X-PARADE: Cross-Lingual Textual Entailment and Information Divergence across Paragraphs
2309.08873
0
0
📈
Abstract
Understanding when two pieces of text convey the same information is a goal touching many subproblems in NLP, including textual entailment and fact-checking. This problem becomes more complex when those two pieces of text are in different languages. Here, we introduce X-PARADE (Cross-lingual Paragraph-level Analysis of Divergences and Entailments), the first cross-lingual dataset of paragraph-level information divergences. Annotators label a paragraph in a target language at the span level and evaluate it with respect to a corresponding paragraph in a source language, indicating whether a given piece of information is the same, new, or new but can be inferred. This last notion establishes a link with cross-language NLI. Aligned paragraphs are sourced from Wikipedia pages in different languages, reflecting real information divergences observed in the wild. Armed with our dataset, we investigate a diverse set of approaches for this problem, including token alignment from machine translation, textual entailment methods that localize their decisions, and prompting LLMs. Our results show that these methods vary in their capability to handle inferable information, but they all fall short of human performance.
Create account to get full access
Overview
- This paper introduces X-PARADE, the first cross-lingual dataset of paragraph-level information divergences.
- Annotators label a paragraph in a target language, evaluating it with respect to a corresponding paragraph in a source language to indicate whether information is the same, new, or new but can be inferred.
- The authors investigate various approaches for this problem, including token alignment from machine translation, textual entailment methods, and prompting large language models (LLMs).
- The results show that these methods vary in their capability to handle inferable information, but they all fall short of human performance.
Plain English Explanation
Comparing the information conveyed by two pieces of text, even when they are in different languages, is an important goal in natural language processing (NLP). This problem becomes more complex when the texts are in different languages.
In this paper, the researchers introduce a new dataset called X-PARADE, which contains paragraph-level annotations of information divergences across language pairs. Annotators look at a paragraph in a target language and compare it to a corresponding paragraph in a source language. They indicate whether the information in the target paragraph is the same, new, or new but can be inferred from the source paragraph.
This "inferable" category is particularly interesting, as it connects to the problem of cross-language natural language inference (NLI). The researchers then test various approaches to this task, including techniques that use machine translation, methods that focus on identifying the specific parts of the text that support an inference, and prompting large language models.
The results show that these methods have varying abilities to handle the "inferable" cases, but they all struggle to match human performance on this task. This highlights the challenge of truly understanding the nuances of information conveyed across language barriers.
Technical Explanation
The paper introduces the X-PARADE dataset, which contains paragraph-level annotations of information divergences in cross-lingual text. Annotators are shown a paragraph in a target language and asked to compare it to a corresponding paragraph in a source language. They then label each span of text in the target paragraph as either:
- Same: The information is the same as in the source paragraph.
- New: The information is new and not present in the source paragraph.
- Inferable: The information is new but can be inferred from the source paragraph.
This "inferable" category is particularly interesting, as it establishes a link with the problem of cross-language natural language inference (NLI).
The researchers then investigate several approaches to this task:
- Token Alignment: Aligning tokens between the source and target paragraphs using machine translation techniques.
- Textual Entailment: Using methods that can localize their decisions to specific parts of the text, such as MAINLP at SemEval 2024 Task 1 and AADAM at SemEval 2024 Task 1.
- Prompting LLMs: Leveraging the capabilities of large language models (LLMs) through carefully designed prompts.
The results show that these methods vary in their ability to handle the "inferable" cases, with some performing better than others. However, all of the approaches fall short of human performance on the task, highlighting the challenges in truly understanding the nuances of cross-lingual information divergences.
Critical Analysis
The paper introduces an interesting and important dataset for the NLP community, as understanding cross-lingual information divergences is a key challenge. The authors' decision to include the "inferable" category is particularly insightful, as it connects to the problem of cross-language NLI, which is an area of active research.
However, the paper does not delve deeply into the reasons why the various approaches they tested struggle to match human performance. It would be valuable to explore potential limitations of the methods, such as their ability to capture contextual information or handle more complex linguistic phenomena.
Additionally, the paper could have discussed the potential biases or skewed distributions in the X-PARADE dataset, as these factors can influence the performance of the tested approaches. Exploring ways to address these issues or expand the dataset could be a fruitful direction for future research.
Despite these minor critiques, the paper makes a valuable contribution by introducing a novel dataset and investigating multiple approaches to a challenging cross-lingual NLP problem. The findings serve as a starting point for further research in this area, and the X-PARADE dataset will likely be a valuable resource for the community.
Conclusion
This paper presents X-PARADE, the first cross-lingual dataset of paragraph-level information divergences, and investigates various approaches for this problem, including token alignment, textual entailment methods, and prompting large language models.
The results show that while these methods have varying capabilities in handling "inferable" information, they all fall short of human performance on the task. This highlights the complexities involved in truly understanding the nuances of cross-lingual information divergences, an important problem in natural language processing.
The X-PARADE dataset and the insights gained from this research will likely serve as a valuable resource and starting point for further advancements in this field, as the NLP community continues to push the boundaries of cross-lingual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
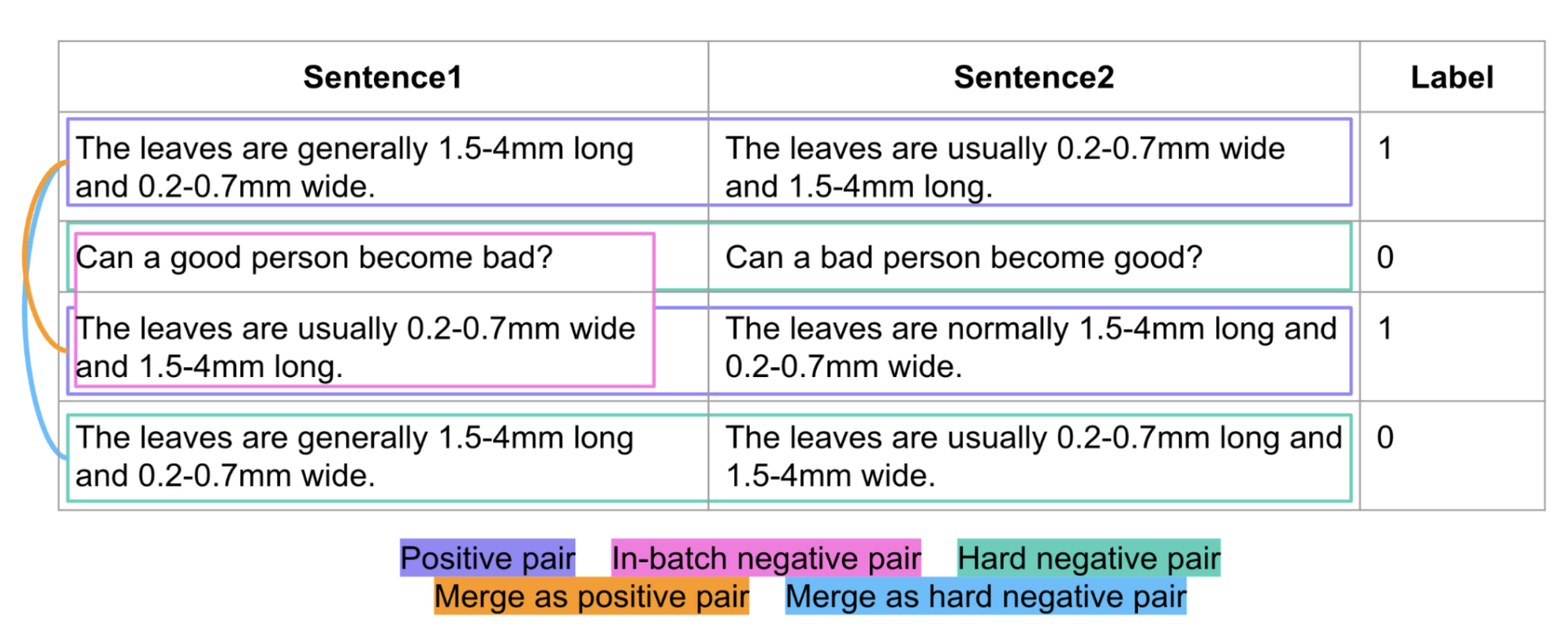
Cross-lingual paraphrase identification
Inessa Fedorova, Aleksei Musatow
0
0
The paraphrase identification task involves measuring semantic similarity between two short sentences. It is a tricky task, and multilingual paraphrase identification is even more challenging. In this work, we train a bi-encoder model in a contrastive manner to detect hard paraphrases across multiple languages. This approach allows us to use model-produced embeddings for various tasks, such as semantic search. We evaluate our model on downstream tasks and also assess embedding space quality. Our performance is comparable to state-of-the-art cross-encoders, with only a minimal relative drop of 7-10% on the chosen dataset, while keeping decent quality of embeddings.
6/24/2024
🤷
Spotting AI's Touch: Identifying LLM-Paraphrased Spans in Text
Yafu Li, Zhilin Wang, Leyang Cui, Wei Bi, Shuming Shi, Yue Zhang
0
0
AI-generated text detection has attracted increasing attention as powerful language models approach human-level generation. Limited work is devoted to detecting (partially) AI-paraphrased texts. However, AI paraphrasing is commonly employed in various application scenarios for text refinement and diversity. To this end, we propose a novel detection framework, paraphrased text span detection (PTD), aiming to identify paraphrased text spans within a text. Different from text-level detection, PTD takes in the full text and assigns each of the sentences with a score indicating the paraphrasing degree. We construct a dedicated dataset, PASTED, for paraphrased text span detection. Both in-distribution and out-of-distribution results demonstrate the effectiveness of PTD models in identifying AI-paraphrased text spans. Statistical and model analysis explains the crucial role of the surrounding context of the paraphrased text spans. Extensive experiments show that PTD models can generalize to versatile paraphrasing prompts and multiple paraphrased text spans. We release our resources at https://github.com/Linzwcs/PASTED.
5/30/2024

Meta4XNLI: A Crosslingual Parallel Corpus for Metaphor Detection and Interpretation
Elisa Sanchez-Bayona, Rodrigo Agerri
0
0
Metaphors, although occasionally unperceived, are ubiquitous in our everyday language. Thus, it is crucial for Language Models to be able to grasp the underlying meaning of this kind of figurative language. In this work, we present Meta4XNLI, a novel parallel dataset for the tasks of metaphor detection and interpretation that contains metaphor annotations in both Spanish and English. We investigate language models' metaphor identification and understanding abilities through a series of monolingual and cross-lingual experiments by leveraging our proposed corpus. In order to comprehend how these non-literal expressions affect models' performance, we look over the results and perform an error analysis. Additionally, parallel data offers many potential opportunities to investigate metaphor transferability between these languages and the impact of translation on the development of multilingual annotated resources.
4/11/2024
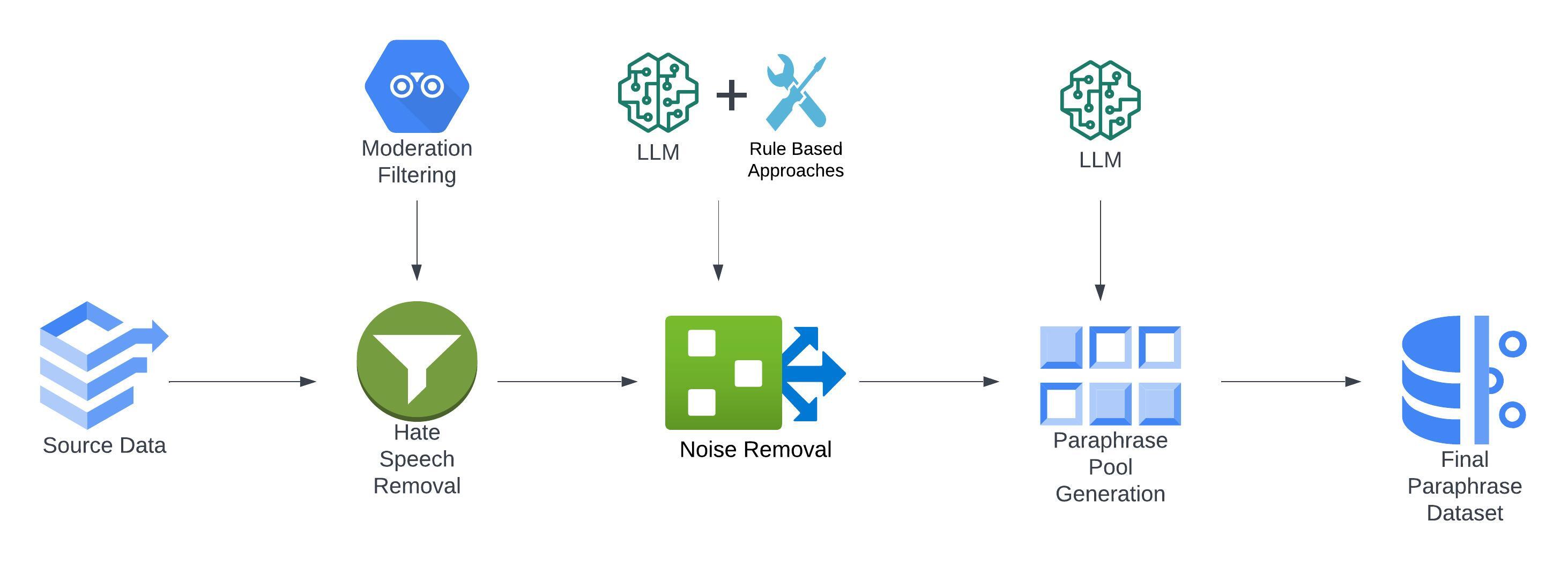
ParaFusion: A Large-Scale LLM-Driven English Paraphrase Dataset Infused with High-Quality Lexical and Syntactic Diversity
Lasal Jayawardena, Prasan Yapa
0
0
Paraphrase generation is a pivotal task in natural language processing (NLP). Existing datasets in the domain lack syntactic and lexical diversity, resulting in paraphrases that closely resemble the source sentences. Moreover, these datasets often contain hate speech and noise, and may unintentionally include non-English language sentences. This research introduces ParaFusion, a large-scale, high-quality English paraphrase dataset developed using Large Language Models (LLM) to address these challenges. ParaFusion augments existing datasets with high-quality data, significantly enhancing both lexical and syntactic diversity while maintaining close semantic similarity. It also mitigates the presence of hate speech and reduces noise, ensuring a cleaner and more focused English dataset. Results show that ParaFusion offers at least a 25% improvement in both syntactic and lexical diversity, measured across several metrics for each data source. The paper also aims to set a gold standard for paraphrase evaluation as it contains one of the most comprehensive evaluation strategies to date. The results underscore the potential of ParaFusion as a valuable resource for improving NLP applications.
4/19/2024