Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts
2312.00968
0
0
🔍
Abstract
Large multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use. We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance.
Create account to get full access
Overview
- Large multi-modal models (LMMs) are powerful AI systems that can perform a wide range of tasks, but they often struggle when tuned for many tasks.
- Recent research suggests that Mixture of Experts (MoE) architectures can help with this by allowing different specialized components to handle different tasks.
- However, for very large LMMs, the cost of replicating and storing all the expert models becomes prohibitive.
Plain English Explanation
Imagine a super-smart assistant that can help you with all kinds of tasks - writing, analysis, even creative projects. This is what large multi-modal models (LMMs) are like. They are incredibly capable and versatile. But sometimes, when you try to train them to do too many different things, their performance can start to suffer.
The researchers behind this paper had an idea to help with this problem. They thought, what if we could create a system where different specialized "experts" could handle different tasks, instead of trying to make the whole model be good at everything? This is similar to how a team of people with different skills might work together to tackle a complex problem.
However, the challenge is that for the biggest LMMs, which have hundreds of billions of parameters, the cost of storing and using all these different expert models becomes very high. The researchers' solution, called Omni-SMoLA, is to use a "soft" mixing approach, where the main model provides the backbone, and the different expert models just learn small tweaks or additions to handle the specialized tasks. This way, they can get the benefits of the expert system without the huge cost.
Technical Explanation
Omni-SMoLA is an architecture that uses a Soft Mixture of Experts (SMoE) approach to combine many multimodal low-rank expert models with a large generalist LMM. The key idea is that the large LMM provides a strong foundational backbone, while the different lightweight expert models learn residual, specialized knowledge - either for specific modalities (e.g. vision, language) or in a multimodal way.
The researchers ran extensive experiments to evaluate Omni-SMoLA's performance on a range of generative vision-and-language tasks. They found that the SMoE approach helped improve the overall generalist performance, often matching or exceeding the results of single specialized LMM baselines. Omni-SMoLA also achieved new state-of-the-art results for specialist performance on these tasks.
Critical Analysis
The paper provides a compelling solution to the challenge of scaling MoE approaches to very large LMMs. By using a "soft" mixing approach, Omni-SMoLA is able to capture the benefits of expert specialization without the prohibitive cost of replicating and storing full expert models.
However, the paper does not deeply explore the limitations or potential downsides of this approach. For example, it's not clear how the performance of Omni-SMoLA scales as the number of tasks or experts increases. There may also be challenges in ensuring coherent and consistent behavior across the different expert models. Further research would be needed to fully understand the tradeoffs and edge cases of this architecture.
Additionally, the experiments in the paper are focused on generative vision-and-language tasks. It would be valuable to see how Omni-SMoLA performs on a wider range of multimodal tasks, including more open-ended or interactive scenarios.
Conclusion
The Omni-SMoLA architecture presented in this paper offers a promising solution to the challenge of scaling Mixture of Experts approaches to very large multi-modal models. By using a "soft" mixing approach, it allows large generalist models to benefit from specialized expert knowledge without the high cost of replicating full expert models.
The researchers' extensive experiments demonstrate that Omni-SMoLA can achieve state-of-the-art performance on a range of generative vision-and-language tasks, both in terms of overall generalist capability and specialized expert performance. This suggests that this approach could be valuable for building highly capable and versatile AI systems that can adapt to a wide variety of use cases.
As the field of large multi-modal AI continues to advance, solutions like Omni-SMoLA will likely play an important role in helping to overcome the limitations of one-size-fits-all models and unlock the full potential of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
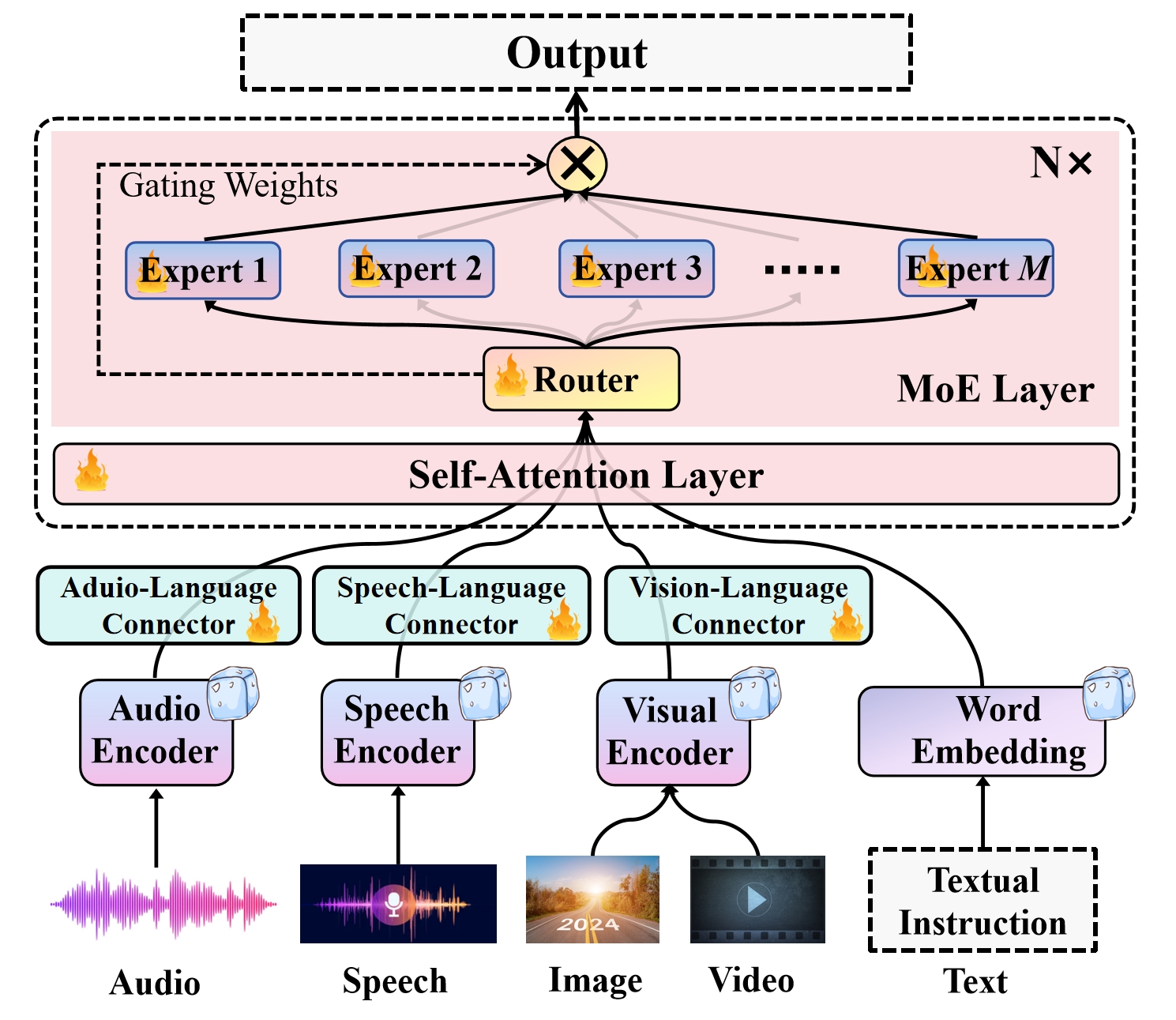
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
0
0
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
5/21/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024

Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Yijiang Liu, Rongyu Zhang, Huanrui Yang, Kurt Keutzer, Yuan Du, Li Du, Shanghang Zhang
0
0
Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
4/16/2024
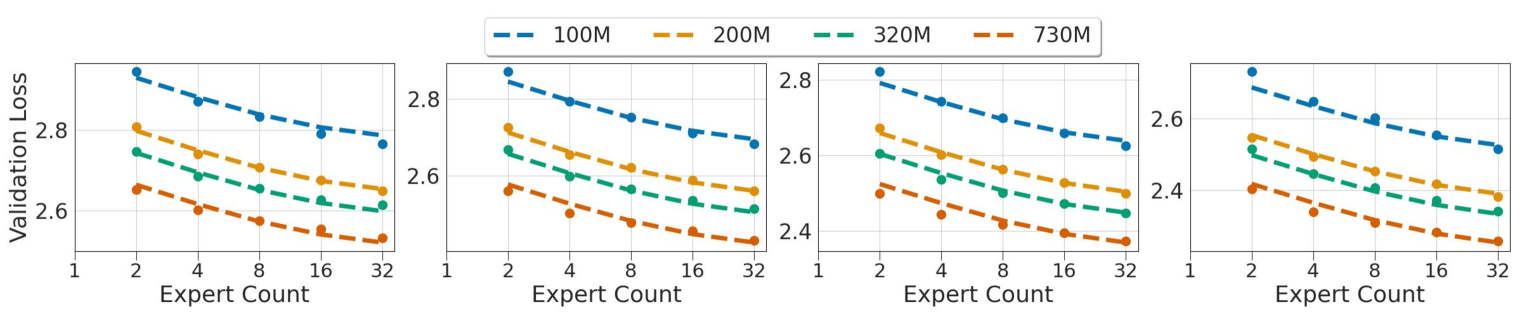
Toward Inference-optimal Mixture-of-Expert Large Language Models
Longfei Yun, Yonghao Zhuang, Yao Fu, Eric P Xing, Hao Zhang
0
0
Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
4/4/2024