WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models

0
📈
Sign in to get full access
Overview
- Large language models (LLMs) need to be regularly updated with new knowledge to keep up with the constantly changing world
- Updating the knowledge in LLMs, known as "model editing," is a fundamental challenge
- This paper explores the tradeoffs between reliability, generalization, and locality when editing the knowledge in LLMs
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text on a wide range of topics. However, as the world changes, the knowledge in these models can become outdated or even inaccurate. Updating the knowledge in LLMs, a process known as "model editing," is crucial to keep them relevant and reliable.
The paper explores a key challenge in model editing: where should the updated knowledge be stored in the LLM's memory? The researchers found that there is an "impossible triangle" - you can only achieve two out of the three desirable properties: reliability (the model behaves consistently), generalization (the model can apply the new knowledge to novel situations), and locality (the new knowledge can be easily identified and updated).
For example, directly editing the model's core parameters (its "long-term memory") can lead to conflicts with previous knowledge, resulting in poor reliability and locality. On the other hand, storing the new knowledge in a separate "working memory" through retrieval-based approaches can make it difficult for the model to generalize the new knowledge.
To overcome this challenge, the researchers propose a new approach called WISE (Weighted Interleaved Side Editing). WISE uses a dual parametric memory scheme, where the main memory stores the original, pre-trained knowledge, and a side memory stores the edited knowledge. A "router" module decides which memory to use when processing a given input. WISE also uses a "knowledge-sharding" mechanism to organize different sets of edits into distinct parameter subspaces, allowing them to be merged without conflicts.
The researchers show that WISE can outperform previous model editing methods and overcome the "impossible triangle" in various tasks, such as question answering, hallucination (generating false information), and out-of-distribution settings, across different LLM architectures like GPT, LLaMA, and Mistral.
Technical Explanation
The paper explores the fundamental challenge of where to store the updated knowledge when editing large language models (LLMs) in a lifelong learning setting. The researchers found that there is an "impossible triangle" where the three desirable properties of reliability, generalization, and locality cannot be achieved simultaneously.
For long-term memory (direct model parameters), directly editing the parameters can lead to conflicts with irrelevant pre-trained knowledge or previous edits, resulting in poor reliability and locality. For working memory (non-parametric knowledge of neural network activations/representations by retrieval), retrieval-based activations can hardly make the model understand the edits and generalize, leading to poor generalization.
To address this challenge, the researchers propose WISE (Weighted Interleaved Side Editing), a dual parametric memory scheme that consists of a main memory for the pre-trained knowledge and a side memory for the edited knowledge. WISE only edits the knowledge in the side memory and trains a router to decide which memory to use when processing a given input.
For continual editing, WISE also devises a "knowledge-sharding" mechanism, where different sets of edits reside in distinct parameter subspaces and are subsequently merged into a shared memory without conflicts.
The researchers extensively evaluate WISE on various tasks, including question answering, hallucination, and out-of-distribution settings, across different LLM architectures such as GPT, LLaMA, and Mistral. Their results show that WISE can outperform previous model editing methods and overcome the "impossible triangle" in lifelong model editing.
Critical Analysis
The paper presents a thorough analysis of the challenges in editing the knowledge of large language models (LLMs) and proposes a novel approach, WISE, to address these challenges. The researchers have identified an important and relevant problem in the field of LLM development and editing, and their proposed solution appears to be a promising approach.
One potential limitation of the research is the specific tasks and datasets used in the evaluation. While the researchers have tested WISE across a range of tasks and LLM architectures, it would be valuable to see how the approach performs on an even wider range of applications and datasets, especially in real-world scenarios.
Additionally, the paper does not provide a detailed discussion of the computational and memory overhead associated with the WISE approach. As LLMs continue to grow in size and complexity, the scalability and efficiency of model editing methods will become increasingly important.
Another area for further research could be the impact of the WISE approach on the interpretability and transparency of LLMs. By separating the pre-trained and edited knowledge, WISE may provide opportunities to better understand and explain the model's decision-making process.
Overall, the paper presents a well-designed and thorough investigation of the challenges in lifelong model editing, and the WISE approach appears to be a significant contribution to the field. Researchers and practitioners in the LLM development space would likely find this work highly relevant and informative.
Conclusion
This paper addresses a fundamental challenge in updating the knowledge of large language models (LLMs) through a process known as "model editing." The researchers found that there is an "impossible triangle" where the three desirable properties of reliability, generalization, and locality cannot be achieved simultaneously when editing the knowledge in LLMs.
To overcome this challenge, the paper proposes a novel approach called WISE (Weighted Interleaved Side Editing), which uses a dual parametric memory scheme and a knowledge-sharding mechanism to enable effective and conflict-free lifelong model editing. The researchers demonstrate the effectiveness of WISE across a range of tasks and LLM architectures, showcasing its potential to significantly advance the field of LLM development and editing.
The insights and techniques presented in this paper could have far-reaching implications for the continued improvement and deployment of large language models, which are becoming increasingly important in a wide variety of applications. As the world continues to evolve, the ability to efficiently and reliably update the knowledge in these models will be crucial for maintaining their relevance and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models
Peng Wang, Zexi Li, Ningyu Zhang, Ziwen Xu, Yunzhi Yao, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
Large language models (LLMs) need knowledge updates to meet the ever-growing world facts and correct the hallucinated responses, facilitating the methods of lifelong model editing. Where the updated knowledge resides in memories is a fundamental question for model editing. In this paper, we find that editing either long-term memory (direct model parameters) or working memory (non-parametric knowledge of neural network activations/representations by retrieval) will result in an impossible triangle -- reliability, generalization, and locality can not be realized together in the lifelong editing settings. For long-term memory, directly editing the parameters will cause conflicts with irrelevant pretrained knowledge or previous edits (poor reliability and locality). For working memory, retrieval-based activations can hardly make the model understand the edits and generalize (poor generalization). Therefore, we propose WISE to bridge the gap between memories. In WISE, we design a dual parametric memory scheme, which consists of the main memory for the pretrained knowledge and a side memory for the edited knowledge. We only edit the knowledge in the side memory and train a router to decide which memory to go through when given a query. For continual editing, we devise a knowledge-sharding mechanism where different sets of edits reside in distinct subspaces of parameters, and are subsequently merged into a shared memory without conflicts. Extensive experiments show that WISE can outperform previous model editing methods and overcome the impossible triangle under lifelong model editing of question answering, hallucination, and out-of-distribution settings across trending LLM architectures, e.g., GPT, LLaMA, and Mistral. Code will be released at https://github.com/zjunlp/EasyEdit.
Read more5/24/2024

0
WilKE: Wise-Layer Knowledge Editor for Lifelong Knowledge Editing
Chenhui Hu, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
Knowledge editing aims to rectify inaccuracies in large language models (LLMs) without costly retraining for outdated or erroneous knowledge. However, current knowledge editing methods primarily focus on single editing, failing to meet the requirements for lifelong editing. This study reveals a performance degradation encountered by knowledge editing in lifelong editing, characterized by toxicity buildup and toxicity flash, with the primary cause identified as pattern unmatch. We introduce a knowledge editing approach named Wise-Layer Knowledge Editor (WilKE), which selects editing layer based on the pattern matching degree of editing knowledge across different layers in language models. Experimental results demonstrate that, in lifelong editing, WilKE exhibits an average improvement of 46.2% and 67.8% on editing GPT2-XL and GPT-J relative to state-of-the-art knowledge editing methods.
Read more6/6/2024
🛠️
0
Lifelong Knowledge Editing for LLMs with Retrieval-Augmented Continuous Prompt Learning
Qizhou Chen, Taolin Zhang, Xiaofeng He, Dongyang Li, Chengyu Wang, Longtao Huang, Hui Xue
Model editing aims to correct outdated or erroneous knowledge in large language models (LLMs) without the need for costly retraining. Lifelong model editing is the most challenging task that caters to the continuous editing requirements of LLMs. Prior works primarily focus on single or batch editing; nevertheless, these methods fall short in lifelong editing scenarios due to catastrophic knowledge forgetting and the degradation of model performance. Although retrieval-based methods alleviate these issues, they are impeded by slow and cumbersome processes of integrating the retrieved knowledge into the model. In this work, we introduce RECIPE, a RetriEval-augmented ContInuous Prompt lEarning method, to boost editing efficacy and inference efficiency in lifelong learning. RECIPE first converts knowledge statements into short and informative continuous prompts, prefixed to the LLM's input query embedding, to efficiently refine the response grounded on the knowledge. It further integrates the Knowledge Sentinel (KS) that acts as an intermediary to calculate a dynamic threshold, determining whether the retrieval repository contains relevant knowledge. Our retriever and prompt encoder are jointly trained to achieve editing properties, i.e., reliability, generality, and locality. In our experiments, RECIPE is assessed extensively across multiple LLMs and editing datasets, where it achieves superior editing performance. RECIPE also demonstrates its capability to maintain the overall performance of LLMs alongside showcasing fast editing and inference speed.
Read more5/9/2024
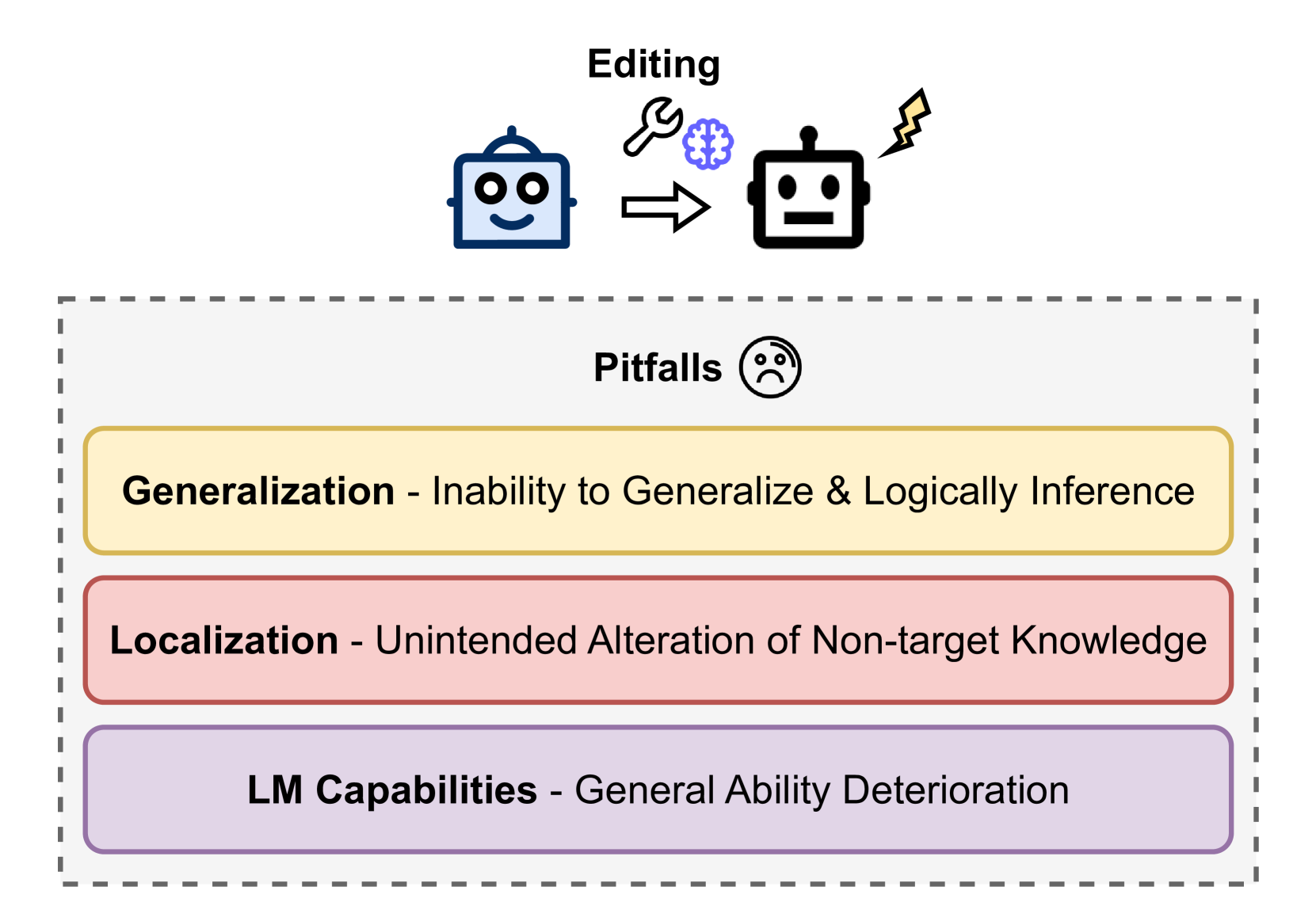
0
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, Yun-Nung Chen
Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
Read more6/4/2024