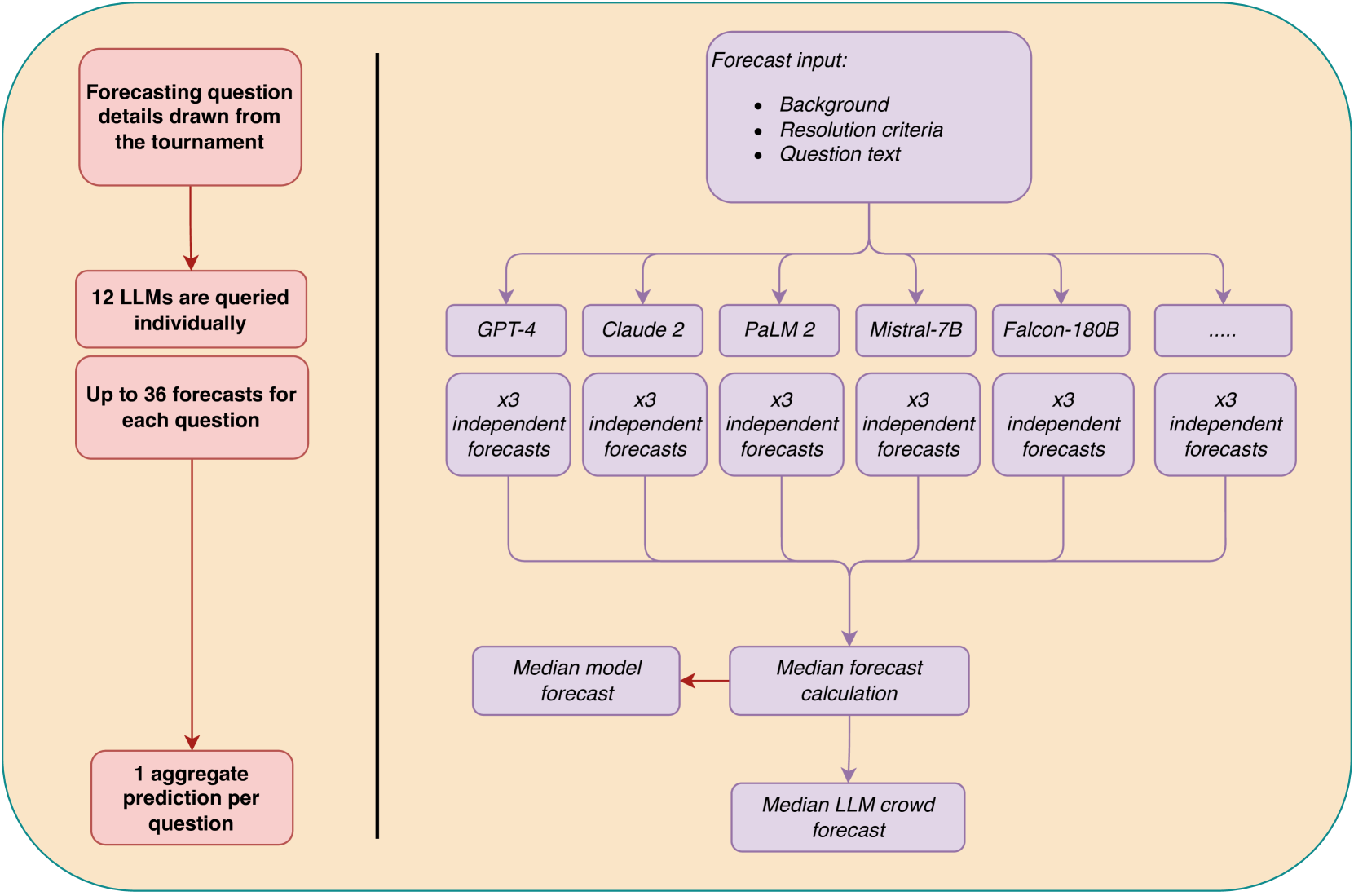
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy
Philipp Schoenegger, Indre Tuminauskaite, Peter S. Park, Philip E. Tetlock
0
0
Human forecasting accuracy in practice relies on the 'wisdom of the crowd' effect, in which predictions about future events are significantly improved by aggregating across a crowd of individual forecasters. Past work on the forecasting ability of large language models (LLMs) suggests that frontier LLMs, as individual forecasters, underperform compared to the gold standard of a human crowd forecasting tournament aggregate. In Study 1, we expand this research by using an LLM ensemble approach consisting of a crowd of twelve LLMs. We compare the aggregated LLM predictions on 31 binary questions to that of a crowd of 925 human forecasters from a three-month forecasting tournament. Our preregistered main analysis shows that the LLM crowd outperforms a simple no-information benchmark and is not statistically different from the human crowd. In exploratory analyses, we find that these two approaches are equivalent with respect to medium-effect-size equivalence bounds. We also observe an acquiescence effect, with mean model predictions being significantly above 50%, despite an almost even split of positive and negative resolutions. Moreover, in Study 2, we test whether LLM predictions (of GPT-4 and Claude 2) can be improved by drawing on human cognitive output. We find that both models' forecasting accuracy benefits from exposure to the median human prediction as information, improving accuracy by between 17% and 28%: though this leads to less accurate predictions than simply averaging human and machine forecasts. Our results suggest that LLMs can achieve forecasting accuracy rivaling that of human crowd forecasting tournaments: via the simple, practically applicable method of forecast aggregation. This replicates the 'wisdom of the crowd' effect for LLMs, and opens up their use for a variety of applications throughout society.
5/7/2024
💬
A Zero-shot and Few-shot Study of Instruction-Finetuned Large Language Models Applied to Clinical and Biomedical Tasks
Yanis Labrak, Mickael Rouvier, Richard Dufour
0
0
We evaluate four state-of-the-art instruction-tuned large language models (LLMs) -- ChatGPT, Flan-T5 UL2, Tk-Instruct, and Alpaca -- on a set of 13 real-world clinical and biomedical natural language processing (NLP) tasks in English, such as named-entity recognition (NER), question-answering (QA), relation extraction (RE), etc. Our overall results demonstrate that the evaluated LLMs begin to approach performance of state-of-the-art models in zero- and few-shot scenarios for most tasks, and particularly well for the QA task, even though they have never seen examples from these tasks before. However, we observed that the classification and RE tasks perform below what can be achieved with a specifically trained model for the medical field, such as PubMedBERT. Finally, we noted that no LLM outperforms all the others on all the studied tasks, with some models being better suited for certain tasks than others.
4/30/2024