WM-MoE: Weather-aware Multi-scale Mixture-of-Experts for Blind Adverse Weather Removal

0
📉
Sign in to get full access
Overview
- The paper proposes a new method called Weather-aware Multi-scale Mixture-of-Experts (WM-MoE) for blind adverse weather removal.
- Blind adverse weather removal refers to the challenge of removing various types of weather effects (e.g., rain, snow, haze) from images when the specific weather conditions are unknown.
- The WM-MoE method uses a Transformer-based architecture with two key components: a Weather-Aware Router (WEAR) and Multi-Scale Experts (MSE).
- WEAR assigns different expert networks to process image tokens based on their content and weather features, allowing the model to handle a mixture of weather conditions.
- MSE leverages multi-scale features to enhance the model's ability to handle diverse weather types and intensities.
- The proposed method achieves state-of-the-art performance on blind adverse weather removal tasks and also shows benefits for downstream computer vision applications like segmentation.
Plain English Explanation
The paper tackles the challenge of removing adverse weather effects from images when the specific weather conditions are unknown. This is a common problem in autonomous driving scenarios, where the type, intensity, and combination of weather effects can vary significantly.
Traditionally, researchers have treated tasks like deraining, desnowing, and dehazing as separate problems. However, this approach struggles to handle the complex real-world situations where multiple weather effects are present.
To address this, the researchers propose a new method called WM-MoE, which stands for Weather-aware Multi-scale Mixture-of-Experts. The key idea is to use a Transformer-based architecture with two main components:
-
Weather-Aware Router (WEAR): This module assigns different expert networks to process different parts of the image, based on the content and weather features. This allows the model to handle a mixture of weather conditions.
-
Multi-Scale Experts (MSE): Since processing different weather types requires different receptive fields, this component leverages multi-scale features to enhance the model's spatial relationship modeling capabilities. This helps the model handle diverse weather types and intensities more effectively.
The researchers also propose a contrastive learning technique called Weather Guidance Fine-grained Contrastive Learning (WGF-CL) to learn discriminative weather features, further improving the model's performance.
The proposed WM-MoE method achieves state-of-the-art results on blind adverse weather removal tasks and also shows benefits for downstream computer vision applications like segmentation. This research is an important step towards building robust and generalized models that can handle the complex weather conditions encountered in real-world scenarios.
Technical Explanation
The paper introduces a novel method called Weather-aware Multi-scale Mixture-of-Experts (WM-MoE) for the task of blind adverse weather removal. The key components of the WM-MoE architecture are:
-
Weather-Aware Router (WEAR): This module assigns different expert networks to process different parts of the input image based on its content and weather features. This allows the model to handle a mixture of weather conditions, as opposed to treating each weather type as a separate task.
-
Multi-Scale Experts (MSE): Since processing different weather types requires different receptive fields, this component leverages multi-scale features to enhance the model's spatial relationship modeling capabilities. This helps the model handle diverse weather types and intensities more effectively.
To learn discriminative weather features, the researchers propose a Weather Guidance Fine-grained Contrastive Learning (WGF-CL) technique. WGF-CL utilizes weather cluster information to guide the assignment of positive and negative samples for each image token during contrastive learning.
The researchers evaluate their WM-MoE method on two public datasets and their own dataset for blind adverse weather removal tasks. The results show that WM-MoE outperforms existing state-of-the-art methods. The researchers also demonstrate the benefits of their method for downstream computer vision tasks like semantic segmentation.
Critical Analysis
The paper presents a well-designed and comprehensive solution for the blind adverse weather removal problem, which is an important challenge in real-world computer vision applications like autonomous driving. The key strengths of the proposed WM-MoE method include its ability to handle a mixture of weather conditions, the use of multi-scale features to improve spatial modeling, and the novel WGF-CL technique for learning discriminative weather features.
However, the paper does not provide a detailed analysis of the computational complexity and inference time of the WM-MoE model, which would be important considerations for its practical deployment. Additionally, the paper could have explored the generalization capabilities of the method by evaluating its performance on a wider range of weather conditions and datasets.
It would also be interesting to see how the WM-MoE method compares to other Transformer-based approaches for blind adverse weather removal, as the paper mainly focuses on comparing against more traditional CNN-based models. Exploring the potential synergies between the WM-MoE architecture and other advanced Transformer techniques could lead to further performance improvements.
Overall, the paper presents a promising solution to a complex problem and provides a solid foundation for future research in this area.
Conclusion
The paper introduces a novel method called Weather-aware Multi-scale Mixture-of-Experts (WM-MoE) for the task of blind adverse weather removal. The key innovations include the Weather-Aware Router (WEAR) module, which assigns experts to handle different weather conditions, and the Multi-Scale Experts (MSE) component, which leverages multi-scale features to improve spatial modeling for diverse weather types and intensities.
The proposed WM-MoE method achieves state-of-the-art performance on blind adverse weather removal tasks and also demonstrates benefits for downstream computer vision applications like semantic segmentation. This research is an important step towards building robust and generalized models that can handle the complex weather conditions encountered in real-world scenarios, particularly in the context of autonomous driving and other outdoor vision-based systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
WM-MoE: Weather-aware Multi-scale Mixture-of-Experts for Blind Adverse Weather Removal
Yulin Luo, Rui Zhao, Xiaobao Wei, Jinwei Chen, Yijie Lu, Shenghao Xie, Tianyu Wang, Ruiqin Xiong, Ming Lu, Shanghang Zhang
Adverse weather removal tasks like deraining, desnowing, and dehazing are usually treated as separate tasks. However, in practical autonomous driving scenarios, the type, intensity,and mixing degree of weather are unknown, so handling each task separately cannot deal with the complex practical scenarios. In this paper, we study the blind adverse weather removal problem. Mixture-of-Experts (MoE) is a popular model that adopts a learnable gate to route the input to different expert networks. The principle of MoE involves using adaptive networks to process different types of unknown inputs. Therefore, MoE has great potential for blind adverse weather removal. However, the original MoE module is inadequate for coupled multiple weather types and fails to utilize multi-scale features for better performance. To this end, we propose a method called Weather-aware Multi-scale MoE (WM-MoE) based on Transformer for blind weather removal. WM-MoE includes two key designs: WEather-Aware Router (WEAR) and Multi-Scale Experts (MSE). WEAR assigns experts for each image token based on decoupled content and weather features, which enhances the model's capability to process multiple adverse weathers. To obtain discriminative weather features from images, we propose Weather Guidance Fine-grained Contrastive Learning (WGF-CL), which utilizes weather cluster information to guide the assignment of positive and negative samples for each image token. Since processing different weather types requires different receptive fields, MSE leverages multi-scale features to enhance the spatial relationship modeling capability, facilitating the high-quality restoration of diverse weather types and intensities. Our method achieves state-of-the-art performance in blind adverse weather removal on two public datasets and our dataset. We also demonstrate the advantage of our method on downstream segmentation tasks.
Read more4/5/2024
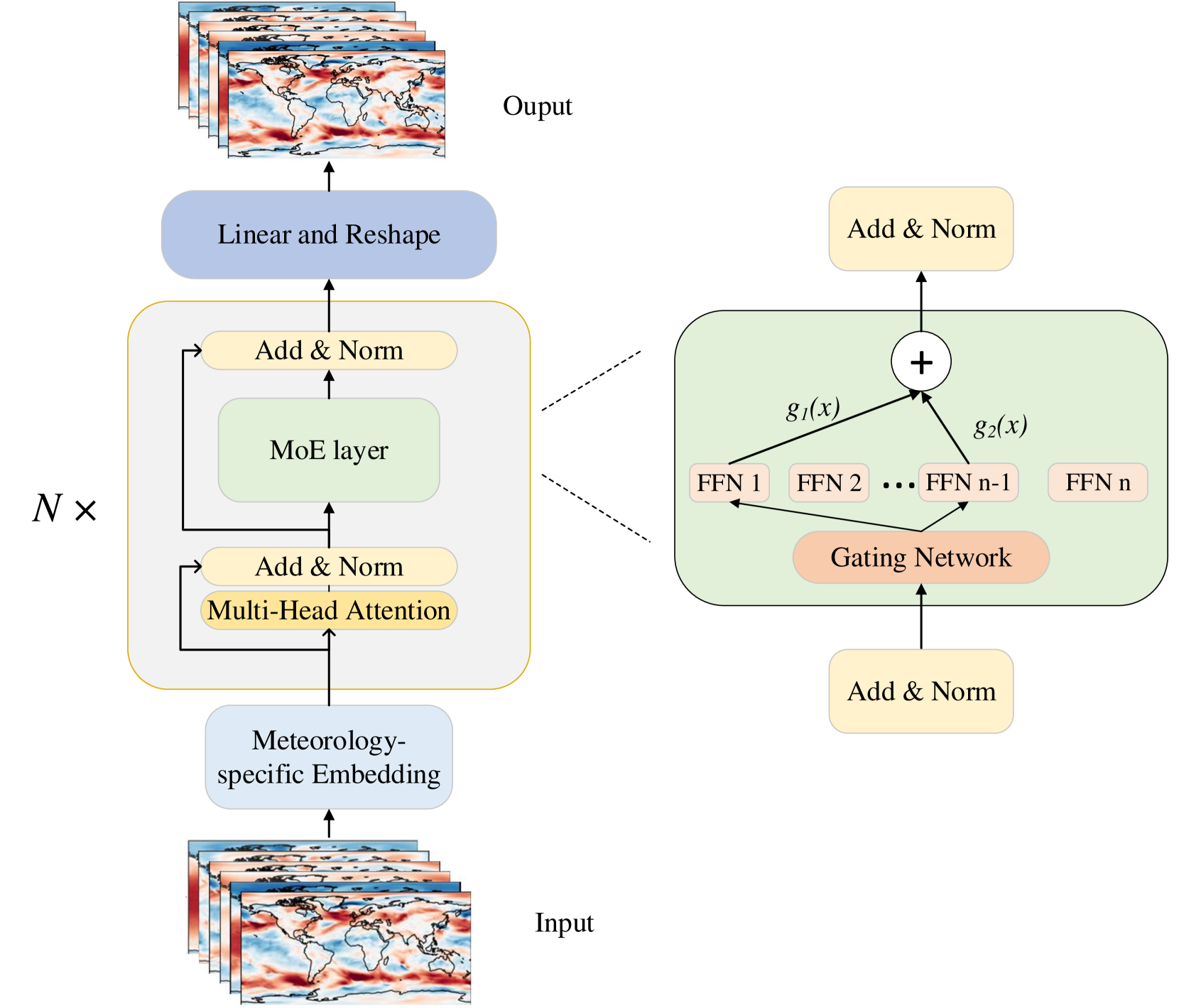
0
EWMoE: An effective model for global weather forecasting with mixture-of-experts
Lihao Gan, Xin Man, Chenghong Zhang, Jie Shao
Weather forecasting is a crucial task for meteorologic research, with direct social and economic impacts. Recently, data-driven weather forecasting models based on deep learning have shown great potential, achieving superior performance compared with traditional numerical weather prediction methods. However, these models often require massive training data and computational resources. In this paper, we propose EWMoE, an effective model for accurate global weather forecasting, which requires significantly less training data and computational resources. Our model incorporates three key components to enhance prediction accuracy: 3D absolute position embedding, a core Mixture-of-Experts (MoE) layer, and two specific loss functions. We conduct our evaluation on the ERA5 dataset using only two years of training data. Extensive experiments demonstrate that EWMoE outperforms current models such as FourCastNet and ClimaX at all forecast time, achieving competitive performance compared with the state-of-the-art models Pangu-Weather and GraphCast in evaluation metrics such as Anomaly Correlation Coefficient (ACC) and Root Mean Square Error (RMSE). Additionally, ablation studies indicate that applying the MoE architecture to weather forecasting offers significant advantages in improving accuracy and resource efficiency. Code is available at https://github.com/Tomoyi/EWMoE.
Read more8/26/2024

0
Layerwise Recurrent Router for Mixture-of-Experts
Zihan Qiu, Zeyu Huang, Shuang Cheng, Yizhi Zhou, Zili Wang, Ivan Titov, Jie Fu
The scaling of large language models (LLMs) has revolutionized their capabilities in various tasks, yet this growth must be matched with efficient computational strategies. The Mixture-of-Experts (MoE) architecture stands out for its ability to scale model size without significantly increasing training costs. Despite their advantages, current MoE models often display parameter inefficiency. For instance, a pre-trained MoE-based LLM with 52 billion parameters might perform comparably to a standard model with 6.7 billion parameters. Being a crucial part of MoE, current routers in different layers independently assign tokens without leveraging historical routing information, potentially leading to suboptimal token-expert combinations and the parameter inefficiency problem. To alleviate this issue, we introduce the Layerwise Recurrent Router for Mixture-of-Experts (RMoE). RMoE leverages a Gated Recurrent Unit (GRU) to establish dependencies between routing decisions across consecutive layers. Such layerwise recurrence can be efficiently parallelly computed for input tokens and introduces negotiable costs. Our extensive empirical evaluations demonstrate that RMoE-based language models consistently outperform a spectrum of baseline models. Furthermore, RMoE integrates a novel computation stage orthogonal to existing methods, allowing seamless compatibility with other MoE architectures. Our analyses attribute RMoE's gains to its effective cross-layer information sharing, which also improves expert selection and diversity. Our code is at https://github.com/qiuzh20/RMoE
Read more8/14/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024